AI Engine Runtime Parameter Reconfiguration Tutorial |
Asynchronous Update of Scalar RTP for PL inside a Graph, and Array RTP Update for AI Engine Kernel¶
This step demonstrates:
How an asynchronous runtime scalar parameter can be passed to the PL kernel inside the graph
The Array RTP update for AI Engine kernels
The example is similar to Asynchronous Update of Array RTP, except that an asynchronous scalar runtime parameter is added for the PL kernel inside the graph. The system to be implemented is as follows.
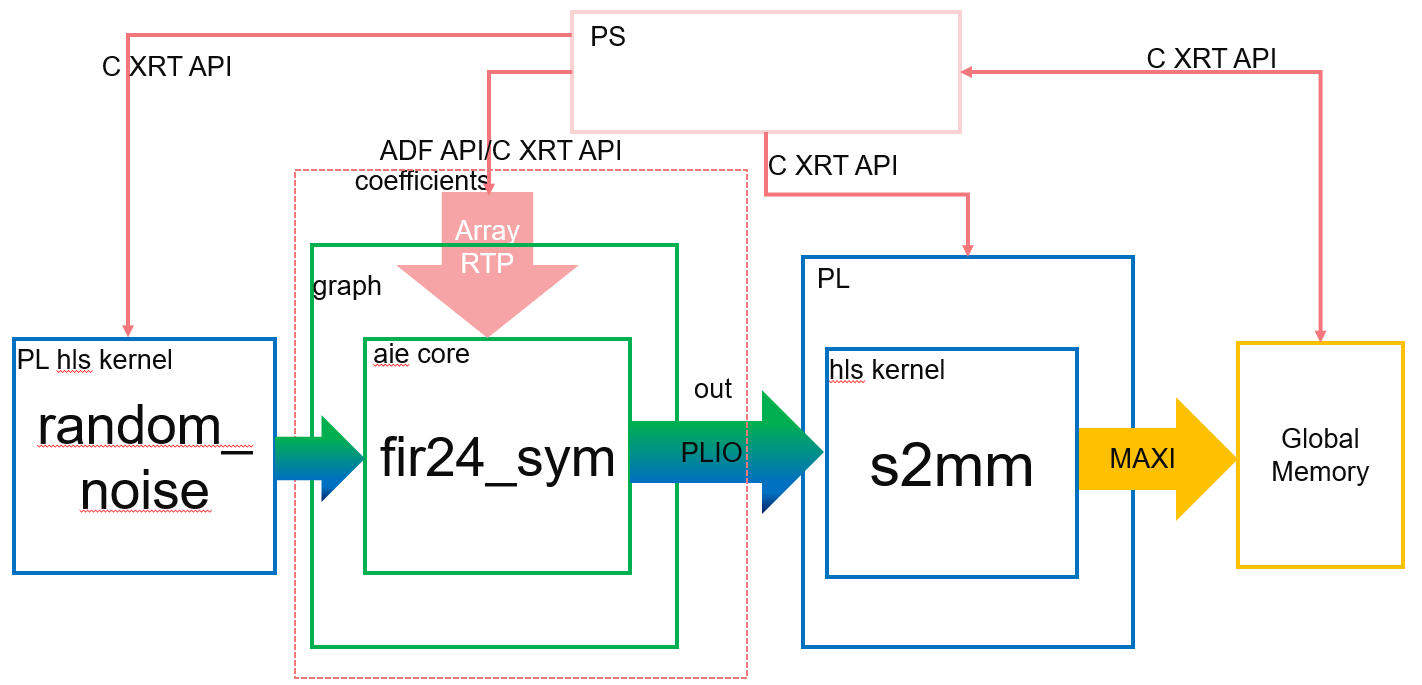
Note: The default working directory for this step is “step4”, unless explicitly specified otherwise.
Review Graph and RTP Code¶
For the PL kernel (random_noise) inside the graph , an additional parameter size has been added, which is different from the free-running kernel in previous step. And a loop is added in the kernel to iterate size times. The code in aie/hls/random_noise.cpp is as follows:
extern "C" void random_noise(hls::stream<std::complex<short> > & out, int size) {
#pragma HLS INTERFACE axis port=out
#pragma HLS INTERFACE s_axilite port=return bundle=control
#pragma HLS INTERFACE ap_ctrl_hs port=return
#pragma HLS interface s_axilite port=size bundle=control
#pragma HLS interface ap_none port=size
for(int i=0;i<size;i++){
...
}
}
Pragma #pragma HLS INTERFACE s_axilite port=return bundle=control indicates that the kernel has an AXI4-Lite interface for block control. Other scalar inputs and global memory addresses are also bundled into this AXI4-Lite interface. Here, the scalar input size is bundled into the AXI4-Lite interface by #pragma HLS interface s_axilite port=size bundle=control for Vitis HLS. Pragma #pragma HLS INTERFACE ap_ctrl_hs port=return indicates the control protocol for the kernel is ap_ctrl_hs, meaning that the kernel has to be explicitly started and polled for completion. This is normally done by the OpenCL API or the XILINX Runtime API, but in this tutorial, for the PL inside graph, the adf API will be introduced to control its execution.
Kernels with runtime parameters must have an AXI4-Lite interface. For asynchronous RTP, it has to be an AXI4-Lite interface with the ap_none protocol. Thus, the following two pragmas are required for the AI Engine compiler to set the correct RTP for the kernel:
#pragma HLS interface s_axilite port=size bundle=control
#pragma HLS interface ap_none port=size
For information about the pragmas and protocals for Vitis HLS, refer to the Vitis HLS User Guide. For information about pragmas for RTP, refer to the Versal ACAP AI Engine Programming Environment User Guide (UG1076).
In the graph definition (aie/graph.h), the RTP declaration and connection are added as follows:
port<direction::in> size;
connect< parameter >(size, async(noisegen.in[0]));
In aie/graph.cpp (for AI Engine simulator), there is an update for size:
gr.init();
//update size -- 1024 for 16 iterations
gr.update(gr.size, 1024);
//run for 16 iterations, update narrow filter coefficients, wait, update wide filter coefficients, run for 16 iterations
gr.update(gr.coefficients, narrow_filter, 12);
gr.run(16); // Run PL kernel kernel once, but 16 iterations for AIE kernel
gr.wait();
gr.update(gr.coefficients, wide_filter, 12);
gr.run(16);
gr.end();
Note: For PL kernels inside a graph, update() needs to be called before run(). In each graph, the run() PL kernel inside the graph will be started once, regardless of the number of iterations set for run(). But in each graph the run() AI Engine kernel will run the number of iterations set for run(). In each graph, wait() means both the AI Engine kernel and the PL kernel inside the graph wait to be completed. Thus, it is your responsibility to ensure the AI Engine and PL kernels inside the graph can start and complete in synchronous mode.
Run AI Engine Compiler and AI Engine Simulator¶
Compile the AI Engine graph (libadf.a) using the AI Engine compiler:
make aie
The corresponding AI Engine compiler command is:
aiecompiler -platform=<PATH by PLATFORM_REPO_PATHS>/xilinx_vck190_es1_base_202020_1/xilinx_vck190_es1_base_202020_1.xpfm -include="./aie" -include="./data" -include="./aie/kernels" -include="./" --pl-axi-lite=true -workdir=./Work aie/graph.cpp
It has an option --pl-axi-lite=true to instruct the AI Engine compiler to generate an AXI4-Lite interface for PL kernels. This is necessary for PL kernels with RTP. By default, --pl-axi-lite is set to false.
After the AI Engine graph (libadf.a) has been generated, verify for correctness using the AI Engine simulator:
make aiesim
Run Hardware Cosimulation and Hardware Flow¶
The Makefile rule targets introduced in Synchronous update of Scalar RTP, Asynchronous Update of Scalar RTP, and Asynchronous Update of Array RTP still apply here. Details about tool options and host code in Synchronous Update of Scalar RTP are similar.
In Linux mode, the following header files are required for the ADF and XRT APIs:
#include "adf/adf_api/XRTConfig.h"
#include "experimental/xrt_kernel.h"
The adf API can still be used to update the RTP for PL kernels inside the graph. Besides using the ADF API to control graph execution, you can also use the XRT API for graph control. In this host code, __USE_ADF_API__ is used to switch between the ADF and XRT APIs. You can modify the Makefile in the sw directory to choose which API to use.
In sw/host.cpp, for the ADF API, the graph update() is used to update the RTP, and the graph run() is used to launch the AI Engine kernels and PL kernels inside graph. But the adf API calls the Xilinx Runtime (XRT) API underneath, and adf::registerXRT() is introduced to build the relationship between them. The code for RTP update and execution by the adf API is as follows:
// update graph parameters (RTP) & run
adf::registerXRT(dhdl, uuid);
int narrow_filter[12] = {180, 89, -80, -391, -720, -834, -478, 505, 2063, 3896, 5535, 6504};
int wide_filter[12] = {-21, -249, 319, -78, -511, 977, -610, -844, 2574, -2754, -1066, 18539};
gr.update(gr.size, 1024);//update PL kernel RTP
gr.update(gr.coefficients, narrow_filter, 12);//update AIE kernel RTP
gr.run(16);//start PL kernel & AIE kernel
gr.wait();
gr.update(gr.coefficients, wide_filter, 12);//Update AIE kernel RTP
gr.run(16);//start AIE kernel
In sw/host.cpp, notice that adf::registerXRT() requires the device handle and UUID of the XCLBIN image. These can be obtained by the Xilinx Runtime (XRT) API:
auto dhdl = xrtDeviceOpen(0);//device index=0
ret=xrtDeviceLoadXclbinFile(dhdl,xclbinFilename);
xuid_t uuid;
xrtDeviceGetXclbinUUID(dhdl, uuid);
Note that the XRT API was used instead of the OpenCL API to manage the PL kernels outside of the graph (s2mm). This execution model is similar to that introduced in Asynchronous Update of Array RTP. The code in sw/host.cpp is as follows:
// Allocate output global memory and map to host memory
xrtBufferHandle out_bohdl = xrtBOAlloc(dhdl, output_size_in_bytes, 0, /*BANK=*/0);
std::complex<short> *host_out = (std::complex<short>*)xrtBOMap(out_bohdl);
// s2mm ip
xrtKernelHandle s2mm_khdl = xrtPLKernelOpen(dhdl, uuid, "s2mm"); // Open kernel handle
xrtRunHandle s2mm_rhdl = xrtRunOpen(s2mm_khdl);
xrtRunSetArg(s2mm_rhdl, 0, out_bohdl); // set kernel arg
xrtRunSetArg(s2mm_rhdl, 2, OUTPUT_SIZE); // set kernel arg
xrtRunStart(s2mm_rhdl); //launch s2mm kernel
// update graph parameters (RTP) & run
...
// wait for s2mm done
auto state = xrtRunWait(s2mm_rhdl);
// Transfer data from global memory in device back to host memory
xrtBOSync(out_bohdl, XCL_BO_SYNC_BO_FROM_DEVICE , output_size_in_bytes,/*OFFSET=*/ 0);
// Post-processing of data
After post-processing the data, release the allocated objects:
gr.end();
xrtRunClose(s2mm_rhdl);
xrtKernelClose(s2mm_khdl);
xrtBOFree(out_bohdl);
xrtDeviceClose(dhdl);
Note that the graph end() is required before calling xrtDeviceClose() for releasing objects that are allocated implicitly for the PL kernel inside the graph.
The XRT API version to control graph exectuion is as follows:
auto ghdl=xrtGraphOpen(dhdl,uuid,"gr");
int size=1024;
xrtKernelHandle noisegen_khdl = xrtPLKernelOpen(dhdl, uuid, "random_noise");
xrtRunHandle noisegen_rhdl = xrtRunOpen(noisegen_khdl);
xrtRunSetArg(noisegen_rhdl, 1, size);
xrtRunStart(noisegen_rhdl);
ret=xrtGraphUpdateRTP(ghdl,"gr.fir24.in[1]",(char*)narrow_filter,12*sizeof(int));
ret=xrtGraphRun(ghdl,16);
ret=xrtGraphWait(ghdl,0);
xrtRunWait(noisegen_rhdl);
xrtRunSetArg(noisegen_rhdl, 1, size);
xrtRunStart(noisegen_rhdl);
ret=xrtGraphUpdateRTP(ghdl,"gr.fir24.in[1]",(char*)wide_filter,12*sizeof(int));
ret=xrtGraphRun(ghdl,16);
You can see that the XRT API to open, run, wait, and RTP update graph are: xrtGraphOpen(), xrtGraphRun(), xrtGraphWait(), xrtGraphUpdateRTP(). For more information about XRT APIs on graphs, see the Versal ACAP AI Engine Programming Environment User Guide (UG1076).
Run the following make command to build the host exectuable file:
make host
Notice the following linker script links the libraries adf_api_xrt and xrt_coreutil. these are necessary for the adf API to work together with the XRT API.
${CXX} -o ../host.exe aie_control_xrt.o host.o -ladf_api_xrt -lgcc -lc -lxilinxopencl -lxrt_coreutil -lpthread -lrt -ldl -lcrypt -lstdc++ -L${SDKTARGETSYSROOT}/usr/lib/ --sysroot=${SDKTARGETSYSROOT} -L$(XILINX_VITIS)/aietools/lib/aarch64.o
Run the following make command to build all necessary files and launch HW cosimulation:
make run_hw_emu
In the Linux prompt, run following commands:
mount /dev/mmcblk0p1 /mnt
cd /mnt
export XILINX_XRT=/usr
export XCL_EMULATION_MODE=hw_emu
./host.exe a.xclbin
To exit QEMU press Ctrl+A, x
For hw mode, run following make command to generate an SD card package:
make package TARGET=hw
In hardware, after booting Linux from the SD card, run following commands in the Linux prompt:
export XILINX_XRT=/usr
cd /mnt/sd-mmcblk0p1
./host.exe a.xclbin
The host code is self-checking. It will check the output data against the golden data. If the output matches the golden data, after the run is complete, it will print the following:
TEST PASSED
Conclusion¶
In this step you learned about:
Asynchronous array RTP
Asynchronous scalar RTP for PL kernel inside the graph
Launching AI Engine simulator, HW cosimulation, and HW
Next, review Asynchronous Array RTP Update and Read for AI Engine Kernel.
Copyright© 2020 Xilinx
XD001