In this initial module…
1> Description of the Cholesky algorithm
2> Running the algorithm on the CPU
Algorithm Description¶
This tutorial is based on a C++ kernel that we’ll optimize for highest throughput.
The algorithm is a common linear algebra solver, the decomposition of a Hermitian, positive-definite matrix into the product of a lower triangular matrix and its conjugate transpose. For this purpose we will use the Cholesky decomposition or Cholesky factorization (pronounced /ʃo-LESS-key/). This solver is useful for several numerical problems, in particular for Monte Carlo simulations.
This algorithm has a serial complexity O(n3).
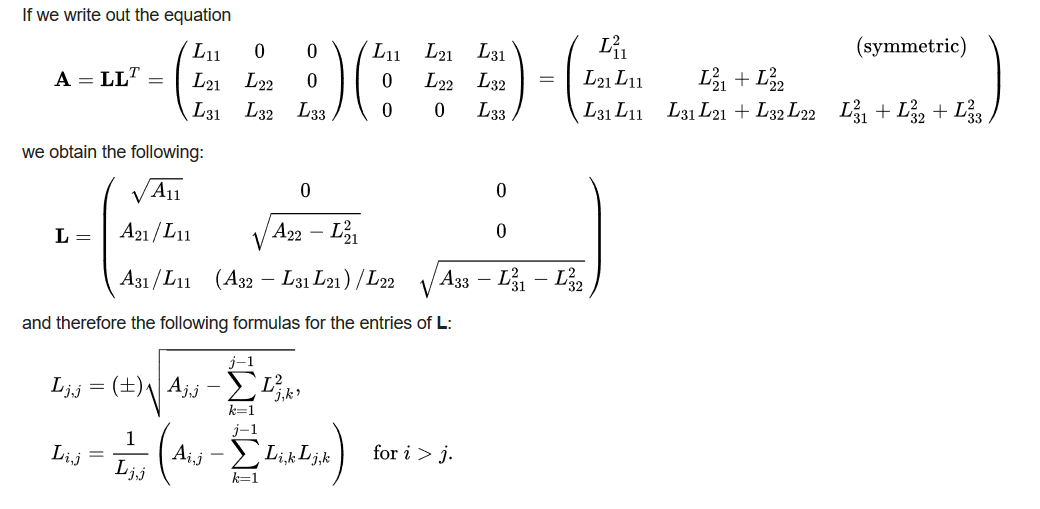
More information on wikipedia… Note that this solver is included as part the official Vitis accelerated libraries, here is a link to its documentation: https://xilinx.github.io/Vitis_Libraries/solver/2020.1/guide_L2/L2_api.html#potrf
For our purpose, we will start with a simple description implemented in C++ and explain how to adapt it for acceleration with an Alveo U50 card.
Run this design on CPU¶
Open a terminal and navigate to the ./docs/cpu_src directory.
Run the following command to compile the design:
g++ cpu_cholesky.cpp test.cpp matrixUtility.hpp -std=c++0x -O3 -o test
./test -M 512 -N 512 -seed 12
Run with different sizes of matrices small and large (maximum size is 2048x2048) to gauge the impact on the execution time. Study the code to check how it implements the Cholesky algorithm.
Note 1: If your server has limited stack size, this program might issue a segmentation fault at values smaller than 2048x2048.
Note 2: On Nimbix servers, fitted with Intel® Xeon® Processor E5-2640 v3 (20M Cache, 2.60 GHz), the algorithm execution time is about 21ms for a 512x512 matrix.