Internals of Direct-Group-Aggregate¶
This document describes the structure and execution of Direct-Aggregate, implemented as directGroupAggregate function.
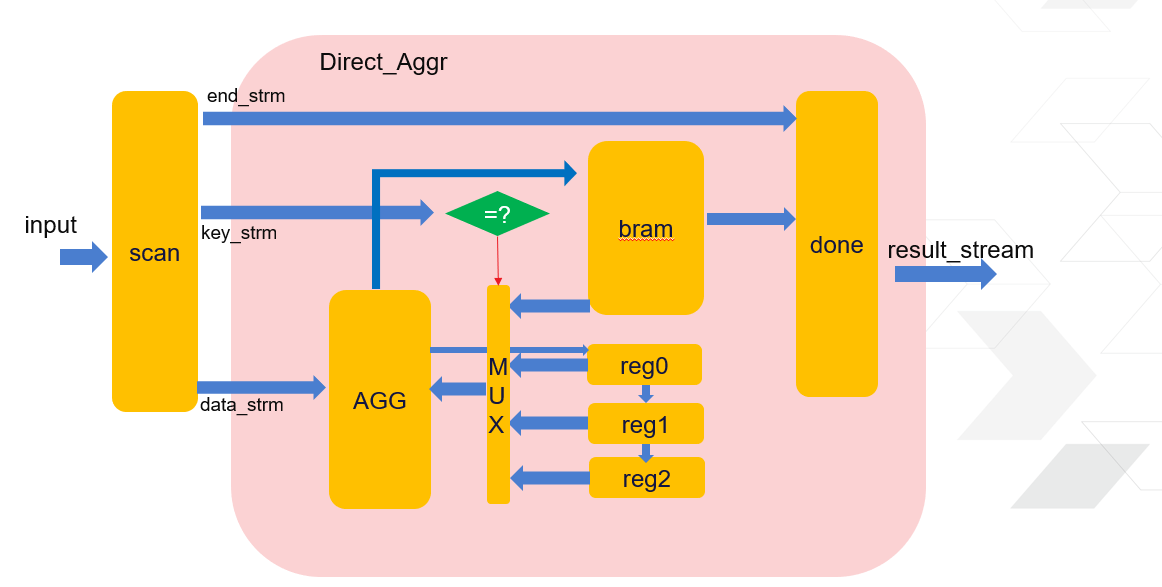
The Direct-Aggregate primitive is a single processing unit which can calculate group aggregate efficiently. Current design uses 1 input channel through which a pair of key and payload can be passed in each cycle. When there is more than 1 input channel, user could duplicate the PU calculate the final result on the host side to reach the goals.
Attention
Applicable conditions:
1. The data width of combined key and payload is configurable, while distinct and on-chip storage scale linear relationship. So the recommending use case is that the width of the key is not large and key values are closely continuous. DIRECTW is the low significant bit of the key and is used as the addressing space for the aggregate. For example when the width of Combined key is 200 bits, but only the low 12 bits is significant, the depth of on-chip storage resource will be 4K.This design introduces some flexibility over addressing directly with a 200-bit key value.
2. There are 8 functions for calculating the payload. They are MAX, MIN ,SUM, COUNTONE, AVG, VARIANCE, NORML1, NORML2 Each one is represented by input parameter:
- xf::database::AOP_MAX
- xf::database::AOP_MIN
- xf::database::AOP_SUM
- xf::database::AOP_COUNTONE
- xf::database::AOP_MEAN
- xf::database::AOP_VARIANCE
- xf::database::AOP_NORML1
- xf::database::AOP_NORML2
3. The primitive provide two APIs: one API provides a template defined aggregate function which means the calculation function cannot change in runtime; Another API provides a runtime programmable solution and it can easily change aggregate functions by changing its OP when calling API.
Caution
The width of significant bits in group key is limited and pre-difined. It will consume more FPGA internal memory such as BRAM and URAM if large significant bit is set.
This directAggregate primitive has only one port for key input and one port for payload input.
If your tables are joined by multiple key columns or has multiple columns as payload,
please use combineUnit to merge the column streams, and
use splitUnit to split the output to columns.