Vitis ハードウェア アクセラレーションxilinx.com の Vitis ™開発環境を参照 |
デバイス アクセラレーション アプリケーションの構築¶
この演習では、元の C コードの関数およびループを評価し、どの関数を FPGA アクセラレーションのターゲットとするかを判断します。実際にツールを実行する前に、コード、ループ構造、およびアクセス パターンを手動で確認する必要があります。
FPGA でアクセラレーションする関数の特定¶
02-bloom/cpu_src ディレクトリの main 関数は、runOnCPU 関数を呼び出します。この関数は、02-bloom/cpu_src/compute_score_host.cpp ファイルにインプリメントされています。
このアルゴリズムは、次の 2 つのセクションに分けられます。
すべてのドキュメントに含まれる各ワードのハッシュ関数から作成された出力フラグを計算。
作成された出力フラグに基づいてドキュメント スコアを計算。
これらのセクションのどちらが FPGA で実行するのに適しているかを評価します。
MurmurHash2 関数の評価¶
元のアプリケーション コードを含む
$LAB_WORK_DIR/cpu_srcディレクトリに移動します。ファイル エディターで
MurmurHash2.cファイルを開きます。次の
MurmurHash2ハッシュ関数コードを確認します。unsigned int MurmurHash2 ( const void * key, int len, unsigned int seed ) { const unsigned int m = 0x5bd1e995; // Initialize the hash to a 'random' value unsigned int h = seed ^ len; // Mix 4 bytes at a time into the hash const unsigned char * data = (const unsigned char *)key; switch(len) { case 3: h ^= data[2] << 16; case 2: h ^= data[1] << 8; case 1: h ^= data[0]; h *= m; }; // Do a few final mixes of the hash to ensure the last few // bytes are well-incorporated. h ^= h >> 13; h *= m; h ^= h >> 15; return h; }
計算の複雑性は、関数を実行するのに必要な基本的な演算の数です。
1 つのワード ID のハッシュは、XOR、3 つの演算シフト、および 2 つの乗算を使用して計算されます。
演算シフトの 1 ビットのシフトには、CPU の 1 クロック サイクルかかります。
3 つの演算シフトで合計 44 ビットがシフトされるので (上記のコードで
len=3の場合)、ハッシュの計算でビットをホスト CPU にシフトするためだけに 44 クロック サイクル必要です。FPGA ではカスタム アーキテクチャを作成できるので、1 つのクロック サイクルで任意の数のビットをシフトするアクセラレータを作成できます。
FPGA には、乗算を CPU よりも高速に実行する専用 DSP ユニットも含まれます。CPU は FPGA の 8 倍の周波数で動作しますが、FPGA はカスタマイズ可能なハードウェア アーキテクチャなので、演算シフトおよび乗算を CPU よりも高速に実行できます。
この関数は、FPGA アクセラレーションのよい候補です。
runOnCPU 関数の最初の for ループ (ハッシュ関数) を評価¶
ファイル エディターで
compute_score_host.cppファイルを開きます。次に示す出力フラグを計算する 32 ~ 58 行目のコードを確認します。
// Compute output flags based on hash function output for the words in all documents for(unsigned int doc=0;doc<total_num_docs;doc++) { profile_score[doc] = 0.0; unsigned int size = doc_sizes[doc]; for (unsigned i = 0; i < size ; i++) { unsigned curr_entry = input_doc_words[size_offset+i]; unsigned word_id = curr_entry >> 8; unsigned hash_pu = MurmurHash2( &word_id , 3,1); unsigned hash_lu = MurmurHash2( &word_id , 3,5); bool doc_end = (word_id==docTag); unsigned hash1 = hash_pu&hash_bloom; bool inh1 = (!doc_end) && (bloom_filter[ hash1 >> 5 ] & ( 1 << (hash1 & 0x1f))); unsigned hash2 = (hash_pu+hash_lu)&hash_bloom; bool inh2 = (!doc_end) && (bloom_filter[ hash2 >> 5 ] & ( 1 << (hash2 & 0x1f))); if (inh1 && inh2) { inh_flags[size_offset+i]=1; } else { inh_flags[size_offset+i]=0; } } size_offset+=size; }
このコードから、次のことがわかります。
すべてのドキュメントに含まれる各ワードに対して 2 つのハッシュ出力を計算し、それに応じて出力フラグを作成します。
ハッシュ関数 (
MurmurHash2()) が FPGA でアクセラレーションするよい候補であると既に判断しています。1 つのワードのハッシュ関数 (
MurmurHash2()) はほかのワードから独立しているので、並列実行して実行時間を短縮できます。アルゴリズムは、
input_doc_words配列に順次アクセスします。これは重要な特性です。FPGA にインプリメントすると、DDR に効率よくアクセスできます。
ハッシュ関数は FPGA での方が高速に実行できるので、FPGA アクセラレーションに適しています。DDR からバースト モードで複数のワードを読み出し、複数のワードのハッシュを並列に計算できます。
次に、2 番目のループを確認します。
ファイル エディターで
compute_score_host.cppを開いたままにしておきます。
runOnCPU 関数の 2 番目のループ (スコア計算機能) を評価¶
次に示すドキュメント スコアを計算するコードを確認します。
for(unsigned int doc=0, n=0; doc<total_num_docs;doc++) { profile_score[doc] = 0.0; unsigned int size = doc_sizes[doc]; for (unsigned i = 0; i < size ; i++,n++) { if (inh_flags[n]) { unsigned curr_entry = input_doc_words[n]; unsigned frequency = curr_entry & 0x00ff; unsigned word_id = curr_entry >> 8; profile_score[doc]+= profile_weights[word_id] * (unsigned long)frequency; } } }
スコアの計算には、
profile_weightsへのメモリ アクセスが 1 回、累算が 1 回、乗算が 1 回必要です。メモリ アクセスは、
word_idおよび各ドキュメントの内容によるので、ランダムです。profile_weights配列のサイズは 128 MB で、FPGA に接続されている DDR メモリに格納されています。DDR へのアクセスが順次でないと、それがパフォーマンスのボトルネックになります。profile_weights配列へのアクセスはランダムなので、この関数を FPGA をインプリメントしてもパフォーマンスはそれほど向上しません。また、この関数の実行時間は全体の約 11% なので、この関数はそのままホスト CPU で実行することにします。この解析から、FPGA でアクセラレーションすると効果が出るのは、ハッシュ セクションの出力フラグの計算のみです。ドキュメント スコアの計算は、そのままホスト CPU で実行します。
ファイル エディターを閉じます。
アプリケーション全体に対する現実的な目標の確立¶
スコアの計算関数は、CPU で計算します。前の演算の結果から、これには約 380 ms かかります。この関数を指定の CPU でこれ以上アクセラレーションすることはできません。FPGA でハッシュ関数を 0 時間で計算できても、アプリケーションの実行には最低 380 ms かかりますし、FPGA を 0 時間で実行するというのも非現実的です。また、CPU から FPGA にデータを送信する時間、FPGA から CPU に計算結果を戻す時間も考慮する必要があります。
ハードウェアでのハッシュ計算関数が CPU でのスコアの計算と同等の速度で実行され、ハッシュ関数がボトルネックにならないように、アプリケーションの目標を設定します。
計算には、100,000 個の入力ドキュメントを使用します。各ドキュメントに約 3,500 ワード含まれるとすると、これは約 3.5 億ワードに相当します。
ハッシュ関数の計算のみを FPGA で実行します。ソフトウェアでは、この関数に約 2569 ms かかります。
ハッシュを計算し、10,000 個のドキュメントの全体的なスコアを計算するのを約 380 ms で実行することを、アプリケーションの目標とします。
達成可能な最大スループットの判断¶
ほとんどの FPGA アクセラレーション システムでは、達成可能な最大スループットは PCIe® バスのパフォーマンスの制限を受けます。PCIe バスのパフォーマンスは、マザーボード、ドライバー、ターゲット シェル、転送サイズなどのさまざまな要因に左右されます。Vitis コア開発キットには、xbutil というユーティリティが含まれています。
xbutil validate コマンドを実行して、達成可能な最大 PCIe 帯域幅を計測します。デザイン ターゲットのスループットがこの上限を超えることはできません。
xbutil validate コマンドを実行すると、次の出力が表示されます。
Host -> PCIe -> FPGA write bandwidth = 8485.43 MB/s
Host <- PCIe <- FPGA read bandwidth = 12164.4 MB/s
Data Validity & DMA Test on bank1
Host -> PCIe -> FPGA write bandwidth = 9566.47 MB/s
Host <- PCIe <- FPGA read bandwidth = 12155.7 MB/s
Data Validity & DMA Test on bank2
Host -> PCIe -> FPGA write bandwidth = 8562.48 MB/s
Host <- PCIe <- FPGA read bandwidth = 12154.5 MB/s
PCIe の FPGA 書き込み帯域幅は約 9 GB/s、FPGA 読み出し帯域幅は約 12 GB/s です。PCIe の帯域幅は、設定した目標を 3.1 GB/s 上回ります。
FPGA アプリケーションの並列実行の特定¶
ソフトウェアでは、フローは次の図ようになります。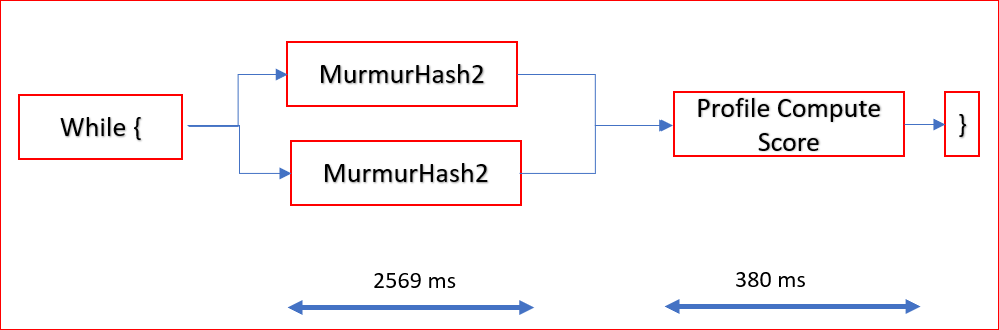
Murmurhash2関数はすべてのワードに対して前もって計算され、出力フラグはローカル メモリに設定されます。ハッシュ計算関数の各ループは、順次実行されます。すべてのハッシュが計算された後にのみ、すべてのドキュメントに対して別のループが呼び出され、スコアが計算されます。
FPGA でアプリケーションを実行する際、データをホストからデバイス メモリに転送し、結果を戻すために追加の遅延が発生します。アプリケーションの全体的な時間を分割し、次の要件に従ってバジェット ベースの実行を作成します。
サイズ 1400 MB のドキュメント データをホスト アプリケーションからデバイス DDR に PCIe を使用して転送します。約 9 GBps の PCIe 書き込み帯域幅を使用すると、転送時間の概算は 1400 MB/9.5 GBps = 約 147 ms になります。
FPGA 上でハッシュを計算します。
サイズ 350 MB のフラグ データをデバイスからホストに PCIe を使用して転送します。約 12 GBps の PCIe 読み出し帯域幅を使用すると、転送時間の概算は 350 MB/12G = 約 30 ms になります。
FPGA からすべてのフラグが転送された後にスコアを計算します。これには、CPU で約 380 ms かかります。
アプリケーションのターゲットは 380 ms ですが、1470 ms + 30 ms + 380 ms を加算すると 100,000 個のドキュメントの計算目標である 380 ms を超えており、また FPGA でハッシュを計算する時間は考慮されていません。ただし、CPU とは異なり、FPGA では並列処理が可能です。FPGA での計算がボトルネックにならないように、FPGA でのハッシュの計算をアクセラレータ用に構築し、最高のパフォーマンスで実行できるようにする必要もあります。
手順 1 ~ 4 を CPU のように順次実行した場合、パフォーマンス目標を達成することはできません。FPGA の並列処理およびオーバーラップを利用する必要があります。
ホストからデバイスへのデータ転送と FPGA での計算を並列実行します。100,000 個のドキュメントを複数のバッファーに分割してデバイスに転送し、カーネルがバッファー全体が転送されるのを待つ必要がないようにします。
FPGA での計算と CPU でのスコアの計算を並列実行します。
並列処理するワード数を増やし、ハッシュ計算の同時処理を増加します。CPU でのハッシュ計算は、32 ビット ワードに対して実行されます。ハッシュの計算は複数のワードで個別に実行できるので、4 個、8 個、16 個のワードを並列処理してみます。
先ほどの解析から、Murmurhash2 関数は FPGA で実行するよい候補で、スコアの計算はホストで実行できます。FPGA 上のハードウェア関数は、前の演習で決定した目標に基づき、各クロック サイクルで複数のワードを処理することによりできるだけ高速にハッシュを計算する必要があります。
アプリケーションは、概念的には次の図のようになります。
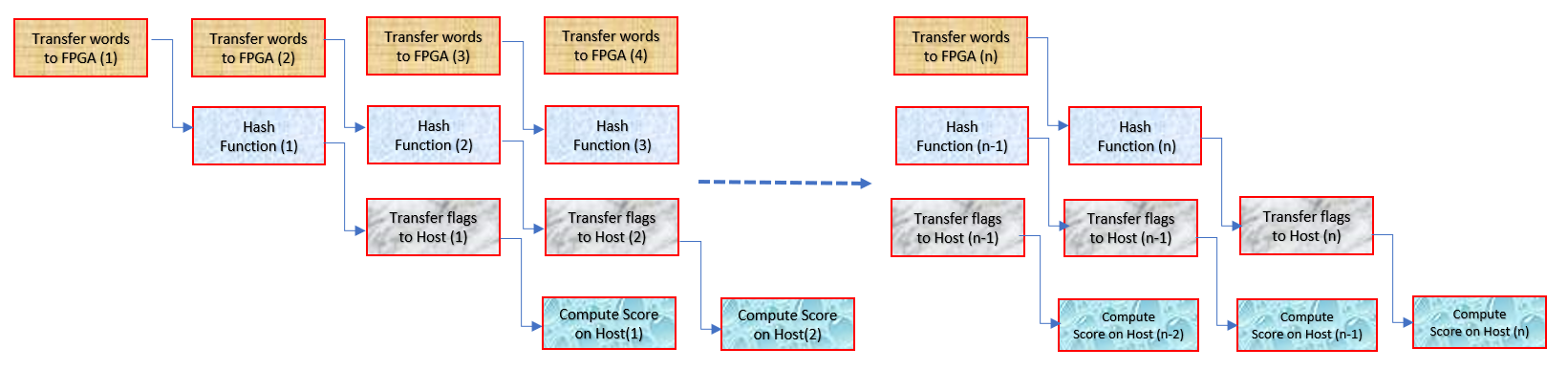
ホスト CPU から FPGA へのワード転送、FPGA での計算、FPGA から CPU へのワード転送は、並列実行できます。CPU は、フラグが受信されたらすぐにスコアの計算を開始します。つまり、CPU でのスコア計算は並列に実行できます。上記のようなパイプライン処理により、FPGA での計算のレイテンシはないに等しくなります。
次の手順¶
この演習では、アプリケーションをプロファイリングし、FPGA でのアクセラレーションに適した部分を特定しました。また、アクセラレーションの目標を達成するために最適化されたカーネルを作成する準備をしました。次の演習では、次の手順を実行します。
カーネルのインプリメント: 4 個、8 個、および 16 個のワードを並列処理する最適化されたカーネルを作成し、ホストからカーネルに 100,000 個のドキュメントすべて (1.4 GB) を 1 つのバッチで送信します。
ホストとカーネル間のデータの動きを解析: ホストとカーネル間のデータの動きを解析: 100,000 個のドキュメントを複数のバッチで送信し、アプリケーションのパフォーマンスが最適化されるようカーネルでの計算とホスト データの転送をオーバーラップさせます。
Murmurhash2関数を FPGA 上に、スコア計算関数を CPU 上に保持して順次モードで処理し、結果を解析します。その後、アクセラレータで作成されたフラグのホストへの送信も、ホストからのデータ転送と FPGA での計算とオーバーラップさせます。複数 DDR バンクの使用: 複数 DDR バンクの使用: 複数の DDR バンクを使用して、アプリケーションのパフォーマンスを向上できるかどうかを調べます。DDR バンクには、ホストおよびカーネルから同時にアクセスします。
次のセクションでは、C/C++ カーネルの開発手法を適用してカーネルをインプリメントし、カーネル仕様の要件を満たす最適化されたカーネルを作成します。
Copyright© 2021 Xilinx