Vitis™ ハードウェア アクセラレーション チュートリアルxilinx.com の Vitis™ 開発環境を参照 |
ビデオたたみ込みフィルター: 概要およびパフォーマンス見積もり¶
この演習では、2D ビデオたたみ込みフィルターについて説明し、ホスト マシン上でのそのパフォーマンスを測定します。これらの測定値は、パフォーマンス ベースラインとして使用します。ハードウェア インプリメンテーションで提供される必要があるアクセラレーションの量は、必要なパフォーマンス制約に基づいて計算されます。次の演習では、FPGA アクセラレータのパフォーマンスを見積もります。次は、この演習で実行する内容をまとめたものです。
ビデオたたみ込みフィルターについて説明します。
ソフトウェアをインプリメントした、たたみ込みフィルターのパフォーマンスを測定します。
必要なアクセラレーションとパフォーマンス制約を使用したソフトウェア インプリメンテーションを計算します。
インプリメンテーション前のハードウェア アクセラレータのパフォーマンスを見積もります。
ビデオ フィルター アプリケーションおよび 2D たたみ込みフィルター¶
ビデオ アプリケーションでは、ノイズのフィルターリング、モーション ブラーの操作、カラーとコントラストの強化、エッジ検出、クリエイティブ エフェクトなどの複数の理由から、さまざまな種類のフィルターを幅広く使用しています。たたみ込みビデオ フィルターは、ピクセルの周囲で何らかの形式でデータを平均化します。これにより、ピクセルが周囲の領域に持つ相関関係の量とタイプが再定義されます。このようなフィルターリングは、ビデオ フレーム内のすべてのピクセルに対して実行されます。
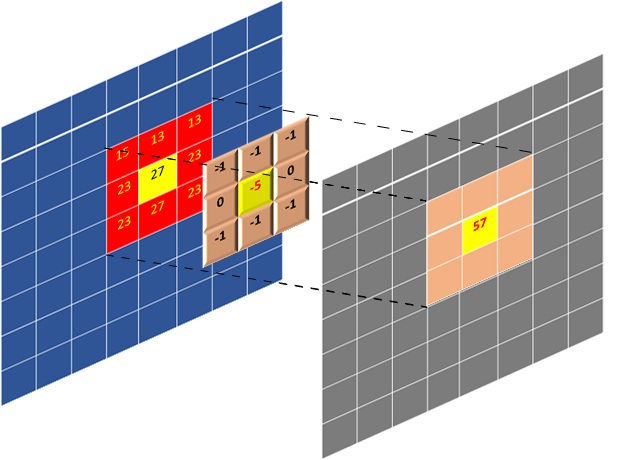
係数の行列により、たたみ込みフィルターが定義されます。たたみ込み演算は、基本的にピクセル セット (特定のピクセルを中心とするフレーム/画像サブ行列) と係数行列で実行される積の合計です。次の図は、ピクセルのたたみ込みを計算する方法を黄色のハイライトで示しています。この場合、フィルターに 3x3 サイズの係数行列があります。この図には、フィルターリング プロセス中に出力画像全体が生成される方法も示されています。生成される出力ピクセルのインデックスは、フィルターリング中の入力ピクセルのインデックス (黄色でハイライト) で表示されます。アルゴリズム用語では、フィルターリングのプロセスに次が含まれます。
入力ピクセルを選択 (次の図で黄色でハイライト)
フィルター係数と同じサイズのサブ行列を抽出
抽出されたサブ行列と係数行列の要素単位の積和を計算
入力ピクセルと同じインデックスの出力画像/フレームに出力ピクセルとして積和を配置
1080p HD ビデオのパフォーマンス要件¶
アプリケーションのパフォーマンス要件は、1080p HD (High Definition) ビデオの標準的なパフォーマンス仕様に基づいて簡単に計算できます。次に、これらの最上位の要件をハードウェア インプリメンテーション要件またはソフトウェア スループット要件の制約に変換できます。毎秒 60 フレーム (FPS) の 1080p HD ビデオの場合、仕様は次のようになります。必要なスループットは毎秒ピクセルで計算されています。
Video Resolution = 1920 x 1080
Frame Width (pixels) = 1920
Frame Height (pixels) = 1080
Frame Rate(FPS) = 60
Pixel Depth(Bits) = 8
Color Channels(YUV) = 3
Throughput(Pixel/s) = Frame Width * Frame Height * Channels * FPS
Throughput(Pixel/s) = 1920*1080*3*60
Throughput (MB/s) = 373 MB/s
60 FPS のパフォーマンスを達成するのに必要なスループットは 373 MB/s (各ピクセルが 8 ビットなので) になります。
ソフトウェア インプリメンテーション¶
このセクションでは、パフォーマンスの制約に基づいてアクセラレーション要件を測定するために使用するベースライン ソフトウェアのインプリメンテーションとパフォーマンス測定について説明します。
たたみ込みフィルターは、一般的な複数レベルの入れ子のループ構造を使用してソフトウェアにインプリメントされます。外側の 2 つのループは、処理するピクセル (各ピクセルごとに反復) を定義します。内側の 2 つのループは、積和 (SOP) 演算と、係数行列とサブ行列 (処理されたピクセルを中心とする画像から選択) 間の実際のたたみ込みフィルターリングを実行します。
ヒント: 指定したピクセルの中心にサブ行列を配置できない境界がある場合は、特別な処理が必要です。このアルゴリズムでは、画像の境界を超えるすべてのピクセルの値は 0 であると想定します。
void Filter2D(
const char coeffs[FILTER_V_SIZE][FILTER_H_SIZE],
float factor,
short bias,
unsigned short width,
unsigned short height,
unsigned short stride,
const unsigned char *src,
unsigned char *dst)
{
for(int y=0; y<height; ++y)
{
for(int x=0; x<width; ++x)
{
// Apply 2D filter to the pixel window
int sum = 0;
for(int row=0; row<FILTER_V_SIZE; row++)
{
for(int col=0; col<FILTER_H_SIZE; col++)
{
unsigned char pixel;
int xoffset = (x+col-(FILTER_H_SIZE/2));
int yoffset = (y+row-(FILTER_V_SIZE/2));
// Deal with boundary conditions : clamp pixels to 0 when outside of image
if ( (xoffset<0) || (xoffset>=width) || (yoffset<0) || (yoffset>=height) ) {
pixel = 0;
} else {
pixel = src[yoffset*stride+xoffset];
}
sum += pixel*coeffs[row][col];
}
}
// Normalize and saturate result
unsigned char outpix = MIN(MAX((int(factor * sum)+bias), 0), 255);
// Write output
dst[y*stride+x] = outpix;
}
}
}
次のスナップショットは、最上位関数が 3 つのコンポーネントまたはチャンネルを持つ画像に対してたたみ込みフィルター関数を呼び出す方法を示しています。ここでは、OpenMP プラグマは、複数スレッドを使用してソフトウェア実行を並列にするために使用されます。チュートリアル ディレクトリから src/host_randomized.cpp と src/filter2d_sw.cpp を開くと、すべてのインプリメンテーションの詳細を確認できます。
#pragma omp parallel for num_threads(3)
for(int n=0; n<numRunsSW; n++)
{
// Compute reference results
Filter2D(filterCoeffs[filterType], factor, bias, width, height, stride, y_src, y_ref);
Filter2D(filterCoeffs[filterType], factor, bias, width, height, stride, u_src, u_ref);
Filter2D(filterCoeffs[filterType], factor, bias, width, height, stride, v_src, v_ref);
}
ソフトウェア アプリケーションの実行¶
ソフトウェア アプリケーションを実行するには、sw_run というディレクトリに移動し、次のようにアプリケーションを起動します。
cd $CONV_TUTORIAL_DIR/sw_run
./run.sh
アプリケーションを起動すると、次のような出力が生成されます。ソフトウェア アプリケーションは、ランダムに生成された一連の画像を処理し、パフォーマンスをレポートします。ここでは、OpenCV などの追加のライブラリ依存を回避するために、ランダムに生成されたイメージを使用しています。ただし、次の演習では、ユーザーが OpenCV 2.4 をマシンにインストールしている場合、ハードウェア インプリメンテーション中に OpenCV ライブラリを使用して画像を読み込むか、ランダムに生成された画像を使用するかのオプションがあります。別のバージョンの OpenCV が必要な場合は、別の API を使用するようにホスト アプリケーションを変更して、ディスクから画像を読み込んで保存できます。
----------------------------------------------------------------------------
Number of runs : 60
Image width : 1920
Image height : 1080
Filter type : 6
Generating a random 1920x1080 input image
Running Software version on 60 images
CPU Time : 24.4447 s
CPU Throughput : 14.5617 MB/s
----------------------------------------------------------------------------
アプリケーション実行は、高精度タイマーを使用してパフォーマンスを測定し、スループットとしてそれをレポートします。この場合、使用されたマシンのスループットは毎秒 14.51 MB でした。マシンの詳細は、次のとおりです。
CPU Model : Intel(R) Xeon(R) CPU E5-1650 v2 @ 3.50GHz
RAM : 64 GB
測定されたパフォーマンスは “2.34 FPS” のみですが、必要なスループットは 60 FPS です。必要なパフォーマンス (60 FPS) を満たすのに必要なアクセラレーションは次のとおりです。
Acceleration Factor = Throughput (Required)/Throughput(SW only)
Acceleration Factor = 373/14.56 = 25.6X
このため、毎秒 60 フレームの処理に必要なパフォーマンスを満たすには、ソフトウェアのインプリメンテーションを 26 倍加速する必要があります。
ハードウェア インプリメンテーション¶
たたみ込みカーネルを詳細に見てみると、パフォーマンス上の制約がある場合にどのようなハードウェア インプリメンテーションが必要かを理解できます。
コア計算は 4 段階の入れ子のループで行われますが、生成された出力ピクセルごとの計算に分割できます。
生成される出力ピクセルに関しては、フィルターのソース コードから、内側の 2 つのループの実行が 1 回完了したときに 1 つの出力ピクセルが生成されることがわかります。
これら 2 つのループは、基本的に係数行列と画像サブ行列で積和を実行します。行列サイズは、係数行列 (15x15) で定義されます。
内側 2 つのループは、サイズ 225 (15x15) のドット積を実行します。つまり、内側 2 つのループは、生成される出力ピクセルごとに 225 の乗累算 (MAC) 演算を実行します。
ベースラインのハードウェア インプリメンテーションのパフォーマンス¶
この最新のカーネル ソース コードを Vitis HLS ツールに渡すと、最もシンプルで簡単なハードウェア インプリメンテーションを達成できます。II=1 で最も内側のループをパイプライン処理するので、サイクルごとに 1 つの乗累算 (MAC) だけが実行されます。パフォーマンスは、MAC に基づいて次のように見積もることができます。
MACs per Cycle = 1
Hardware Fmax(MHz) = 300
Throughput = 300/225 = 1.33 (MPixels/s) = 1.33 MB/s
ここでは、ハードウェア クロック周波数は 300 MHz と想定されています。これは、通常 U200 ザイリンクス Alveo データセンター カードでは、これが Vitis HLS ベースのデザイン フローを使用する場合にサポートされる最大クロック周波数であるためです。パフォーマンスは、ベースライン ハードウェア インプリメンテーションを使用すると 1.33 MB/s になります。たたみ込みフィルターのソース コードからは、スループットを達成するために入力および出力で必要なメモリ帯域幅を見積もることもできます。上記のたたみ込みフィルターのソース コードからは、内側 2 つのループが 1 つの出力ピクセルを計算しつつ、入力で 225 (15*15) の読み込みを実行することがわかります。
Output Memory Bandwidth = Throughput = 1.33 MB/s
Input Memory Bandwidth = Throughput * 225 = 300 MB/s
ベースライン インプリメンテーションでは、ザイリンクス アクセラレーション カード/ボード上の PCIe およびデバイス DDR メモリ帯域幅が 10s (GB/s) だとすると、メモリ帯域幅の要件は非常に小さくなります。前のセクションで説明したように、60FPS の 1080p HD ビデオに必要なスループットは 373 MB/s です。このことから、パフォーマンス要件を満たすためには、次のアクセラレーションが必要です。
Acceleration Factor to Meet 60FPS Performance = 373/1.33 = 280x
Acceleration Factor to Meet SW Performance = 14.5/1.33 = 10.9x
最適化したハードウェア インプリメンテーションのパフォーマンス見積もり¶
上記の計算から、60 FPS を処理するために、ベースライン ハードウェア インプリメンテーションのパフォーマンスを 280 倍向上する必要があることがわかります。向上する方法の 1 つに、内部ループを展開して、パイプライン処理する方法があります。たとえば、15 回反復する最も内側のループを展開すると、パフォーマンスを 15 倍向上できます。この変更によって、ハードウェアのパフォーマンスはソフトウェアのみのインプリメンテーションよりも向上しますが、必要なビデオ パフォーマンスを満たすにはまだ十分ではありません。もう 1 つの方法として、内側の 2 つのループを展開し、パフォーマンスを 15*15=225 (1 サイクルあたり 1 出力ピクセルのスループット) 向上させる方法があります。パフォーマンスとメモリ帯域幅の要件は次のとおりです。
Throughput = Fmax * Pixels produced per cycle = 300 * 1 = 300 MB/s
Output Memory Bandwidth = Fmax * Pixels produced per cycle = 300 MB/s
Input Memory Bandwidth = Fmax * Input pixels read per output pixel = 300 * 225 = 67.5 GB/s
必要な出力メモリ帯域幅はスループットに比例して拡張されますが、入力メモリ帯域幅は大幅に増加しているので、維持できない可能性があります。たたみ込みフィルターを詳しく見ると、入力メモリから 225 (15x15) ピクセルすべてを読み取って処理する必要がないことがわかります。革新的なキャッシュ方式を構築すると、入力メモリ帯域幅の使用を大幅に削減できます。
たたみ込みフィルターは、ステンシル カーネルと呼ばれるカーネルのクラスに属しており、最適化することで入力データの再利用を大幅に増やすことができます。これにより、メモリ帯域幅要件が大幅に削減できる可能性があります。キャッシュ方式を使用すると、必要な入力帯域幅を出力と同じ (約 300 MB/s) にできます。最適化されたデータ再利用方式を使用すると、両方の内側ループが展開された場合、1 つの出力ピクセルを生成するために平均で 1 入力ピクセルのみを読み込む必要があるため、300 MB/s の入力メモリ帯域幅が必要になります。
入力帯域幅は削減できますが、達成されるパフォーマンスはまだ 300 MB/s であり、必要な 373 MB/s に到達しません。これに対処するため、ほかの方法でハードウェアのスループットを向上可能です。その方法の 1 つは、カーネル インスタンスを複製することです。これは計算ユニットとも呼ばれます。異種コンピューティングの場合は、データを並列処理できるように計算ユニット数を増やします。たたみ込みフィルターの場合、すべてのカラー チャンネル (YUV) を別々の計算ユニットで処理できます。カラー チャンネルごとに 1 つずつ、3 つの計算ユニットを使用する場合、パフォーマンス サマリは次のようになります。
Throughput(estimated) = Performance of Single Compute Unit * No. Compute Units = 300 x 3 = 900 MB/s
Acceleration Against Software Implementation = 900/14.5 = 62x
Kernel Latency ( per image on any color channel ) = (1920*1080) / 300 = 6.9 ms
Video Processing Rate = (1/Kernel Latency) = 144 FPS
この演習では、次のことを学びました。
たたみ込みフィルターの基本
ソフトウェアのみのインプリメンテーションのパフォーマンスのプロファイル
ハードウェア インプリメンテーションのパフォーマンスと要件の見積もり
これらのパフォーマンス数値、アーキテクチャの選択、およびインプリメンテーションの詳細を考慮して、次の演習では、カーネル ハードウェアを設計し、これらの見積もり値に非常に近いパフォーマンスを提供するアクセラレーションされたアプリケーションを使用する方法を示します。
次の演習モジュール: 2-D ビデオたたみ込みフィルター用のハードウェア カーネル モジュールの設計と解析
Copyright© 2020-2022 Xilinx