Vitis ハードウェア アクセラレータxilinx.com の Vitis ™開発環境を参照 |
2-D ビデオたたみ込みフィルター用のハードウェア カーネル モジュールの設計と解析¶
この演習では、たたみ込みフィルター モジュールの設計、パフォーマンス解析、およびハードウェア リソース使用率の解析について説明します。ボトムアップ アプローチの後に、まずハードウェア カーネルを開発し、パフォーマンスを解析してから、ホスト アプリケーションと統合します。Vitis HLS を使用して、カーネルのパフォーマンスをビルドして見積もります。
2-D たたみ込みフィルターのインプリメンテーション¶
このセクションでは、たたみ込みフィルターの設計について説明します。最上位の構造、実行された最適化、インプリメンテーションの詳細を確認します。
カーネルの最上位構造¶
たたみ込みフィルターの最上位は、データフロー プロセスを使用してモデル化されます。データフローは、次に示す 4 つの異なる関数で構成されます。インプリメンテーションの詳細は、たたみ込みチュートリアル ディレクトリの src/filter2d_hw.cpp ソース ファイルを参照してください。
void Filter2DKernel(
const char coeffs[256],
float factor,
short bias,
unsigned short width,
unsigned short height,
unsigned short stride,
const unsigned char src[MAX_IMAGE_WIDTH*MAX_IMAGE_HEIGHT],
unsigned char dst[MAX_IMAGE_WIDTH*MAX_IMAGE_HEIGHT])
{
#pragma HLS DATAFLOW
// Stream of pixels from kernel input to filter, and from filter to output
hls::stream<char,2> coefs_stream;
hls::stream<U8,2> pixel_stream;
hls::stream<window,3> window_stream; // Set FIFO depth to 0 to minimize resources
hls::stream<U8,64> output_stream;
// Read image data from global memory over AXI4 MM, and stream pixels out
ReadFromMem(width, height, stride, coeffs, coefs_stream, src, pixel_stream);
// Read incoming pixels and form valid HxV windows
Window2D(width, height, pixel_stream, window_stream);
// Process incoming stream of pixels, and stream pixels out
Filter2D(width, height, factor, bias, coefs_stream, window_stream, output_stream);
// Write an incoming stream of pixels and write them to global memory over AXI4 MM
WriteToMem(width, height, stride, output_stream, dst);
}
データフロー チェーンは、次の 4 つの異なる関数で構成されます。
ReadFromMem: メイン メモリからピクセル データまたはビデオ入力を読み取り
Window2d: 出力側に幅 (15 x 15 ピクセル) のアクセスを持つローカル キャッシュ
Filter2D: コア カーネル フィルタリング アルゴリズム
WriteToMem: 出力データをメイン メモリに書き込み
入力および出力の 2 つの関数がデバイスのグローバル メモリからデータを読み出しおよび書き込みします。ReadFromMem 関数はデータを読み取り、ストリームしてフィルタリングします。チェーンの最後の WriteToMem 関数は、処理されたピクセル データをデバイス メモリに書き込みます。メイン メモリから読み出された入力データ (ピクセル) は Window2D 関数に渡され、ローカル キャッシュが作成されます。また、サイクルごとに、フィルター関数/ブロックに 15 x 15 ピクセルのサンプルを提供します。Filter2D 関数は、1 サイクルで 15 x 15 ピクセルのサンプルを消費して、毎サイクル 225 (15 x 15) の MAC (乗累算) を実行できます。
たたみ込みチュートリアルディレクトリから src/filter2d_hw.cpp ソース ファイルを開き、これらの個々の関数のインプリメンテーションの詳細を確認します。次のセクションでは、Window2D 関数と Filter2D 関数のインプリメンテーションの詳細について説明します。次の図は、異なる関数 (データフローモジュール) 間のデータフローを示しています。

データ ムーバー¶
カスタム デザインのハードウェア アクセラレータ (FPGA に最適) の主な利点の 1 つは、カスタム データ ムーバーの選択とアーキテクチャです。これらのカスタマイズされたデータ ムーバーにより、グローバル デバイス メモリへ効率的にアクセスしやすくなり、データの再利用によって帯域幅の使用率が最適化されます。 メイン メモリとのインタフェースにある専用のデータ ムーバーは、データ プロセッシング エンジンまたはプロセッシング エレメントの入力および出力でビルドできます。たたみ込みフィルターは、この良い例です。純粋なソフトウェア インプリメンテーションの観点から見ると、出力側で 1 つのサンプルを生成するには、入力側で 450 のメモリ アクセスと出力への 1 つの書き込みアクセスが必要になるようです。
Memory Accesses to Read filter Co-efficients = 15x15 = 225
Memory Accesses to Read Neighbouring Pixels = 15x15 = 225
Memory Accesses to Write to Output = 1
Total Memory Accesses = 451
純粋なソフトウェア インプリメンテーションでは、キャッシュによってこれらのアクセスの多くが高速になる可能性があるのに、大量のメモリ アクセスがパフォーマンスのボトルネックになります。ただし、FPGA 上で設計すると、効率的にデータが移動でき、アクセス方式を容易に構築できます。主な利点の 1 つは、大量のオンチップ メモリ帯域幅 (分散メモリおよびブロック メモリ) が使用可能になり、この帯域幅のカスタム コンフィギュレーションを選択できるようになる点です。このカスタム コンフィギュレーションを選択すると、特定のアルゴリズム用にカスタマイズされたオンデマンド キャッシュ アーキテクチャを作成できます。次のセクションでは、Window2D ブロックのデザインについて詳しく説明します。
Window2D: ライン バッファーおよびウィンドウ バッファー¶
Window2D ブロックは基本的に『ライン バッファー』、と『ウィンドウ』。の 2 つの基本ブロックから構築されます。
ライン バッファーは、フル イメージの複数行をバッファーするために使用されます。 具体的には、FILTER_V_SIZE - 1 イメージ ラインをバッファーするように設計されています。FILTER_V_SIZE は、たたみ込みフィルターの高さです。ライン バッファーで保持されるピクセルの合計は (FILTER_V_SIZE-1) * MAX_IMAGE_WIDTH です。
Window ブロックは、FILTER_V_SIZE * FILTER_H_SIZE ピクセルを保持します。2-D たたみ込みフィルタリング操作は、前の演習で説明したように、フィルタリング マスク (フィルター係数) を出力ピクセルのインデックスにセンタリングし、積和 (SOP) を計算します。次の図は、これらのセンタリングおよび SOP 演算の実行方法を示しています。
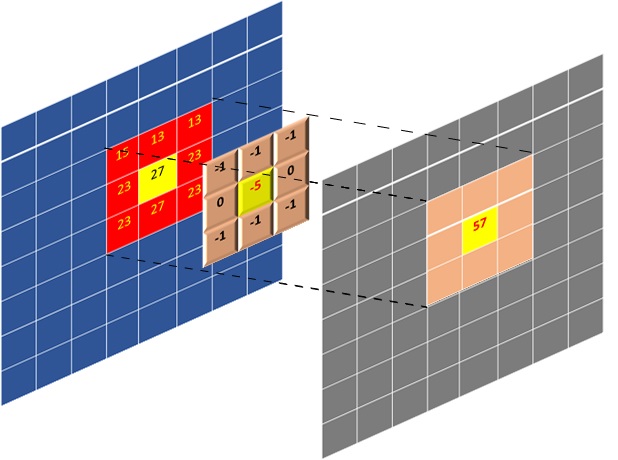
上の図は、処理されるフル イメージに対して実行された SOP を示しています。出力ピクセルが 1 行ずつ生成される場合は、メモリ内のすべての画像ピクセルを表示する必要はありません。フィルタリング マスクのオーバーラップが必要な行のみが必要です。これは、基本的には FILTER_V_SIZE 行であり、FILTER_V_SIZE-1 に縮小することもできます。これは、オンチップにする必要があるデータまたは特定の時点でデータ ムーバーに格納する必要があるデータの量です。
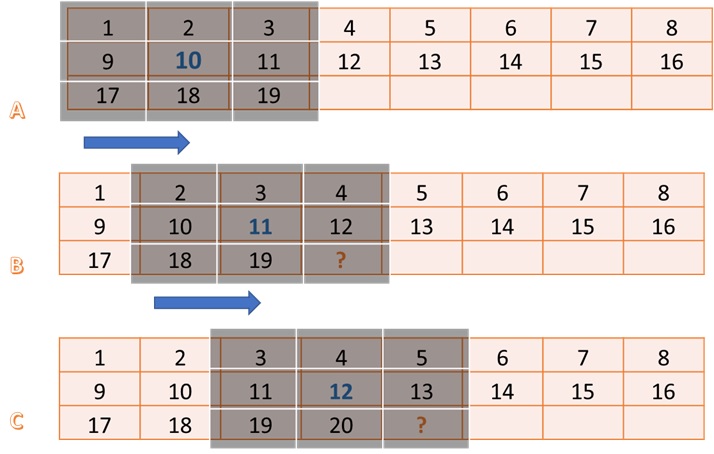
上の図は、ライン バッファーとウィンドウ バッファーの操作と要件を示しています。画像サイズは 8 x 8 で、フィルター サイズは 3 x 3 です。この例では、ピクセル番号 10 のフィルター処理された出力を生成します。この場合、ステップ A に示すように、ピクセル 10 の中心に 3 x 3 の入力ピクセル ブロックが必要です。
図のステップ B では、ピクセル番号 11 を生成するために必要なものがハイライトされています。もう 1 つの 3 x 3 ブロックですが、前の入力ブロックと大幅に重複しています。基本的に、列は左から出て右から入ります。ステップ A、B、および C で注意すべき重要な点の 1 つは、入力側から 1 つの出力ピクセルを生成するのに 1 つの新しいピクセルが必要だという点です (複数のピクセルでライン バッファーを埋める初期レイテンシは無視されます (1 回のみ)。
ライン バッファーには、FILTER_V_SIZE-1 行が保持されます。通常は FILTER_V_SIZE 行が必要ですが、ライン バッファーを循環的に使用し、1 つ目のライン バッファーの先頭のピクセルが不必要なので、それを使用して新しい入力ピクセルを書き込むことができるという事実を利用することで、行は削減します。ウィンドウ バッファーは、ウィンドウ内のエレメントすべてに並列アクセスがあるとすると、完全にパーティションされた FILTER_V_SIZE * FILTER_H_SIZE ストレージとしてインプリメントされます。データは、列ベクターのサイズ FILTER_V_SIZE をライン バッファーからウィンドウ バッファーに移動され、このウィンドウ全体がストリームを通って Filter2D 関数に渡されます。
全体的なスキーム (データ ムーバー) は、データの再利用が最大になるようにビルドされており、最大並列データがプロセッシング エレメントに渡されます。データ ムーバーの記述形式をより理解するには、ソース コード内の Window2D 関数の詳細を確認してください。この関数は、たたみ込みチュートリアル ディレクトリの src/filter2d_hw.cpp ソース ファイルに含まれます。
Vitis HLS を使用使用したカーネルのビルドとシミュレーション¶
このセクションでは、Vitis HLS を使用して 2D たたみ込みフィルターを作成およびシミュレーションします。また、協調シミュレーション後のパフォーマンス見積もりと測定結果も確認し、ターゲット パフォーマンス設定と比較します。
カーネル モジュールのビルド¶
では、メモリへの AXI インターフェイスを使用してカーネル モジュールをスタンドアロン カーネルとしてビルドします。これは、シミュレーションにも使用します。これを実行するには、次の手順に従ってください。
cd $CONV_TUTORIAL_DIR/hls_build
vitis_hls -f build.tcl
ヒント: この手順を完了するには時間がかかる場合があります。
次ような出力が表示されます。
----------------------------------------------------------------------------
HLS Testbench for Xilinx 2D Filter Example
Image info
- Width : 1000
- Height : 30
- Stride : 1024
- Bytes : 30720
Running FPGA accelerator
Comparing results
Test PASSED: Output matches reference
----------------------------------------------------------------------------
INFO: [COSIM 212-1000] *** C/RTL co-simulation finished: PASS ***
これは、幅 = 1000 、高さ = 30 の画像がシミュレーションされているところを示しています。画像寸法にはデフォルトのパラメーターがあり、これらは協調シミュレーションをよりすばやく実行できるように小さな値として保持されます。合成は、最大画像サイズ 1920 x 1080 で実行されます。
ビルドとシミュレーションが完了したら、Vitis HLS GUI を起動して、パフォーマンス見積りレポートとインプリメンテーション QoR を解析します。
vitis_hls -p conv_filter_prj
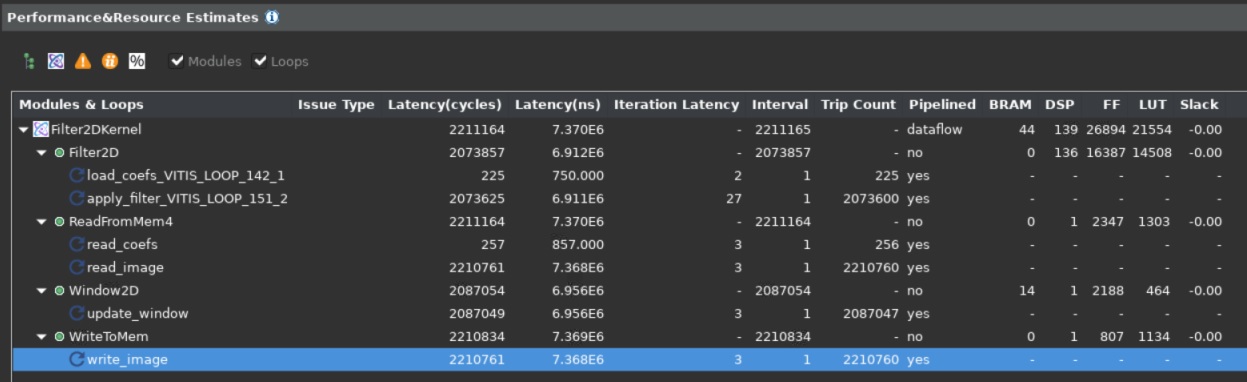
GUI が開いたら、まず次に示すようなパフォーマンスおよびリソース見積もりを示す合成サマリ レポートを確認します。

このレポートは、最上位モジュールによる積和 (SOP) 演算に 139 の DSP が使用され、Window2D データ ムーバー ブロックで 14 の BRAM が使用されることを示しています。
カーネルのスタティック パフォーマンス見積もりが 7.3 ms で、前の演習で計算したカーネルのターゲット レイテンシの見積もりの 6.9 ms にかなり近くなていることがわかります。
カーネルの正確なレイテンシは、協調シミュレーション レポートからもわかります。 Vitis HLS で [Solution] → [Open Report] → [Cosimulation] をクリックし、次のような協調シミュレーション レポートを開きます。

1000 x 30 画像をシミュレーションするので、レイテンシは 30,000 を超える固定レイテンシ (毎出力ピクセル 1 クロック サイクルの場合) になるはずです。レポートに表示されている数値は 38,520 です。ここでは、8,520 が固定レイテンシで、実際の画像サイズが 1920 x 1080 の場合、固定レイテンシはより多くの画像ラインで減っていきます。大きな画像でレイテンシが減っていく事実は、より大きな画像を使用してシミュレーションすると検証できます。
カーネルが毎サイクル スループットで 1 出力サンプルを達成可能かどうかは、ループの開始間隔 (II) でも確認できます。合成レポートの展開ビューには、すべてのループが II=1 であることが表示されます。
スループット要件が満たされ、リソース消費が許容可能であることを確認したら、アプリケーション全体の統合を開始できます。これには、ホスト アプリケーションを作成してコンパイルしてカーネルを駆動し、Alveo データセンター アクセラレータ カード用のザイリンクス プラットフォームの 1 つを使用してカーネルをビルドします。この演習では、Alveo U200 カードを使用します。
この演習では、次のことを学びました。
たたみ込みフィルターの最適化されたインプリメンテーション
Vitis HLS を使用したカーネルのビルドとパフォーマンス解析
次の演習モジュール: 2-D たたみ込みカーネルとホスト アプリケーションのビルド
Copyright© 2021 Xilinx