Third-party Inference Stack Integration¶
Vitis™ AI provides integration support for TVM, ONNX Runtime, and TensorFlow Lite workflows. The developers can leverage these workflows through the subfolders. A brief description of these workflows is as follows:
TVM¶
TVM.ai is an Apache Software Foundation project and inference stack that can parse machine learning models from almost any training framework. The model is converted to an intermediate representation (TVM relay), and the stack can then compile the model for various targets, including embedded SoCs, CPUs, GPUs, and x86 and x64 platforms. TVM incorporates an open-source programmable-logic accelerator, the VTA, created using the AMD HLS compiler. TVM supports partitioning a graph into several sub-graphs. These sub-graphs can be targeted to specific accelerators within the target platform (CPU, GPU, VTA, and so on) to enable heterogeneous acceleration.
The VTA is not used for the published Vitis AI - TVM workflow, instead opting to integrate the DPU for offloading compiled subgraphs. Subgraphs that can be partitioned for execution on the DPU are quantized and compiled by the Vitis AI compiler for a specific DPU target. In contrast, the TVM compiler compiles the remaining subgraphs and operations for execution on LLVM.
For additional details of Vitis AI - TVM integration, refer here.
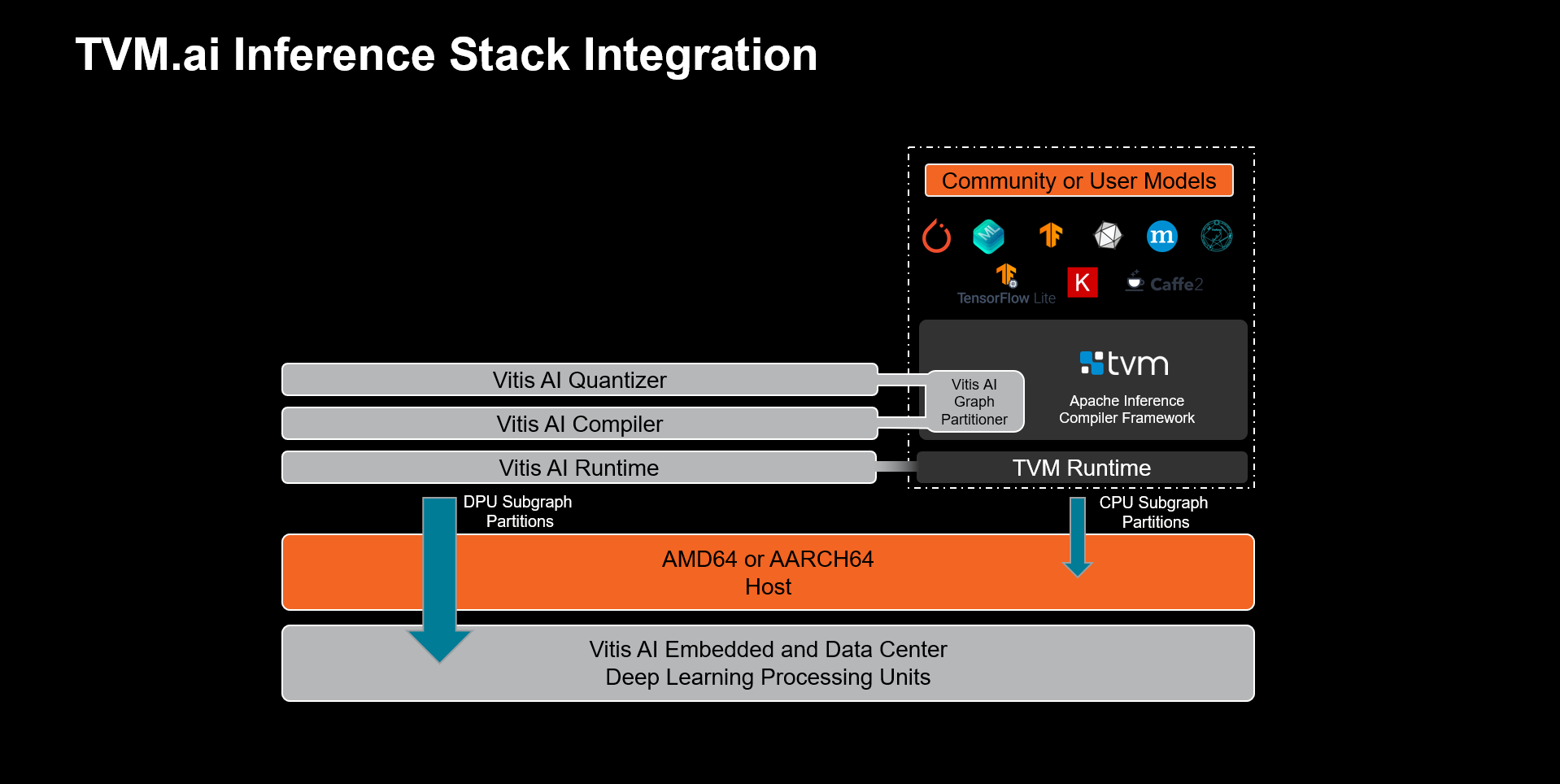
Vitis-AI Integration With TVM.ai¶
ONNX Runtime¶
ONNX Runtime was devised as a cross-platform inference deployment runtime for ONNX models. ONNX Runtime provides the benefit of runtime interpretation of models represented in the ONNX intermediate representation (IR) format.
The ONNX Runtime Execution Provider framework enables the integration of customized tensor accelerator cores from any “execution provider.” Such “execution providers” are typically tensor acceleration IP blocks integrated into an SoC by the semiconductor vendor. Specific subgraphs or operations within the ONNX graph can be offloaded to that core based on the advertised capabilities of that execution provider. The ability of a given accelerator to offload operations is presented as a listing of capabilities to the ONNX Runtime.
Starting with the release of Vitis AI 3.0, we have enhanced Vitis AI support for the ONNX Runtime. The Vitis AI Quantizer can now be leveraged to export a quantized ONNX model to the runtime where subgraphs suitable for deployment on the DPU are compiled. Remaining subgraphs are then deployed by ONNX Runtime, leveraging the AMD Versal™ and Zynq™ UltraScale+™ MPSoC APUs, or the Ryzen™ AI AMD64 cores to deploy these subgraphs. The underlying software infrastructure is named VOE or “V itis AI O NNX Runtime E ngine”. Users should refer to the section “Programming with VOE” in UG1414 for additional information on this powerful workflow.
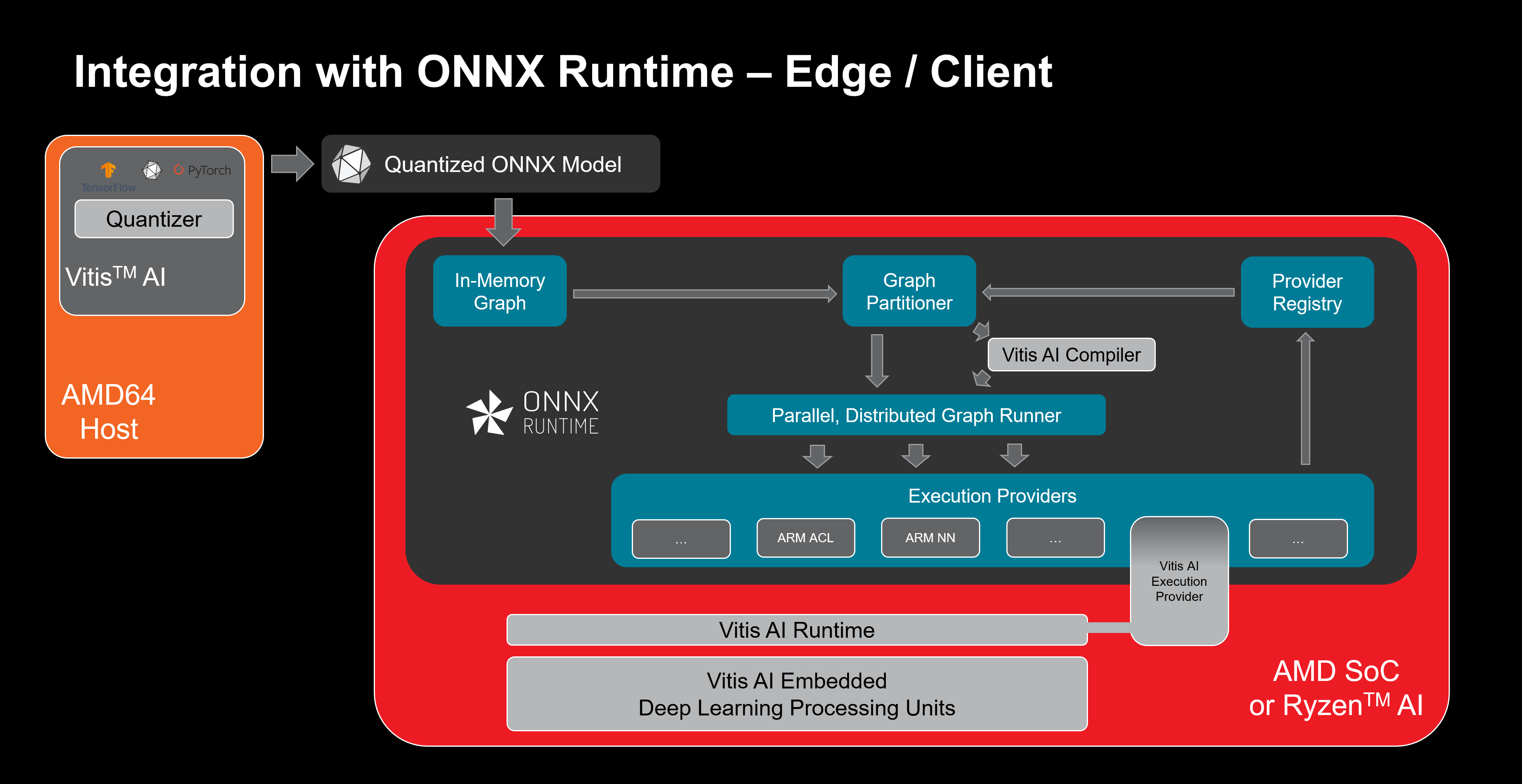
Vitis-AI Integration With ONNX Runtime (Edge & Client)¶
For Ryzen™ AI targets which leverage the AMD XDNA™ adaptable AI architecture, the Vitis AI Execution Provider is published here.
TensorFlow Lite¶
TensorFlow Lite has been a preferred inference solution for TensorFlow users in the embedded space for many years. TensorFlow Lite provides support for embedded ARM processors, as well as NEON tensor acceleration. TensorFlow Lite provides the benefit of runtime interpretation of models trained in TensorFlow Lite, implying that no compilation is required to execute the model on target. This has made TensorFlow Lite a convenient solution for embedded and mobile MCU targets which did not incorporate purpose-built tensor acceleration cores.
With the addition of TensorFlow Delegates, it became possible for semiconductor vendors with purpose-built tensor accelerators to integrate support into the TensorFlow Lite framework. Certain operations can be offloaded (delegated) to these specialized accelerators, repositioning TensorFlow Lite runtime interpretation as a useful workflow in the high-performance space.
Vitis AI Delegate support is integrated as an experimental flow in recent releases.
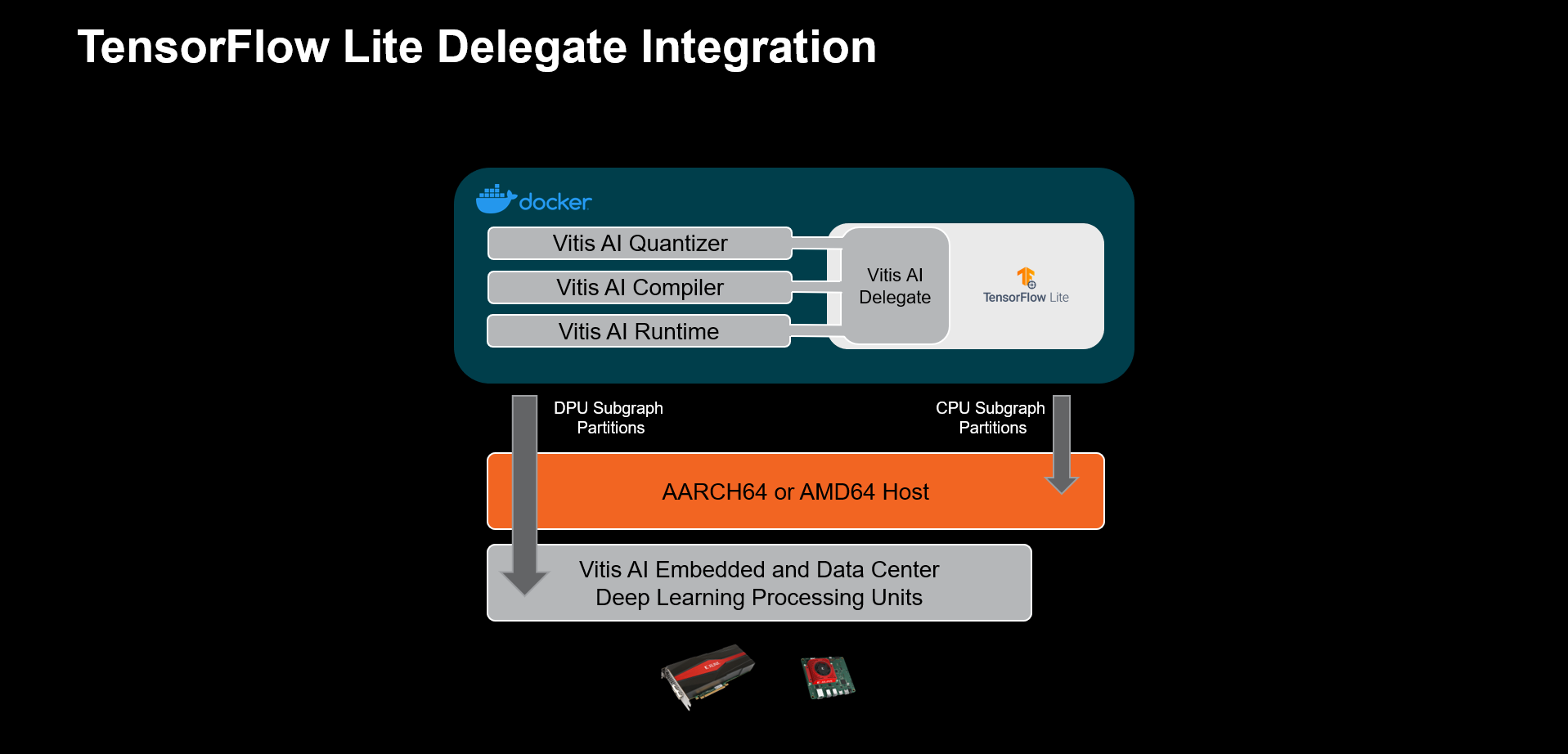
Vitis-AI Integration With TensorFlow Lite¶