XRT Controlled Kernel Execution Models¶
XRT manages a few well-defined kernel execution models by hiding the implementation details from the user. The user executes the kernel by OpenCL or native XRT APIs, such as clEnququeTask API or xrt::run class object, without the need of handling the control interface of the kernels explicitly inside the host code.
In HLS flow, depending on the pragma embedded inside the kernel code, the HLS generates RTL that resonates with XRT supported models. However, for RTL kernel, as the user has the flexibility to create kernel the way they want, it is important for RTL user to understand the XRT supported execution model and design their RTL kernel interface accordingly in order to take advantage of the automatic execution flow managed by the XRT.
At the low level, the kernels are controlled by the XRT through the control and status register that lies on the AXI4-Lite Slave interface. The XRT managed kernel’s control and status register is mapped at the address 0x0 of the AXI4-Lite Slave interface.
The two primary supported excution models are:
- Sequential execution model
- Pipelined execution model
Below we will discuss each kernel execution model in detail.
Sequential Execution Model¶
Sequential execution model is legacy (prior to 2019.1 release) default execution model supported through the HLS flow. The user can create this implemtation by specifying AP_CTRL_HS pragma at the kernel interface.
The idea of sequentially executed model is the simple one-point synchronization scheme between the host and the kernel using two signals: ap_start and ap_done. This execution mode allows the kernel only be restarted after it is completed the current execution. So when there are multiple kernel execution requests from the host, the kernel gets executed in sequential order, serving only one execution request at a time.
Mode of operation
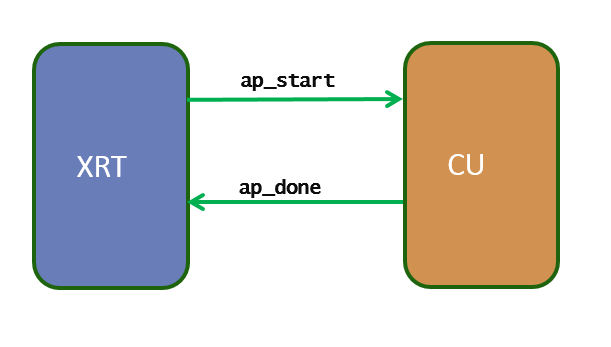
- The XRT driver writes a 1 in ap_start to start the kernel
- The XRT driver waits for ap_done to be asserted by the kernel (guaranteeing the output data is fully produced by the kernel).
- Repeat 1-2 for next kernel execution
Assume there are three concurrent kernel execution requests from the host. The kernel executions will happen sequentially as below, serving one request at a time
START1=>DONE1=>START2=>DONE2=>START3=>DONE3
Control Signal Topology
The signals ap_start and ap_done must be connected to the AXI_LITE control and status register (at the address 0x0 of the AXI4-Lite Slave interface) section to specific bits.
| Bit | Signal name | Description |
|---|---|---|
| 0 | ap_start | Asserted by the XRT when kernel can process the new data |
| 1 | ap_done | Asserted by the kernel when it is finished producing the output data |
Pipelined Execution Model¶
Pipelined execution model is current default execution model supported through the HLS flow.
The kernel is implemented through AP_CTRL_CHAIN pragma. The kernel is implemented in such a way it can allow multiple kernel executions to get overlapped and running in a pipelined fashion. To achieve this host to kernel synchronization point is broken into two places: input synchronization (dictated by the signals ap_start and ap_ready) and output synchronization (ap_done and ap_continue). This execution mode allows the kernel to be restarted even if the kernel is working on the current (one or more) execution(s). So when there are multiple kernel execution requests from the host, the kernel gets executed in a pipelined or overlapping fashion, serving multiple execution requests at a time.
Mode of operation
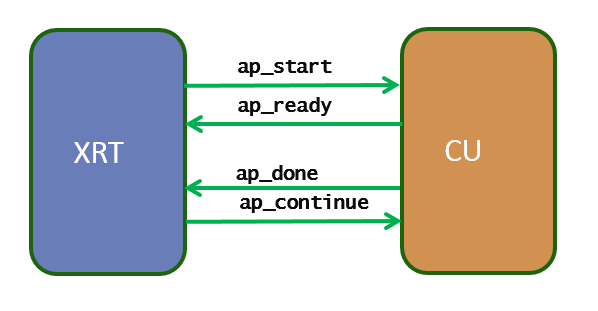
Input synchronization
- The XRT driver writes a 1 in ap_start to start the kernel
- The XRT driver waits for ap_ready to be asserted by the kernel (guaranteeing the kernel is ready to accept new data for next execution, even if it is still working on the previous execution request).
- The XRT driver writes 1 in ap_start to start the kernel operation again
Assume there are five concurrent kernel execution requests from the host and the kernel can work on three execution requests in a pipelined fashion. The kernel executions will happen sequentially as below, serving maximum three requests at a time.
START1=>START2=>START3=>DONE1=>START4=>DONE2=>START5=>DONE3=>DONE4=>DONE5
Note: As noted in the above sequence, the pipelined execution model only applicable when the kernel produces the outputs for the pending requests in-order. Kernel servicing the requests out-of-order cannot be supported by through this execution model.
Output synchronization
- The XRT driver waits for ap_done to be asserted by the kernel (guaranteeing the output data is fully produced by the kernel).
- The XRT driver writes a 1 in ap_continue to keep kernel running
The input and output synchronization occurs asynchronously, as a result, multiple executions are performed by the kernel in an overlapping or pipelined fashion.
Control Signal Topology
The signals ap_start, ap_ready, ap_done, ap_continue must be connected to the AXI_LITE control and status register (at the address 0x0 of the AXI4-Lite Slave interface) section to specific bits.
| Bit | Signal name | Description |
|---|---|---|
| 0 | ap_start | Asserted by the XRT when kernel can process the new data |
| 1 | ap_done | Asserted by the kernel when it is finished producing the output data |
| 3 | ap_ready | Asserted by the kernel when it is ready to accept the new data |
| 4 | ap_continue | Asserted by the XRT to allow kernel keep running |
Host Code Consideration
To execute the kernel in pipelined fashion, the host code should be able to fill the input queue with multiple execution requests well ahead to take the advantage of pipelined nature of the kernel. For example, considering OpenCL host code, it should use out-of-order command queue for multiple kernel execution requests. The host code should also use API clEnqueueMigrateMemObjects to explicitly migrate the buffer before the kernel execution.
Note regarding the User-managed kernels¶
The RTL kernels which are implemented as any other arbitrary execution models must be managed explicitly by the user using native XRT API. The xrt::ip class and its member functions are needed to control/read/write these types of kernels. See the API details in https://xilinx.github.io/XRT/master/html/xrt_native_apis.html#user-managed-kernel
Note regarding the Un-managed kernels¶
The kernels can also be implemented without any control interfaces. As these kernels purely works on the availability of the data at its interface, they cannot be controlled (executed) from the host-code. In general these kernels are only communicating through the stream, they only work when the data is available at their input through the stream, and they stall when there is no data to process, waiting for new data to arrive through the stream to start working again.
These kernels may have scalar inputs and outputs connected through the AXI4-Lite Slave interface. The user can read/write to those kernels by native XRT APIs (xrt::ip::read_register, xrt::ip::write_register).