AI Engine DevelopmentSee Vitis™ Development Environment on xilinx.com See Vitis™ AI Development Environment on xilinx.com |
Super Sampling Rate FIR Filters: Implementation on the AI Engine¶
Version: Vitis 2022.1
Introduction¶
Versal® ACAP AI Core Series are heterogeneous devices containing many domains with compute capabilities. With respect to Digital Signal Processing (DSP), and particularly Finite Impulse Response (FIR) filters, the two domains of interest are:
The Programmable Logic (PL) which is the “classical” domain of Xilinx devices
The AI Engine Processor Array which is a new domain within Versal ACAP Xilinx devices
FIR filter architecture is a rich and fruitful electrical engineering domain, especially when the input sampling rate becomes higher than the clock rate of the device (Super Sampling Rate aka. SSR). For the PL there exists a number of solutions that are already available using turnkey IP solution (FIR Compiler). The AI Engine array is a completely new processor and processor array architecture with enormous compute capabilities, so an efficient filtering architecture has to be found using all the capabilities of the AI Engine array, but also all the communications that are possible with the PL.
The purpose of this tutorial is to provide a methodology to enable you to make appropriate choices depending on the filter characteristics, and to provide examples on how to implement Super Sampling Rate (SSR) FIR Filters on a Versal ACAP AI Engine processor array.
Before You Begin¶
Before beginning this tutorial you should be familiar with Versal ACAP architecture and more specifically on the AI Engine array processor and interconnect architecture.
Software requirements include:
You also have the possibility to test these architectures on the AI Engine using MATLAB Simulink toolset.
Mathworks to install MATLAB version R2021a or R2021b.
Vitis Model Composer that is available with the usual install of Vitis.
Before starting this tutorial, run the following step:
Set up your
PLATFORM_REPO_PATHSenvironment variable based upon where you downloaded the platform.
Accessing the Tutorial Reference Files¶
To access the reference files, type the following into a terminal:
git clone https://github.com/Xilinx/Vitis-Tutorials.git.Navigate to the
Vitis-Tutorials/AI_Engine_Development/Design_Tutorials/02-super_sampling_rate_fir/directory, and typesource addon_setup.shto update the path for Python libraries and executable.
You can now start the tutorial.
Summary of AI Engine Architecture¶
You should have already read the AI Engine Detailed Architecture, so the purpose of this chapter is simply to highlight the features of the AI Engine that will be useful for this tutorial.
Versal® Adaptive Compute Acceleration Platforms (ACAPs) combine Scalar Engines, Adaptable Engines, and Intelligent Engines with leading-edge memory and interfacing technologies to deliver powerful heterogeneous acceleration for any application.
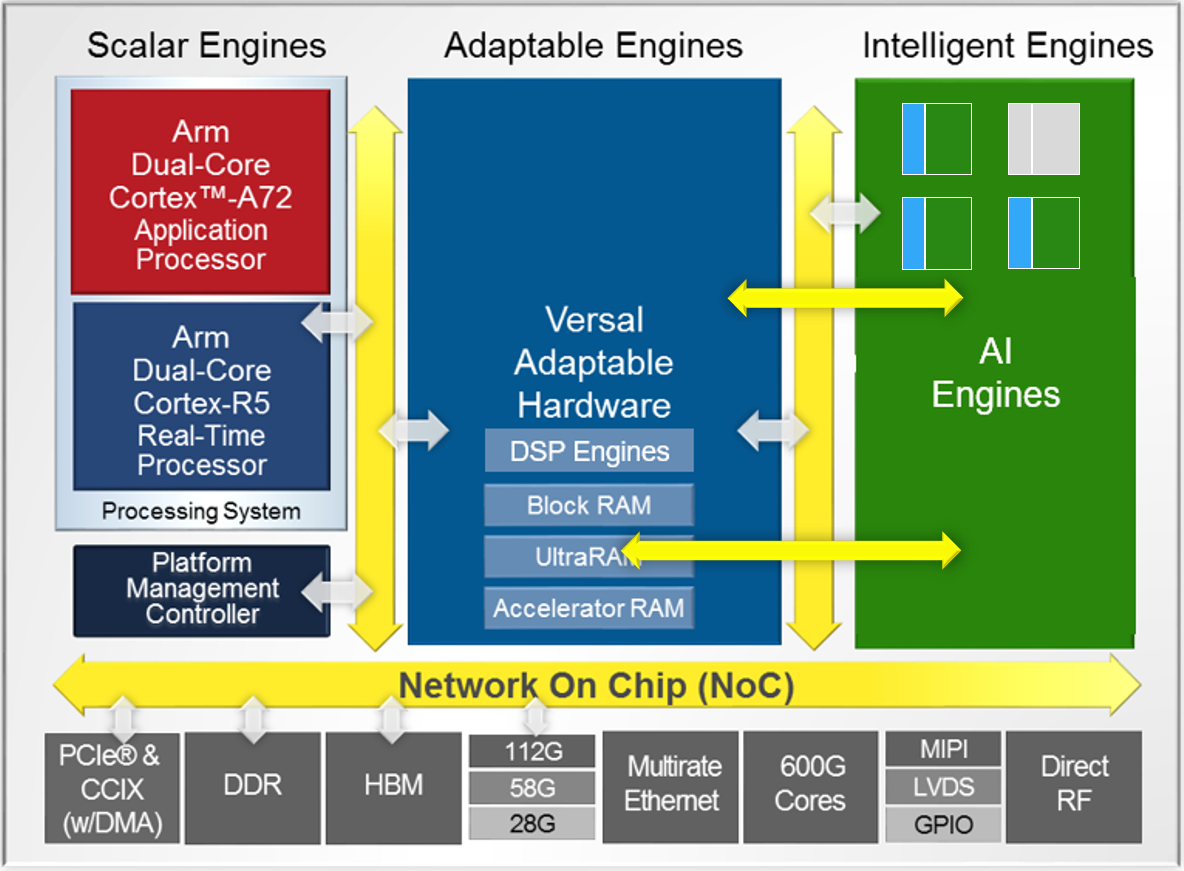
Intelligent Engines are SIMD VLIW AI Engines for adaptive inference and advanced signal processing compute.
DSP Engines are for fixed point, floating point, and complex MAC operations.
The SIMD VLIW AI Engines come as an array of interconnected processors using AXI-Stream interconnect blocks as shown in the following figure:
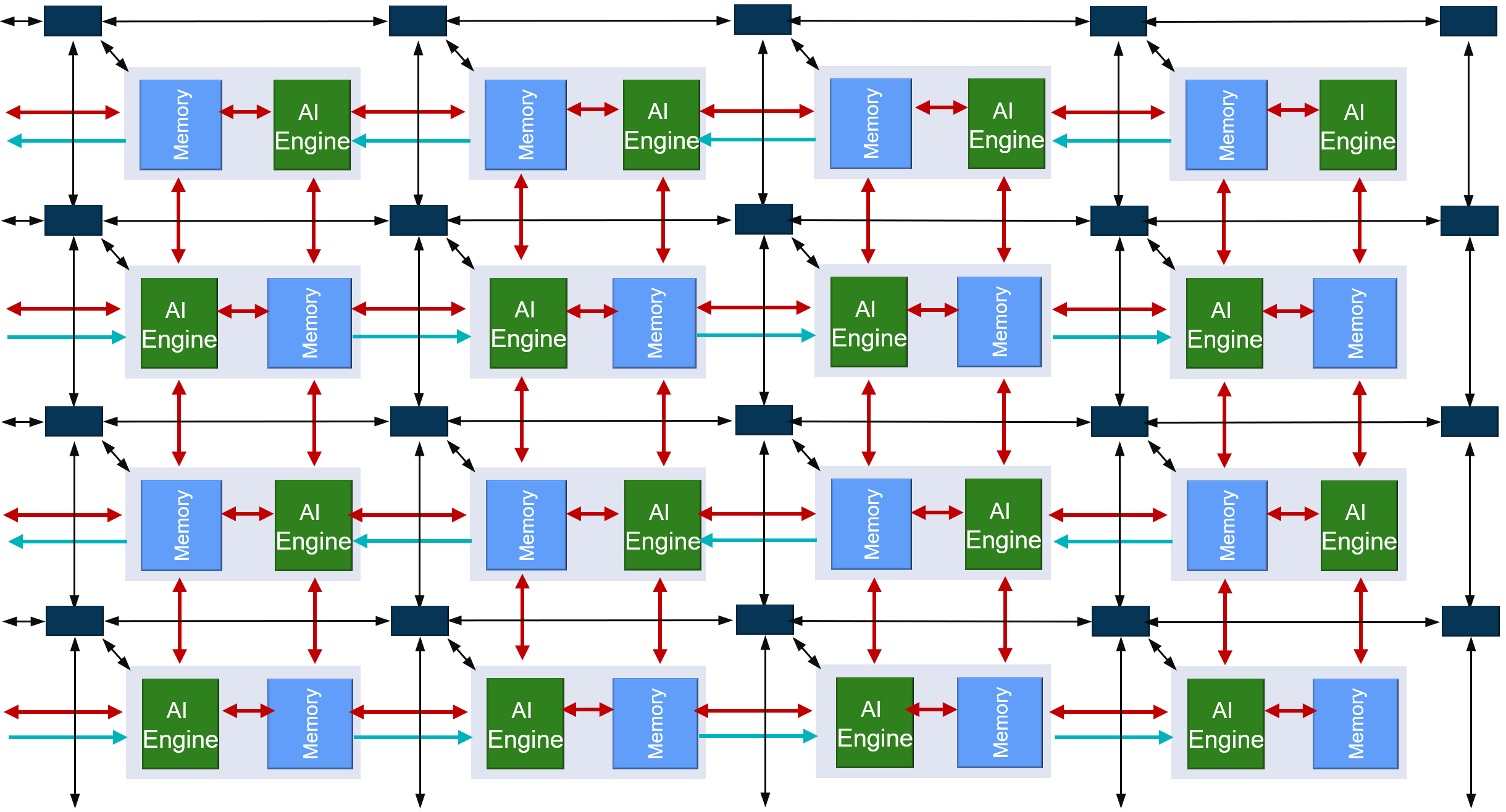
All arrays (processors, memory modules, AXI interconnects) are driven by a single clock. The slowest speed grade device can run @1 GHz. The highest speedgrade will allow 1.3 GHz clock rates. The AI Engine allows for numerous connection possibilities with the surrounding environment as shown in the following figure.
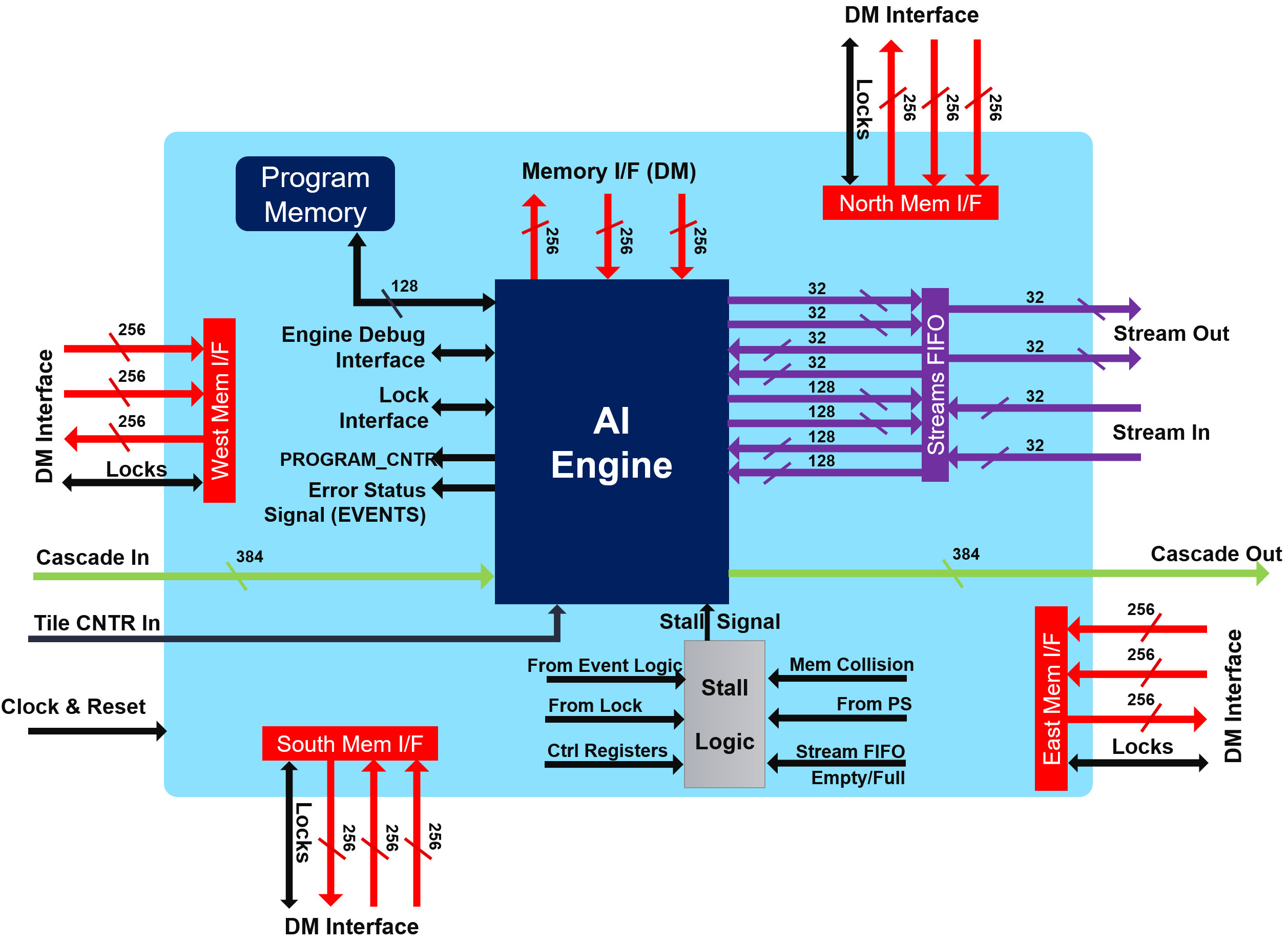
Memory interface¶
Each AI Engine is surrounded by 4x 32 kB memories, each one being divided in four pairs of banks. The bandwidth is very high:
2 reads / cycle on 32 bytes (256 bits) each
Each bank having a single port, the accesses must be done on different banks to achieve 2x 256 bits/cycle.
1 write / cycle on 32 bytes (256 bits)
On another bank to achieve the highest bandwidth
Be aware that you need also to feed the memories using DMAs or other AI Engines
Streaming interface¶
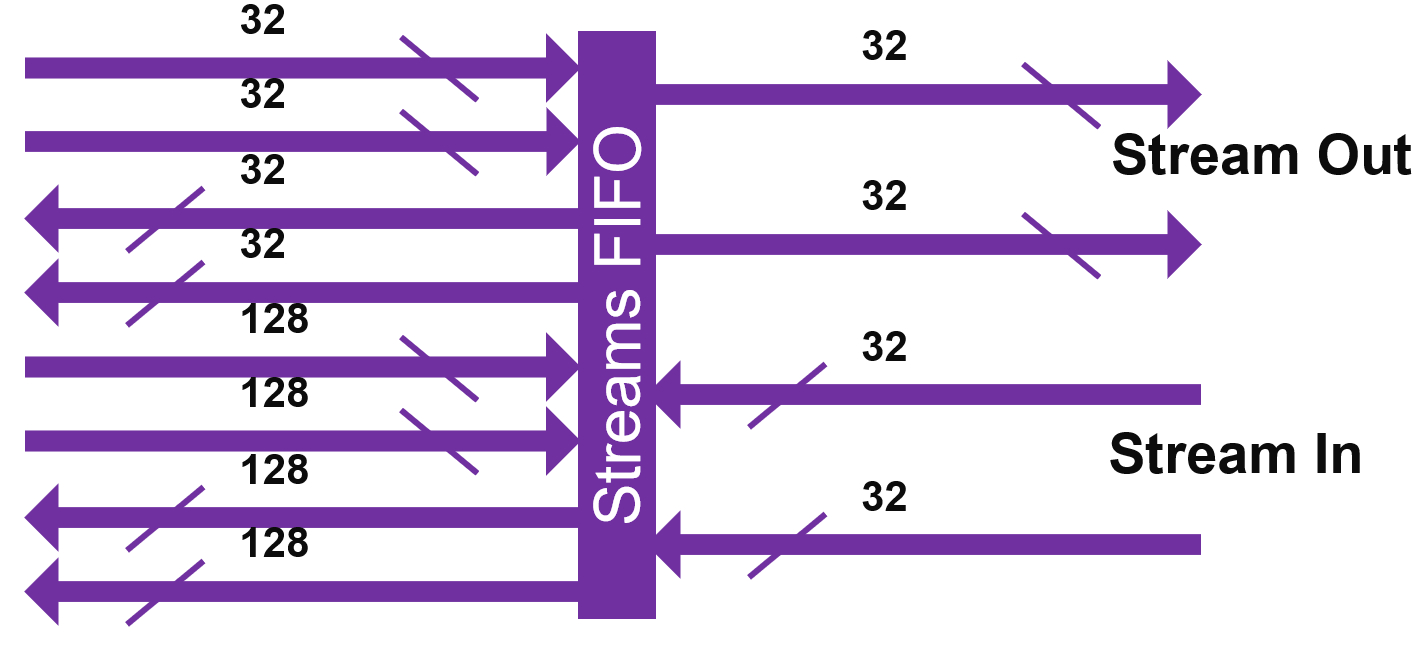
The streaming interface is based on two incoming streams and two outgoing streams, each one on 32 bits per clock cycle. These four streams are handled by a stream FIFO that allows the processor to use different bitwidths to access these streams:
2 streams in, 2 streams out
Each one 4 bytes/cycle or 16 bytes/ 4 cycles
Parallel access to streams per VLIW:
2 reads (4/16 bytes), 1 write (4/16 bytes)
OR 1 read (4/16 bytes), 2 writes (4/16 bytes)
Using 1 stream:
4 bytes/cycle read and 4 bytes/cycle write
Using the 2 streams and the 16-byte access option
Reads and/or writes can be dispatched over time
On average 8 bytes/cycle read and 8 bytes/cycle write
Accessing the data to/from the streams using the 128 bit interface does not increase the bandwidth, but limits the number of accesses that must be scheduled within the microcode of the VLIW processor.
Cascade Streams¶
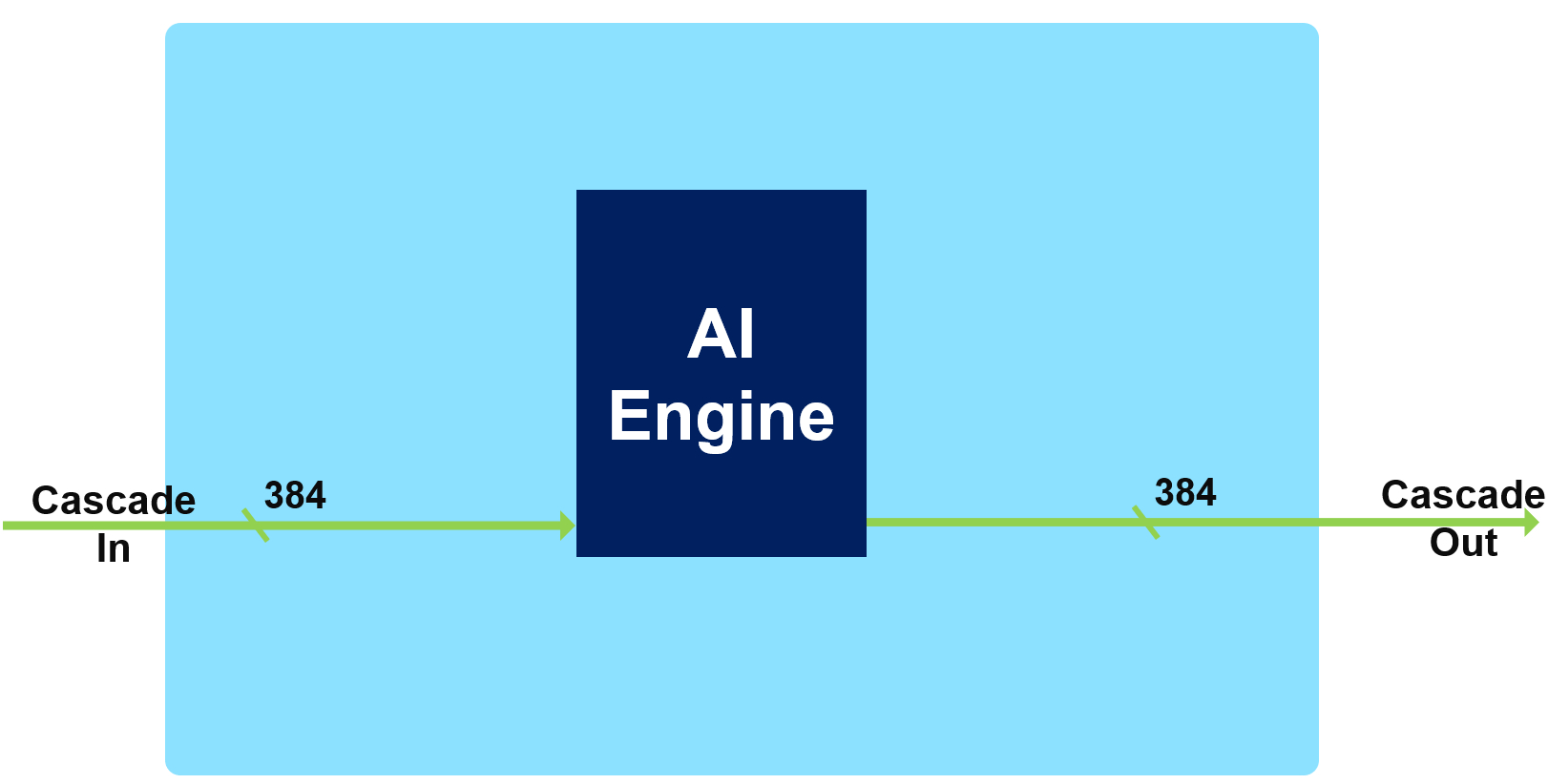
The cascade stream allows an AI Engine processor to transfer the value of some of its accumulator register (384 bits) to its neighbor (on the left or on the right depending on the row):
It is capable of 8x 48-bit word transfer v8acc48 or v4cacc48 in a single cycle
48 bits is the number of bits of the result of a 16-bits x 16-bits multiplication
If the transfer concerns a 768 bit register, it will take 2 clock cycles.
What is a FIR Filter?¶
The purpose of this tutorial is not to train you to be an expert in Digital Signal Processing, however to grasp the basics of FIR filtering it is necessary to understand the computations that are required, and the data that are consumed and produced by the compute block.
A digital signal is an analog signal (audio, radio frequencies, …) that has been received by a converter (Analog to Digital Converter: ADC) which performs two operations:
Slicing: The impinging signal is sliced into very small time slots on which its amplitude is approximated by a constant value.
Quantizing: Digital systems understand only bits. The constant value at the output of the slicer is transformed into an integer value whose maximum represents the maximum amplitude that the system can receive.
As a result the digital signal at the output of the ADC is simply a series of N-bits values (called samples) that can be processed to extract some useful information. The most basic operation is to multiply some samples by some specific coefficients and accumulate these values to create a “summary” of this part of the signal.
A filtering operation performs this using a sliding window on the signal as shown in the following figure:
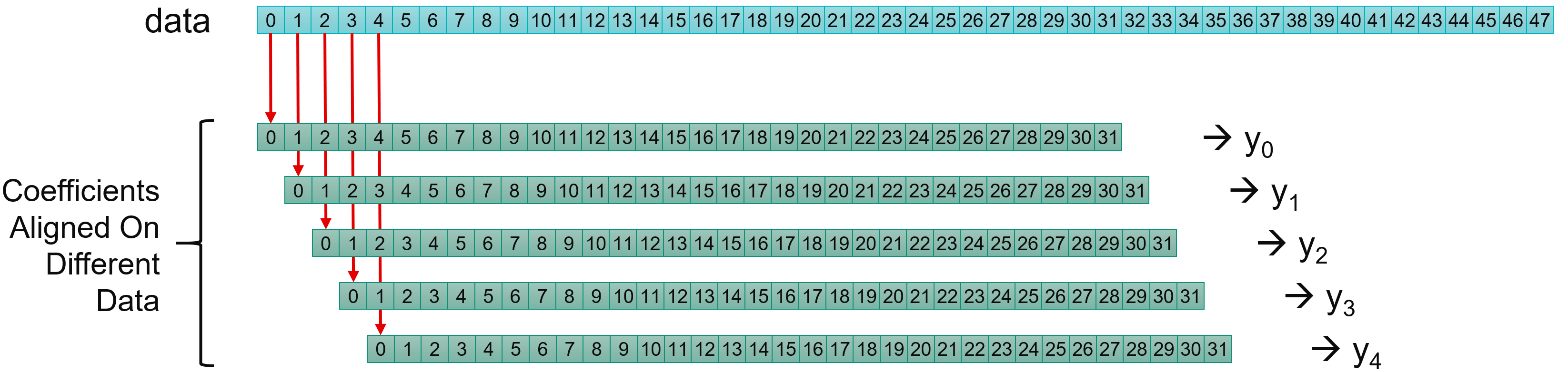
Input data samples are in general called x (blue squares), the coefficients c (green squares) and the output samples y:
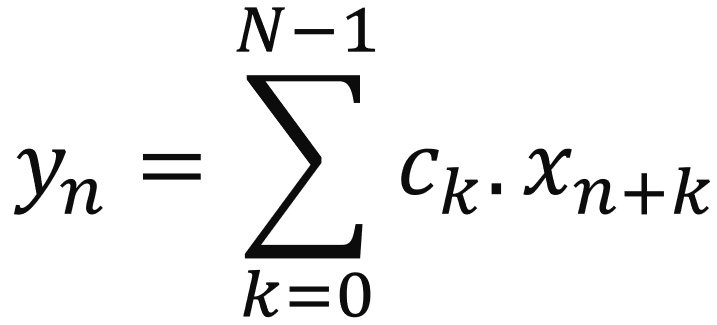
DSP experts may say that this equation represents a correlation and not a convolution which is the mathematical expression of the filtering operation. The easy answer may be to say that it is simply a question of coefficients ordering (and perhaps conjugation for complex coefficients).
That’s why you will always see at the beginning of the various graph.h files the 2 lines:
std::vector<cint16> taps = std::vector<cint16>({
...
});
std::vector<cint16> taps_aie(taps.rbegin(),taps.rend());
The first line is the taps vector definition in the correct order for a DSP expert, and the second line defines the vector that will be used in the AI Engine implementation as the same vector but in the reverse order.
“Utils” Directory¶
For this tutorial a number of utilities have been created that you are free to reuse for your own purposes.
First, to allow these utilities to be called from anywhere during this tutorial you need to add this directory in your PATH but also indicate to python that this directory contains some libraries and should be checked during imports.
Navigate to the Utils directory, and type source InitPythonPath to have this directory in your path for Python libraries and executable search path.
GenerateStreams¶
This utility will use a library GenerationLib.py to generate input data suitable for the cases you want to test. It is called by typing: GenerateStreamsGUI. This displays a GUI in which you can select the appropriate parameters to generate the correct input data files:
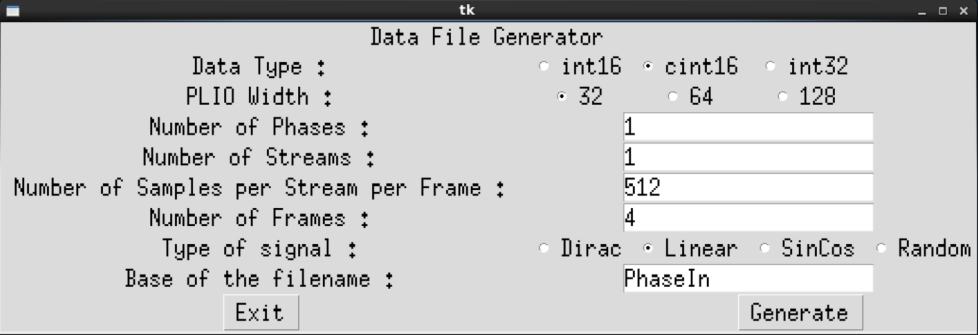
You have access to a number of parameters:
Data Type: by default
cint16as this is what you will use throughout this tutorialPLIO Width: by default
64as this is the width which is used in this tutorialNumber of Phases: for Super Sampling Rate Filters
Number of Streams: for the SSR filters using the 2 streams of the AI Engines
Number of Samples per Stream per Phase: Each stream contains a number of samples defined there
Number of Frames: simulations are launched for a limited number of Frames
Base of the Filename:
PhaseInby default which generates the following names:Single Stream, Single Phase:
PhaseIn_0.txtSingle Stream, Polyphase:
PhaseIn_0.txt,PhaseIn_1.txt, …Dual streams, Polyphase:
PhaseIn_0_0.txt,PhaseIn_0_0.txt,PhaseIn_1_0.txt,PhaseIn_1_0.txt``, …
Another possibility is to type GenerateStreams with the same parameters. If you type GenerateStreams without parameters, a usage text will be displayed:
>>GenerateStreams
Stream Content Generation
================================================================================================
Usage:
GenerateStreams DataType PLIO_Width NPhases NStreams NSamples NFrames SequenceType Basename
Datatype: cint16, int16, int32
PLIO_Width: 32, 64 or 128
NPhases: any integer >= 1
NStreams: 1 or 2
NSamples: integer, multiple of 8
NFrames: Any integer >= 1
SequenceType: Dirac, Linear, SinCos, Random
Basename: file name that will prepend phase and stream index
================================================================================================
ProcessAIEOutput¶
This utility takes all generated outputs and displays the reconstructed signal. For Single Stream/Single Phase it will display a signal using the timestamps written in the file.
If your output signals are stored in files named output_0.txt … then navigate to the output directory and type ProcessAIEOutput output_* to process the output of the AI Engines.
Two other files are generated:
Atot.txtwhich is the output phase by phaseout.txtwhich is the textfile of the reconstructed signal
StreamThroughput¶
This utility computes the throughput concerning all AI Engine output files given in an argument.
GetDeclare.sh¶
This utility has been created to view the template arguments that were used for kernel declaration in the Double Stream SSR case. It can be easily modified to be adapted to different cases.
Copyright© 2020–2022 Xilinx
XD020