Vitis Codec Library Tutorial¶
Vitis Codec and Hardware Acceleration¶
Image encoding and decoding (codec in short) are very common and important operations in Internet applications. The Vitis Codec library provides a set of acceleration APIs to accelerate image encoding, decoding and other related algorithms. This tutorial will be based on the popular JPEG decoding and WebP encoding to show how to accelerate image codec projects by using these APIs.
The tutorial includes four labs:
- Lab-1: How Vitis Codec Library Works
- Lab-2: Using L1-level API to evaluate JPEG decoding acceleration
- Lab-3: Using L2-level API to implement a single-kernel acceleration for JPEG decoding
- Lab-4: Using multi-kernel solution to accelerate WebP encoding based on open-source project
Lab-1: How Vitis Codec Library Works¶
Vitis Codec Library is an open-sourced library written in HLS C/C++ for the acceleration of image processing. It aims to provides reference designs for image codec algorithms that fit the Xilinx Alveo Series acceleration cards. The APIs in Vitis Codec Library have been classified into two layers, namely L1/L2. Each targets to serve different audience.
- L1 APIs locate at
Vitis_Libraries/codec/L1. They are basic components that will be used to compose compute-units. The L1 APIs are all well-optimized HLS designs and are able to fit into various resource constraints. - L2 APIs locate at
Vitis_Libraries/codec/L2. They are a number of compute-unit designs running on Alveo cards. It provides a set of compute-unit designs implemented in HLS codes. These L2 APIs needs to be compiled as OpenCL kernels and will be called by OpenCL APIs.
Get the Vitis Codec Library¶
Get the Dependencies¶
Setup Environment¶
#!/bin/bash source <Vitis_install_path>/Vitis/2022.1/settings64.sh source <install_path_xrt>/xrt/setup.sh export PLATFORM_REPO_PATHS=<install_path_platforms> export DEVICE=xilinx_u200_gen3x16_xdma_2_202110_1 export TARGET=sw_emu
Note: The TARGET environment variable can be set as sw_emu, hw_emu and hw according to which emulation mode is expected to run. sw_emu is for C level emulations. hw_emu is for RTL level emulations. hw is for real on-board test. For more information about the Vitis Target please have a look at here.
Download the Vitis Graph Library¶
#!/bin/bash git clone https://github.com/Xilinx/Vitis_Libraries.git cd Vitis_Libraries/codec
Command to Run L1 cases¶
#!/bin/bash cd L1/tests/jpegdec # jpegdec is an example case. Please change directory to any other cases in L1/test if interested make help # show available make command make run CSIM=1 # run C level simulation of the HLS code make run CSYNTH=1 COSIM=1 # run RTL level simulation of the HLS code make cleanall
Test control variables are:
CSIMfor C level simulation.CSYNTHfor high level synthesis to RTL.COSIMfor co-simulation between software test bench and generated RTL.VIVADO_SYNfor synthesis by Vivado.VIVADO_IMPLfor implementation by Vivado.
For all these variables, setting to 1 indicates execution while 0 for skipping.
The default value of all these control variables are 0, so they can be omitted from command line
if the corresponding step is not wanted.
For more information about L1 APIs please have Lab-2: Using L1-level API to evaluate JPEG decoding acceleration.
Command to Run L2 cases¶
#!/bin/bash cd L2/demos/jpegDec # jpegDec is an example case. Please change directory to any other cases in L2/demos if interested. make help # show available make command make host # build the binary running on host make build # build the binary running on Alveo make run # run the entire program make cleanall
Here, TARGET decides the FPGA binary type
sw_emuis for software emulationhw_emuis for hardware emulationhwis for deployment on physical card. (Compilation to hardware binary often takes hours.)
Besides run, the Vitis case makefile also allows host and xclbin as build target.
For more information about L2 APIs please have a look at Lab-3: Using L2-level API to implement a single-kernel acceleration for JPEG decoding.
Lab-2: Using L1-level API to evaluate JPEG decoding acceleration¶
Lab purpose¶
Before using Vitis flow to build a full-function kernel running on hardware, users may want to use a relative simple flow to estimate performance and resource consumption for some key modules of a complex algorithm. In this lab, users will estimate a key module called ‘kernel_parser_decoder ‘ which involves JPEG parsing and Huffman decoding. Users will get an exported IP of the key module in the end of this lab, but this is just the first step to achieve a successful design.
Operation steps¶
(1) Learn about run_hls.tcl file¶
In Vitis libraries, all L1 flows are controlled by a tcl file named run_hls.tcl. The file for this lab can be found at L1/tests/jpegDec/run_ hls.tcl. Compared to L2 flow which is based on Opencl kernels, L1 flow allows users to quickly set the top-level functions so that they can focus more on a few functions of interests, analyze the performance bottlenecks of these functions, or run rapid synthesis and simulation without any source code modification.
(2) CSIM:¶
- Build and run one of the following using U200 platform
cd L1/tests/jpegdec make run DEVICE=xilinx_u200_gen3x16_xdma_2_202110_1.xpfm CSIM=1 # DEVICE is case-insensitive and support awk regex. # Alternatively, the FPGA part can be speficied via XPART. When XPART is set, DEVICE will be ignored. make run XPART=xcu200-fsgd2104-2-e CSIM=1 # delete generated files make clean
- Change input jpeg file for test
vi run_hls.tcl
# update the *.jpg path after the "-JPEGFile"
-JPEGFile *.jpg
Example csim output:
------------ Test for decode image.jpg ------------- WARNING: Vitis_Libraries/codec/L1/images/t0.jpg will be opened for binary read. 51193 entries read from Vitis_Libraries/codec/L1/images/t0.jpg hls_mcuv=33, hls_mcuh=39, hls_mcuc=1287, huffman 1 bits codes is :0b0000000000000000 huffman 2 bits codes is :0b0000000000000000 huffman 3 bits codes is :0b0000000000000010 huffman 4 bits codes is :0b0000000000001110 huffman 5 bits codes is :0b0000000000011110 huffman 6 bits codes is :0b0000000000111110 huffman 7 bits codes is :0b0000000001111110 huffman 8 bits codes is :0b0000000011111110 huffman 9 bits codes is :0b0000000111111110 huffman 10 bits codes is :0b0000001111111110 huffman 11 bits codes is :0b0000011111111100 huffman 12 bits codes is :0b0000111111111000 huffman 13 bits codes is :0b0001111111110000 huffman 14 bits codes is :0b0011111111100000 huffman 15 bits codes is :0b0111111111000000 huffman 16 bits codes is :0b1111111110000000 ... the end 3 blocks before zigzag are : ffffffb6, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, ffffffe6, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0015, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, Ready for next image! INFO: [SIM 211-1] CSim done with 0 errors.
In order to facilitate user observation, the key module prints out the last three 8x8 DCT coefficients of the last MCU, including a Y, U and V.
(3) Synthesis:¶
- Build and run one of the following using U200 platform
make run DEVICE=xilinx_u200_gen3x16_xdma_2_202110_1.xpfm CSYNTH=1 # DEVICE is case-insensitive and support awk regex. # Alternatively, the FPGA part can be speficied via XPART. When XPART is set, DEVICE will be ignored. make run XPART=xcu200-fsgd2104-2-e CSYNTH=1
- Quick reset the top-level functions so that they can focus more on a few functions of interest
vi run_hls.tcl
# update the "set_top kernel_parser_decoder", for example "set_top Huffman_decoder", the name of top is the function name in the design codes.
set_top kernel_parser_decoder --> set_top Huffman_decoder
Then rerun the command of CSYNTH, will allow user to analyze the performance bottlenecks of “Huffman_decoder” function, or run rapid synthesis and simulation without any source code modification.
Example Synthesis output:
Vitis HLS - High-Level Synthesis from C, C++ and OpenCL v2022.1 (64-bit) ... INFO: [HLS 200-1510] Running: set_top kernel_parser_decoder INFO: [HLS 200-1510] Running: open_solution -reset solution1 ... INFO: [VHDL 208-304] Generating VHDL RTL for kernel_parser_decoder. INFO: [VLOG 209-307] Generating Verilog RTL for kernel_parser_decoder. INFO: [HLS 200-790] **** Loop Constraint Status: All loop constraints were NOT satisfied. INFO: [HLS 200-789] **** Estimated Fmax: 271.96 MHz INFO: [HLS 200-111] Finished Command csynth_design CPU user time: 65.56 seconds. CPU system time: 4.61 seconds. Elapsed time: 73.87 seconds; current allocated memory: 448.0 00 MB. INFO: [HLS 200-112] Total CPU user time: 71.64 seconds. Total CPU system time: 6.21 seconds. Total elapsed time: 80.36 seconds; peak allocated memory: 1.195 GB.
Loop constraints may not be satisfied, as the goal of loop is set to 300MHz in the run_hls.tcl, and different hls tool version may result in different “Estimated Fmax”.
- Check the unsatisfied path
Read the report of CSYNTH, grep “critical path” like below:
INFO: [HLS 200-10] ---------------------------------------------------------------- INFO: [HLS 200-42] -- Implementing module 'Huffman_decoder_Pipeline_DECODE_LOOP' INFO: [HLS 200-10] ---------------------------------------------------------------- INFO: [SCHED 204-11] Starting scheduling ... INFO: [SCHED 204-61] Pipelining loop 'DECODE_LOOP'. INFO: [HLS 200-1470] Pipelining result : Target II = 1, Final II = 1, Depth = 4, loop 'DECODE_LOOP' WARNING: [HLS 200-1016] The critical path in module 'Huffman_decoder_Pipeline_DECODE_LOOP' consists of the following: 'add' operation ('add_ln503', Vitis_Libraries/codec/L1/src/XAcc_jpegdecoder.cpp:503) [582] (0.705 ns) 'shl' operation ('shl_ln503', Vitis_Libraries/codec/L1/src/XAcc_jpegdecoder.cpp:503) [584] (0 ns) 'icmp' operation ('icmp_ln503', Vitis_Libraries/codec/L1/src/XAcc_jpegdecoder.cpp:503) [585] (0.859 ns) 'and' operation ('and_ln503', Vitis_Libraries/codec/L1/src/XAcc_jpegdecoder.cpp:503) [591] (0 ns) 'select' operation ('select_ln503', Vitis_Libraries/codec/L1/src/XAcc_jpegdecoder.cpp:503) [592] (0 ns) 'select' operation ('block_tmp', Vitis_Libraries/codec/L1/src/XAcc_jpegdecoder.cpp:498) [593] (0.243 ns) 'add' operation ('block', Vitis_Libraries/codec/L1/src/XAcc_jpegdecoder.cpp:516) [599] (0.785 ns) multiplexor before 'phi' operation ('block') with incoming values : ('lastDC_load', Vitis_Libraries/codec/L1/src/XAcc_jpegdecoder.cpp:516) ('block', Vitis_Libraries/codec/L1/src/XAcc_jpegdecoder.cpp:516) [628] (0.387 ns) 'phi' operation ('block') with incoming values : ('lastDC_load', Vitis_Libraries/codec/L1/src/XAcc_jpegdecoder.cpp:516) ('block', Vitis_Libraries/codec/L1/src/XAcc_jpegdecoder.cpp:516) [628] (0 ns) multiplexor before 'phi' operation ('empty_304', Vitis_Libraries/codec/L1/src/XAcc_jpegdecoder.cpp:516) with incoming values : ('lastDC_load', Vitis_Libraries/codec/L1/src/XAcc_jpegdecoder.cpp:516) ('block', Vitis_Libraries/codec/L1/src/XAcc_jpegdecoder.cpp:516) ('lastDC_load_1') [632] (0.387 ns) 'phi' operation ('empty_304', Vitis_Libraries/codec/L1/src/XAcc_jpegdecoder.cpp:516) with incoming values : ('lastDC_load', Vitis_Libraries/codec/ L1/src/XAcc_jpegdecoder.cpp:516) ('block', Vitis_Libraries/codec/L1/src/XAcc_jpegdecoder.cpp:516) ('lastDC_load_1') [632] (0 ns) 'select' operation ('select_ln549_2', Vitis_Libraries/codec/L1/src/XAcc_jpegdecoder.cpp:549) [641] (0.243 ns) 'store' operation ('lastDC_write_ln592', Vitis_Libraries/codec/L1/src/XAcc_jpegdecoder.cpp:592) of variable 'select_ln549_2', Vitis_Libraries/codec/L1/src/XAcc_jpegdecoder.cpp:549 on local variable 'op' [651] (0.453 ns) ...
Then check the report for this loop: use command “vi test.prj/solution1/syn/report/Huffman_decoder_Pipeline_DECODE_LOOP_csynth.rpt ” in the meanwhile open the GUI.
In the Schedule Viewer in GUI, users could check the details of the circuit:
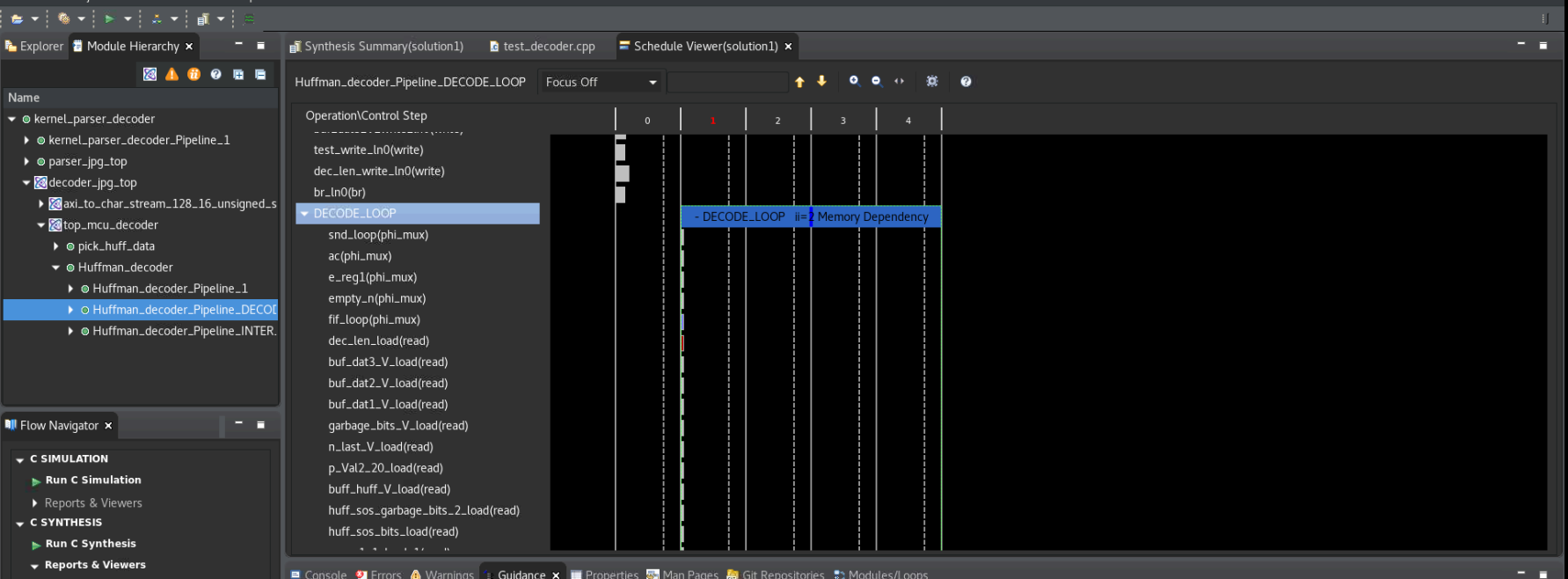
Comparing the two above, it can be seen that the timing is not satisfied because the number of bits of the shift register and comparator is large. There is no better optimization method for this situation. Users can reduce the bit width of this circuit according to their needs to improve the timing. Of course, this change may also lead to a reduction in bandwidth, so there needs a trade-off between the width and frequency to achieve the best performance.
(4) COSIM:¶
- Build and run one of the following with U200 platform
make run DEVICE=xilinx_u200_gen3x16_xdma_2_202110_1.xpfm COSIM=1 # DEVICE is case-insensitive and support awk regex. # Alternatively, the FPGA part can be speficied via XPART. When XPART is set, DEVICE will be ignored. make run XPART=xcu200-fsgd2104-2-e COSIM=1
Example output:
... # xsim {kernel_parser_decoder} -autoloadwcfg -tclbatch {kernel_parser_decoder.tcl} Time resolution is 1 ps source kernel_parser_decoder.tcl ## run all //////////////////////////////////////////////////////////////////////////////////// // Inter-Transaction Progress: Completed Transaction / Total Transaction // Intra-Transaction Progress: Measured Latency / Latency Estimation * 100% // // RTL Simulation : "Inter-Transaction Progress" ["Intra-Transaction Progress"] @ "Simulation Time" //////////////////////////////////////////////////////////////////////////////////// // RTL Simulation : 0 / 1 [n/a] @ "109000" // RTL Simulation : 1 / 1 [n/a] @ "543586000" //////////////////////////////////////////////////////////////////////////////////// $finish called at time : 543586000 ps : File "Vitis_Libraries/codec/L1/tests/jpegdec/test.prj/solution1/sim/verilog/kernel_parser_decoder.autotb.v" Line 1564 run: Time (s): cpu = 00:00:02 ; elapsed = 00:01:18 . Memory (MB): peak = 2840.148 ; gain = 0.000 ; free physical = 28775 ; free virtual = 213419 ## quit INFO: xsimkernel Simulation Memory Usage: 307116 KB (Peak: 371652 KB), Simulation CPU Usage: 77750 ms INFO: [Common 17-206] Exiting xsim at Sun Apr 17 20:36:36 2022... INFO: [COSIM 212-316] Starting C post checking ... ------------ Test for decode image.jpg ------------- WARNING: Vitis_Libraries/codec/L1/images/t0.jpg will be opened for binary read. 51193 entries read from Vitis_Libraries/codec/L1/images/t0.jpg ****the end 3 blocks before zigzag are : ffffffb6, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, ffffffe6, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0015, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, 0000, Ready for next image! INFO: [COSIM 212-1000] *** C/RTL co-simulation finished: PASS *** ...
(5) Design with export¶
In this step, the HLS tool will run CSYNTH, VIVADO_SYN and VIVADO_IMPL flow to generate the IP file.
- Build and run one of the following using U200 platform
make run DEVICE=xilinx_u200_gen3x16_xdma_2_202110_1.xpfm VIVADO_IMPL=1 # DEVICE is case-insensitive and support awk regex. # Alternatively, the FPGA part can be speficied via XPART. When XPART is set, DEVICE will be ignored. make run XPART=xcu200-fsgd2104-2-e VIVADO_IMPL=1
Example output:
Implementation tool: Xilinx Vivado v.2022.1 ... #=== Post-Implementation Resource usage === SLICE: 0 LUT: 7945 FF: 8073 DSP: 12 BRAM: 5 URAM: 0 LATCH: 0 SRL: 678 CLB: 1746 #=== Final timing === CP required: 3.330 CP achieved post-synthesis: 3.605 CP achieved post-implementation: 3.347 Timing not met
The report shows ‘timing not met’, that means the Vivado implementation process cannot achieve the targeted frequency (300MHz set in the run_hls.tcl). As this module always plays a role of bottleneck in entire JPGE decoding architecture, the final JPEG decoder should be likely to work at 270 to 280 MHz. That is a common situation for complex HLS designs. This tutorial will not discuss solutions for timing problem but for most of cases we still have a chance to improve the frequency.
Based on the above results, we can make some estimates about the throughputs, including:
- The design can process a Huffman symbol up to 270 million per second
- Assuming that if the compression ratio is 4 ~ 8 for a JPEG image, the final output speed will be up to 1 ~ 2GB of YUV data per second
- If the inverse quantization and inverse DCT transform modules need matching throughput of Huffman, it is best to recovery 4 ~ 8 pixels in a cycle
Compared with synthesis, using Export can obtain more accurate performance and resource consumption. Users usually needn’t to do Export for each design iteration, but it is recommended to periodically perform Export to confirm whether the performance and area of the design can meet the requirement.
Lab summary¶
- L1 is based on HLS flow. The main steps include CSIM, synthesis, COSIM and export which are controlled by a
run_hls.tclfile - L1 flow is helpful to estimate resources and performance
- L1 flow makes it easier to change the top-level function
Lab-3: Using L2-level API to implement a single-kernel acceleration for JPEG decoding¶
Operation steps¶
(1) Understand the Work Directory¶
Makefile: L2 flow control fileconn_u200.cfg: to specify the external memory ports map. Some constraints of Vivado can also be added heredescription.json: The description of the L2 API used for creating the Makefile automaticallyutils.mk: included by the Makefile
Setup environment
source <intstall_path_vitis>/installs/lin64/Vitis/2022.1/settings64.sh source <intstall_path_xrt>/xrt/setup.sh export PLATFORM_REPO_PATHS=<intstall_path_platform>/platforms
(2) Build kernel for different modes¶
cd L2/demos/jpegDec # build and run one of the following using U200 platform make run TARGET=sw_emu DEVICE=xilinx_u200_gen3x16_xdma_2_202110_1.xpfm # delete generated files make cleanall
Here, TARGET decides the FPGA binary type
sw_emuis for software emulationhw_emuis for hardware emulationhwis for deployment on physical card. (Compilation to hardware binary often takes hours.)
Besides run, the Vitis case makefile also allows host and xclbin as build target.
(3) Run kernel in Software-Emulation mode¶
# build and run JPEG Decoder using U200 platform make run TARGET=sw_emu DEVICE=xilinx_u200_gen3x16_xdma_2_202110_1.xpfm
Example output:
... Info: Test passed INFO: writing the YUV file! WARNING: t0.raw will be opened for binary write. WARNING: t0.yuv will be opened for binary write. INFO: fmt 1, bas_info->mcu_cmp = 6 INFO: bas_info->hls_mbs[cmp] 4, 1, 1 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3E, 3E, 3E, 3E, 3E, 3E, 3D, 3E, 3E, 3E, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 40, 40, 40, 40, 40, 40, 40, 40, 40, 40, 40, 40, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3F, 3E, 3E, 3E, 3E, 3E, 3E, 3E, 3E, 40, 40, 40, 40, 40, 40, 40, 40, 3F, 40, 40, 40, 40, 40, 40, 40, 40, 40, 40, 40, 40, 3F, 3F, 3F, 41, 41, 40, 40, 3F, 40, 40, 40, 40, 40, 40, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 40, 40, 40, 41, 41, 41, 41, 41, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 62, 62, 62, 62, 62, 62, 61, 62, 62, 62, 63, 63, 63, 63, 63, 63, 63, 63, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 63, 63, 63, 63, 63, 63, 63, 63, 62, 62, 62, 62, 62, 62, 62, 62, 64, 64, 64, 64, 64, 64, 64, 64, 63, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 63, 63, 63, 65, 65, 64, 64, 63, 64, 64, 64, 64, 64, 64, 65, 65, 65, 65, 65, 65, 65, 65, 65, 65, 65, 65, 65, 64, 64, 64, 65, 65, 65, 65, 65, Please open the YUV file with fmt 1 and (width, height) = (624, 528) ...
(4) Run kernel in Hardware-Emulation mode¶
# build and run JPEG Decoder using U200 platform make run TARGET=hw_emu DEVICE=xilinx_u200_gen3x16_xdma_2_202110_1.xpfm
Now the test bench will run the case 10 times to calculate an average speed of the kernel
Example output
... ------------ Test for decode image.jpg ------------- WARNING: Vitis_Libraries/codec/L2/demos/jpegDec/images/t0.jpg will be opened for binary read. 51193 entries read from Vitis_Libraries/codec/L2/demos/jpegDec/images/t0.jpg Found Platform Platform Name: Xilinx Info: Context created Info: Command queue created INFO: Found Device=xilinx_u50_gen3x16_xdma_201920_3 INFO: Importing build_dir.hw_emu.xilinx_u50_gen3x16_xdma_201920_3/kernelJpegDecoder.xclbin Loading: 'build_dir.hw_emu.xilinx_u50_gen3x16_xdma_201920_3/kernelJpegDecoder.xclbin' Loading: 'build_dir.hw_emu.xilinx_u50_gen3x16_xdma_201920_3/kernelJpegDecoder.xclbin' INFO: [HW-EMU 01] Hardware emulation runs simulation underneath. Using a large data set will result in long simulation times. It is recommended that a small dataset is used for faster execution. The flow uses approximate models for Global memories and interconnect and hence the performance data generated is approximate. configuring penguin scheduler mode scheduler config ert(0), dataflow(1), slots(16), cudma(1), cuisr(0), cdma(0), cus(1) Info: Program created INFO: Kernel has been created Info: Kernel created INFO: Kernel has been created INFO: Finish kernel setup INFO: Finish kernel execution INFO: Finish E2E execution ------------------------------------------------------- INFO: Data transfer from host to device: 360540 us ------------------------------------------------------- INFO: Data transfer from device to host: 296951 us ------------------------------------------------------- INFO: kernel 0: execution time 135012750 usec INFO: kernel 1: execution time 131009663 usec INFO: kernel 2: execution time 134012825 usec INFO: kernel 3: execution time 133013391 usec INFO: kernel 4: execution time 132012707 usec INFO: kernel 5: execution time 133013044 usec INFO: kernel 6: execution time 130013132 usec INFO: kernel 7: execution time 130012762 usec INFO: kernel 8: execution time 130012930 usec INFO: kernel 9: execution time 135013237 usec INFO: Average kernel execution per run: 132312644 us ------------------------------------------------------- INFO: Average E2E per run: 1355900288 us ------------------------------------------------------- ... Please open the YUV file with fmt 1 and (width, height) = (624, 528) WARNING: Vitis_Libraries/codec/L2/demos/jpegDec/images/t0.yuv.h will be opened for binary write. Ready for next image! INFO: [HW-EMU 06-0] Waiting for the simulator process to exit INFO: [HW-EMU 06-1] All the simulator processes exited successfully
(5) Run kernel in Hardware¶
Now the test bench will run the case 10 times to calculate an average speed of the kernel
# build and run JPEG Decoder using U200 platform make run TARGET=hw DEVICE=xilinx_u200_gen3x16_xdma_2_202110_1.xpfm
Building xclbin will take about 4 hours, take a coffee break.
Example output:
Found Platform Platform Name: Xilinx INFO: Found Device=xilinx_u200_gen3x16_xdma_2_202110_1 INFO: Importing kernelJpegDecoder.xclbin Loading: 'kernelJpegDecoder.xclbin' INFO: Kernel has been created INFO: Finish kernel setup ... INFO: Finish kernel execution INFO: Finish E2E execution INFO: Data transfer from host to device: 108 us INFO: Data transfer from device to host: 726 us INFO: Average kernel execution per run: 1515 us ... INFO: android.yuv will be generated from the jpeg decoder's output INFO: android.yuv is generated correctly
So for this 1280x960 android.jpg file the output throughput is about 1216MB/s ( (1280x960x3)/2/1515 ).
To check the output yuv file, download https://sourceforge.net/projects/raw-yuvplayer/ . Then upload the rebuild_image.yuv, set the right sample radio and custom size on the software, and check the yuv file.
Lab summary¶
- L2 flow is based on Vitis flow, and the main steps include sw_emu, hw_emu, and hw
- Run hardware acceleration application on a device
Lab-4: Using multi-kernel solution to accelerate WebP encoding based on open-source project¶
Lab purpose¶
The user’s image codec may be based on an open source project. This lab will show an accelerated process based on an open source project, the Webp encoder. Webp image coding is not only more complex, but also involves HW/SW partition and the design of multiple kernels. To learn:
- L2 accelerated process for open source projects
- Multi kernel acceleration process
Operation steps¶
(1) Open source project analysis and kernel partition¶
Here are two basic kernel partition principles:
- Focus on the operation which computing workload related to image size. And try to abstract some one-time or limit-time operations in pre-processing or post-processing which can be excluded from kernel. Although the computation of image encoding is large, some preprocessing and post-processing workload have no relation with the image size, so they can be excluded outside from kernel. This situation is common for many image codec algorithms. For example, encoding always needs to calculate some quantization parameters by using some complex floating operations but only for limit time for an image. Another example is the adding head for compressed bit-stream.
- Serial running modules with large latency related to image size should be divided into different kernels to realize multi kernel concurrency
Webp can be divided into two serial modules, one is for prediction and probability statistics, and the other is for arithmetic coding. Since the arithmetic coding can’t start until the probability statistics module finish scanning the entire image, it should be divided into two kernels. In this way, when processing multiple images, the two kernels can be concurrent, which increases the system throughput.
(2) Project files for multi-kernel design¶
Makefileconn_u200.inidescription.jsonutils.mk
(3) Software Emulation¶
cd L2/demos/webpEnc make run TARGET=sw_emu DEVICE=xilinx_u200_gen3x16_xdma_2_202110_1
(4) Hardware Emulation¶
cd L2/demos/webpEnc make run TARGET=hw_emu DEVICE=xilinx_u200_gen3x16_xdma_2_202110_1
report path: reports/_x.hw_emu.xilinx_u200_gen3x16_xdma_2_202110_1/webp_IntraPredLoop2_NoOut_1/hls_reports/webp_IntraPredLoop2_NoOut_1_csynth.rpt
+---------------------+---------+------+---------+---------+-----+ | Name | BRAM_18K| DSP | FF | LUT | URAM| +---------------------+---------+------+---------+---------+-----+ |DSP | -| -| -| -| -| |Expression | -| -| 0| 2| -| |FIFO | -| -| -| -| -| |Instance | 105| 387| 119670| 178708| 8| |Memory | -| -| -| -| -| |Multiplexer | -| -| -| 101| -| |Register | -| -| 392| -| -| +---------------------+---------+------+---------+---------+-----+ |Total | 105| 387| 120062| 178811| 8| +---------------------+---------+------+---------+---------+-----+ |Available SLR | 1440| 2280| 788160| 394080| 320| +---------------------+---------+------+---------+---------+-----+ |Utilization SLR (%) | 7| 16| 15| 45| 2| +---------------------+---------+------+---------+---------+-----+ |Available | 4320| 6840| 2364480| 1182240| 960| +---------------------+---------+------+---------+---------+-----+ |Utilization (%) | 2| 5| 5| 15| ~0| +---------------------+---------+------+---------+---------+-----+
report path: reports/_x.hw.xilinx_u200_gen3x16_xdma_2_202110_1/webp_2_ArithmeticCoding_1/hls_reports/webp_2_ArithmeticCoding_1_csynth.rpt
+---------------------+---------+------+---------+---------+-----+ | Name | BRAM_18K| DSP | FF | LUT | URAM| +---------------------+---------+------+---------+---------+-----+ |DSP | -| -| -| -| -| |Expression | -| -| 0| 1127| -| |FIFO | -| -| -| -| -| |Instance | 24| 3| 26227| 33840| 0| |Memory | 1| -| 0| 0| 0| |Multiplexer | -| -| -| 1610| -| |Register | -| -| 1415| -| -| +---------------------+---------+------+---------+---------+-----+ |Total | 25| 3| 27642| 36577| 0| +---------------------+---------+------+---------+---------+-----+ |Available SLR | 1440| 2280| 788160| 394080| 320| +---------------------+---------+------+---------+---------+-----+ |Utilization SLR (%) | 1| ~0| 3| 9| 0| +---------------------+---------+------+---------+---------+-----+ |Available | 4320| 6840| 2364480| 1182240| 960| +---------------------+---------+------+---------+---------+-----+ |Utilization (%) | ~0| ~0| 1| 3| 0| +---------------------+---------+------+---------+---------+-----+
(5) Hardware Build and Check Resource Consumption¶
cd L2/demos/webpEnc make run TARGET=hw DEVICE=xilinx_u200_gen3x16_xdma_2_202110_1
report path: _x_temp.hw.xilinx_u200_gen3x16_xdma_2_202110_1/link/vivado/vpl/prj/prj.runs/impl_1/kernel_util_routed.rpt
+----------------------------------+------------------+------------------+-------------------+----------------+---------------+----------------+ | Name | LUT | LUTAsMem | REG | BRAM | URAM | DSP | +----------------------------------+------------------+------------------+-------------------+----------------+---------------+----------------+ | Platform | 192064 [ 16.25%] | 17282 [ 2.92%] | 268446 [ 11.35%] | 314 [ 14.54%] | 20 [ 2.08%] | 10 [ 0.15%] | | User Budget | 990176 [100.00%] | 574558 [100.00%] | 2096034 [100.00%] | 1846 [100.00%] | 940 [100.00%] | 6830 [100.00%] | | Used Resources | 69389 [ 7.01%] | 7136 [ 1.24%] | 91572 [ 4.37%] | 87 [ 4.71%] | 10 [ 1.06%] | 414 [ 6.06%] | | Unused Resources | 920787 [ 92.99%] | 567422 [ 98.76%] | 2004462 [ 95.63%] | 1759 [ 95.29%] | 930 [ 98.94%] | 6416 [ 93.94%] | | webp_2_ArithmeticCoding_1 | 16065 [ 1.62%] | 2520 [ 0.44%] | 22841 [ 1.09%] | 15 [ 0.81%] | 0 [ 0.00%] | 4 [ 0.06%] | | webp_2_ArithmeticCoding_1_1 | 16065 [ 1.62%] | 2520 [ 0.44%] | 22841 [ 1.09%] | 15 [ 0.81%] | 0 [ 0.00%] | 4 [ 0.06%] | | webp_IntraPredLoop2_NoOut_1 | 53324 [ 5.39%] | 4616 [ 0.80%] | 68731 [ 3.28%] | 72 [ 3.90%] | 10 [ 1.06%] | 410 [ 6.00%] | | webp_IntraPredLoop2_NoOut_1_1 | 53324 [ 5.39%] | 4616 [ 0.80%] | 68731 [ 3.28%] | 72 [ 3.90%] | 10 [ 1.06%] | 410 [ 6.00%] | +----------------------------------+------------------+------------------+-------------------+----------------+---------------+----------------+
(6) Hardware Running¶
Webp Input Arguments:
Usage: cwebp -[-use_ocl -q -o] -xclbin : the kernel file list.rst: the input list -use_ocl: should be kept -q: compression quality -o: output directory
Compared to original command-line parameter, there are three differences here. The first is ‘-xclbin’ for specifying the kernel files. The second is a change for input image file which is replaced by a file list file in which more than one input images are listed line by line. The third, the ‘-use_ocl’ is used for enable vitis flow.
The following figure shows the host information when run on board. The time listed in the figure is not accurate.
./cwebp -xclbin kernel.xclbin list.rst -use_ocl -q 80 -o ./images INFO: CreateKernel start. INFO: Number of Platforms: 1 INFO: Selected Platform: Xilinx INFO: Number of devices for platform 0: 2 INFO: target_device found: xilinx_u200_gen3x16_xdma_base_2 INFO: target_device chosen: xilinx_u200_gen3x16_xdma_base_2 Info: Context created Info: Command queue created INFO: OpenCL Version: 1.-48 INFO: Loading kernel.xclbin INFO: Loading kernel.xclbin Finished Info: Program created Info: Kernel created Info: Kernel created INFO: CreateKernel finished. Computation time is 328.504000 (ms) INFO: Create buffers started. INFO: Create buffers finished. Computation time is 48.225000 (ms) INFO: WebPEncodeAsync Starts... INFO: Nloop = 1 INFO: VP8EncTokenLoopAsync starts ... *** Picture: 1 - 1, Buffer: 0, Instance: 0, Event: 0 *** HtoD webpen.c INFO: Host2Device finished. Computation time is 0.874000 (ms) INFO: PredKernel Finished. Computation time is 0.258000 (ms) INFO: ACKernel Finished. Computation time is 0.155000 (ms) INFO: Device2Host finished. Computation time is 0.118000 (ms) INFO: Loop of Pictures Finished. Computation time is 17.825000 (ms) INFO: VP8EncTokenLoopAsync Finished. Computation time is 24.683000 (ms) INFO: WebPEncodeAsync Finished. Computation time is 31.885000 (ms) INFO: Release Kernel. Info: Test passed
To get the accurate kernel execution time, please add a file “xrt.ini”, and fill this file with following directives.
#Start of Debug group [Debug] profile=true timeline_trace=true data_transfer_trace=fine app_debug=true opencl_summary=true opencl_trace=true #Start of Runtime group [Runtime] runtime_log = console
Kernel Execution Kernel,Number Of Enqueues,Total Time (ms),Minimum Time (ms),Average Time (ms),Maximum Time (ms), webp_2_ArithmeticCoding_1,1,2.95381,2.95381,2.95381,2.95381, webp_IntraPredLoop2_NoOut_1,1,3.61861,3.61861,3.61861,3.61861,
For more information about how to analyze performance, please refer to Application Acceleration Development (UG1393)
Lab summary¶
- Focus on the operation which computing workload related to image size
- Serial processed modules may be divided into multiple kernels to realize multi-kernel concurrency
Tutorial Summary¶
JPEG decoder and webp encoder are very representative in image transcoding applications. Codec Library has also launched many other open source and self-developed APIs some of them can support the developing flow based on System Compiler from 22.1. The tutorial will be developed to cover more codecs and their combinations, more flows and more classic applications.