CSCMV Overview¶
The CSCMV operation is implemented by a group of kernels connected via AXI STREAM interfaces.
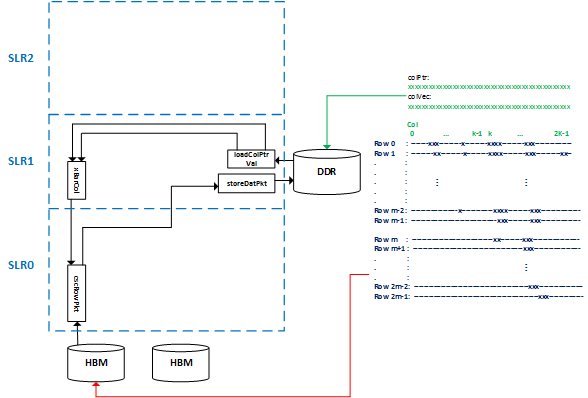
- The
loadColPtrValkernel reads the column vector and pointer entries from DDR and send them to thexBarColkernel to select corresponding column vector entries for NNZs. - The
cscRowPktkernel reads the value and row indices of NNZs from one HBM channel and mulplies the values with their corresponding column entries and accumulates the results along the row indices. - The result row vector entries are sent to
storeDatPktkernel to be written back to DDR.
Note
Only one HBM channel is implemented to compute a block of sparse matrix vector multiplication results. Future versions may support multiple HBM channels with each channel storing part of the sparse matrix data.
- Each HBM channel connects to its own computation path to allow multiple blocks of sparse matrix being processed in parallel.
- The
dispColmodule implemented as L1 primitive will be used to distribute the column vector entries accross multiple HBM channels, hence multiple computation paths for supporting this parallelism. - Design with multiple kernels connected via AXI STREAM interfaces allows you to control the placement of each kernel in the most suitable SLRs and avoid congestions at the routing stage.