L3 GQE Overlay User Guide¶
For processing dataset with TB level scale, we develop L3 API. In this layer, we provide “hash partition + hash joini/aggregate” solution to eliminate DDR size limitation. In both join and aggregation L3 APIs, we set three stategies for different scaled datasets. In current release, user can set strategy manually according to dataset entries. Below, we will elaborate reference for strategy setting. ..Note: Test datasets below are based on TPC-H different scale factor.
class xf::database::gqe::Joiner¶
#include "gqe_join.hpp"
Overview¶
Methods¶
join¶
ErrCode join ( Table& tab_a, std::string filter_a, Table& tab_b, std::string filter_b, std::string join_str, Table& tab_c, std::string output_str, int join_type = INNER_JOIN, JoinStrategyBase* strategyimp = nullptr )
join function.
Usage:
auto sptr = new gqe::JoinStrategyManualSet(solution, sec_o, sec_l, slice_num, log_part, cpu_aggr);
err_code = bigjoin.join(
tab_o, "19940101<=o_orderdate && o_orderdate<19950101",
tab_l, "",
"o_orderkey = l_orderkey",
tab_c1, "c1=l_extendedprice, c2=l_discount, c3=o_orderdate, c4=l_orderkey",
gqe::INNER_JOIN,
sptr);
delete smanual;
Input filter_a/filter_b like “19940101<=o_orderdate && o_orderdate<19950101”, o_orderdate and o_orderdate must be exsisted colunm names in table a/b when no filter conditions, input “”
Input join conditions like “left_join_key_0=right_join_key_0” when enable dual key join, use comma as seperator, “left_join_key_0=right_join_key_0,left_join_key_1=right_join_key_1”
Output strings are like “output_c0 = tab_a_col/tab_b_col”, when contains several columns, use comma as seperator
Parameters:
| tab_a | left table |
| filter_a | filter condition of left table |
| tab_b | right table |
| filter_b | filter condition of right table |
| join_str | join condition(s) |
| tab_c | result table |
| output_str | output column mapping |
| join_type | INNER_JOIN(default) | SEMI_JOIN | ANTI_JOIN. |
| strategyimp | pointer to an object of JoinStrategyBase or its derived type. |
GQE Join L3 layer targets to processing datasets with big left/right table, all solutions are listed below:
- solution 0: Hash Join (Build for left table + Probe for right table), only for testing small dataset.
- solution 1: Build + Pipelined Probes
- solution 2: Hash Partition + Hash Join (Build + Probe(s))
In solution 1, build once, then do pipelined probes. This solution targets to datasets that left table is relatively small. In its processing, right table is cutted horizontay into many slices without extra overhead. When left table size is getting larger, we swith to solution 2, in which partition kernel will join working to distribute each row into its corresponding hash partition, thus making many small hash joins. Comparing the two methonds, although hash partition kernel introduces extra overhead in solution 2, it also decreases each slice/partition join time duo to reducing unique key ratio.
Considering current DDR size in U280, the experienced left table size for solution transition is about TPC-H SF20. That is to say, when dataset scale is smaller than TPC-H SF20, we recommend using solution 1, and cutting right table into small slices with scale close to TCP-H SF1. when dataset scale is bigger than TPC-H SF20, user can refer to the table below to determine solution 1 or solution 2.
| Left Table | Right Table | solution | ||
| column num | scale factor | column num | scale factor | |
| 2 | <=8 | 3 | >20 | 1 |
| 2 | > 8 | 3 | >20 | 2 |
| 4 | <20 | 4 | >20 | 1 |
| 4 | >20 | 4 | >20 | 2 |
| 5 | <20 | 5 | >20 | 1 |
| 5 | >20 | 5 | >20 | 2 |
| 7 | <20 | 7 | >20 | 1 |
| 7 | >20 | 7 | >20 | 2 |
We test some cases with different input entries. After profiling performance under both solutions, Please note that all the testing cases pay attention to dataset with right table having a large scale (>=SF20). When left/right table in different columns, kernel will show different throughputs.
class xf::database::gqe::Aggregator¶
#include "xf_database/gqe_aggr.hpp"
Overview¶
Methods¶
Aggregator¶
Aggregator (std::string xclbin)
construct of Aggregator .
Parameters:
| xclbin | xclbin path |
aggregate¶
ErrCode aggregate ( Table& tab_in, std::vector <EvaluationInfo> evals_info, std::string filter_str, std::string group_keys_str, std::string output_str, Table& tab_out, AggrStrategyBase* strategyImp = nullptr )
aggregate function.
Usage:
err_code = bigaggr.aggregate(tab_l, //input table
{{"l_extendedprice * (-l_discount+c2) / 100", {0, 100}},
{"l_extendedprice * (-l_discount+c2) * (l_tax+c3) / 10000", {0, 100, 100}}
}, // evaluation
"l_shipdate<=19980902", //filter
"l_returnflag,l_linestatus", // group keys
"c0=l_returnflag, c1=l_linestatus,c2=sum(eval0),c3=sum(eval1)", // mapping
tab_c, //output table
sptr); //strategy
Input filter_str like “19940101<=o_orderdate && o_orderdate<19950101”, o_orderdate and o_orderdate must be exsisted colunm names in input table when no filter conditions, input “”
Input evaluation information as a struct EvaluationInfo , creata a valid Evaluation struct using initializer list, e.g. {“l_extendedprice * (-l_discount+c2) / 100”, {0, 100}} EvaluationInfo has two members: evaluation string and evaluation constants. In the evaluation string, you can input a final division calculation. Divisor only supports: 10,100,1000,10000 In the evaluation constants, input a constant for each column, if no constant, like “l_extendedprice” above, input zero.
Input Group keys in a string, like “group_key0, group_key1”, use comma as seperator
Output strings are like “c0=tab_in_col1, c1=tab_in_col2”, when contains several columns, use comma as seperator
StrategyImp class pointer of derived class of AggrStrategyBase .
Parameters:
| tab_in | input table |
| evals_info | Evalutaion information |
| filter_str | filter condition |
| group_keys_str | group keys |
| out_ptr | output list, output1 = tab_a_col1 |
| tab_out | result table |
| strategyImp | pointer to an object of AggrStrategyBase or its derived type. |
In GQE Aggregation L3 layer, all solutions are listed below:
- solution 0: Hash Aggregate, only for testing small datasets.
- solution 1: Horizontally Cut + Pipelined Hash Aggregation
- solution 2: Hash Partition + Pipelined Hash aggregation
In solution 1, first input table is horizontally cut into many slices, then do aggregation for each slice, finally merge results together. In solution 2, first input table is hash partitioned into many hash partitions, then do aggregation for each partition (no merge in last). Comparing the two solutions, solution 1 introduces extra overhead for CPU merging, while solution 2 added one more kernel(hash partition) execution time. In summary, when input table has a high unique-ratio, solution 2 will be more beneficial than solution 1. After profiling performance using inputs with different unique key ratio, we get the turning point.
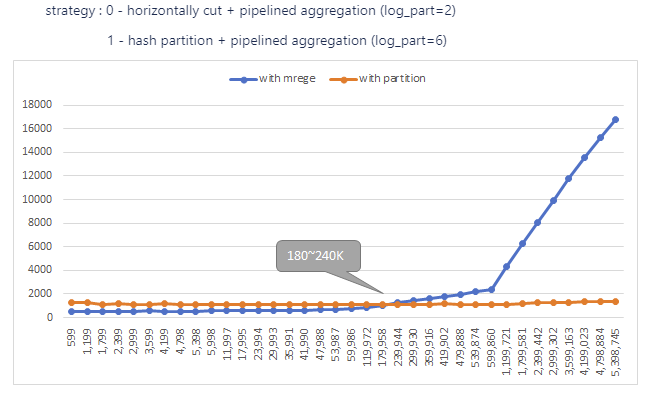
In this figure, it shows when unique key number is more than 180K~240K, we can switch from solution 2 to soluiton 3.
Others: 1) Hash Partition only support max 2 keys, when grouping by more keys, use solution 2 2) In solution 1, make one slice scale close to TPC-H SF1. 3) In solution 2, make one partition scale close to TPC-H SF1.