Vitis ハードウェア アクセラレーションxilinx.com の Vitis ™開発環境を参照 |
元のアプリケーションの概要¶
ドキュメントのフィルター処理は、システムが入力ドキュメントのストリームを監視し、内容に基づいて分類し、特定のユーザーまたはトピックに関連するドキュメントを選択するプロセスです。ドキュメントのフィルター処理は、関連ドキュメントを特定するため、情報の検索、取得、解析に日常的に広く利用されています。
実際には、1 つのイベントで検索されるドキュメントの数は非常に多く、イベントをリアルタイムで監視する必要があるので、すべてのドキュメントを短時間で処理する必要があります。このチュートリアルでは、各ドキュメントの関連性を表すスコアを計算します。
ユーザーの関心度は検索配列で表されます。この配列には、ユーザーが関心を持つワードが含まれ、関心度を表す重みが関連付けられています。ドキュメントの入力ストリームを監視しながら、データベースに格納されているワードに関連付けられた重みを検索する必要があります。ネイティブ インプリメンテーションでは、ドキュメント内のすべてのワードに対してデータベースが照会されてワードがデータベース内にあるかが確認され、あればその重みが取得されます。キャッシュで空間効率のよいブルーム フィルターを使用すると、このプロセスを最適化できます。この方法では、データベースにワードがあるかをレポートできるので、データベース照会回数を減らすことができます。
ブルーム フィルターは、ハッシュ テーブル ベースのデータ構造を使用して、データセットに要素があるかどうかを判断します。誤検知の可能性はありますが、検知漏れは発生しません。つまり、セット内に存在する可能性があるか、セット内には確実に存在しないかがわかります。ブルーム フィルターを使用する利点は、空間効率がよいことと、データベースに存在しないデータの照会回数が大幅に削減されることです。ブルーム フィルターは、検索エンジンおよび Cassandra や Postgres などのデータベース管理システムをインプリメントするアプリケーションでも、照会回数を削減してパフォーマンスを向上できるので有益です。
次の図に、セット {x, y, z} を表すブルーム フィルターの例を示します。
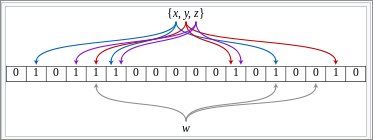
色付きの矢印は、セットの各要素がマップされているビット配列の位置を示します。
要素
wは、0 を含む 1 ビット配列位置にハッシュしているので、セット{x, y, z}には含まれません。要素数は 18 で、各要素に対して計算されるハッシュ関数の数は 3 です。
チュートリアルのインプリメンテーション¶
このチュートリアルでは、各ドキュメントがワードの配列で構成されており、各ワードは 32 ビットの符号なし整数 (24 ビットのワード ID と頻度を表す 8 ビット) です。検索配列はユーザーが関心を持つワードで構成されており、24 ビットのワード ID のセットを表します。各ワード ID には、ワードの重要性を表す重みが関連付けられています。
Hardware_Acceleration/Design_Tutorials/02-bloomディレクトリに移動します。cpu_srcディレクトリに移動し、main.cppファイルを開き、63 行目を確認します。ブルーム フィルターのアプリケーションは 64 KB で、
1L<<bloom_sizeとしてインプリメントされます。bloom_sizeはsizes.hヘッダー ファイルで 14 と定義されます ((2^14)*4B = 64 KBと計算されます)。各ドキュメントのスコアは、ワード ID の重みと頻度を掛け合わせた累積積で算出されます。スコアが大きいほど、検索配列と一致し、ドキュメントの関連性が高いということになります。