Vitis™ ハードウェア アクセラレーション チュートリアルxilinx.com の Vitis™ 開発環境を参照 |
カーネルのインプリメント¶
この演習では、4 個、8 個、および 16 個のワードを並列処理する最適化されたカーネルを作成します。100,000 個のドキュメントすべて (1.4 GB) を、ホスト CPU からカーネルに 1 つのバッファーを使用して送信します。
Bloom4x: 4 ワードを並列処理するカーネル インプリメンテーション¶
4 ワードを並列処理するには、32 ビット * 4 = 128 ビットが並列で必要ですが、データは連続しているので、512 ビットの DDR にアクセスする必要があります。この場合、必要なメモリ アクセス回数は少なくなります。
次のインターフェイス要件を使用して、カーネルを作成します。
DDR に格納されている複数のワードを 512 ビットの DDR アクセスとして読み出します。これは、DDR に 1 回アクセスするたびに 16 ワード読み出すことと等価です。
複数のフラグを DDR に 512 ビットの DDR アクセスとして書き込みます。これは、DDR に 1 回アクセスするたびに 32 フラグを書き込むことと等価です。
4 ワードを並列して計算します。各ワードには、2 つの
MurmurHash2関数が必要です。サイクルごとに 4 ワードのハッシュ (2 つの
MurmurHash2関数) 関数を計算します。
『Vitis 統合ソフトウェア プラットフォームの資料』 (UG1416) のアプリケーション アクセラレーション開発フローの Vitis ソフトウェア プラットフォームでのアプリケーションのアクセラレーション手法を参照してください。
マクロ アーキテクチャのインプリメンテーション¶
02-bloom/reference_files/compute_score_fpga_kernel.cpp の関数 runOnfpga に移動します。
次の引数を使用して DDR から 512 ビットを受信するようアルゴリズムがアップデートされています。
input_words: 512 ビットの入力データ。output_flags: 512 ビットの出力データ。追加の引数:
bloom_filter: ブルーム係数を含む配列へのポインター。計算するワードの総数。
load_filter: 係数の読み込みをイネーブル/ディスエーブル。係数は 1 回読み込むだけです。
カーネル開発手法の最初の手順では、カーネル コードをロード/計算/ストア パターンの構造に変更する必要があります。これには、次を使用して最上位関数
runOnfpgaを作成します。compute_hash_flags_dataflowにロード、計算、ストア用のサブ関数を追加。これらの関数間でデータを転送するローカル配列または
hls::stream変数。
ソース コードでは、
input_words、output_flags、bloom_filterに次の INTERFACE プラグマが指定されています。#pragma HLS INTERFACE m_axi port=output_flags bundle=maxiport0 offset=slave #pragma HLS INTERFACE m_axi port=input_words bundle=maxiport0 offset=slave #pragma HLS INTERFACE m_axi port=bloom_filter bundle=maxiport1 offset=slave
説明:
m_axi: AXI マスター ポートを指定します。port: AXI インターフェイスにマップする引数の名前を指定します。offset=slave: カーネルの AXI4-Lite スレーブ インターフェイスを介してポインターのベースのアドレスを使用できることを示します。bundle:m_axiインターフェイスの名前を指定します。この例では、input_wordsおよびoutput_flagsはmaxiport0にマップされ、またbloom_filter引数はmaxiport1にマップされます。
関数
runOnfpgaはブルーム フィルター係数を読み込み、ロード、計算、およびストア関数を含むcompute_hash_flags_dataflow関数を呼び出します。02-bloom/cpu_src/compute_score_fpga_kernel.cppファイルの関数compute_hash_flags_dataflowを参照してください。次のブロック図に、計算カーネルとデバイス DDR メモリの接続と、計算ハッシュ ブロックのプロセッシング ユニットへのデータ供給を示します。
カーネル インターフェイスから DDR メモリへの接続は AXI インターフェイスで、入力および出力で最大幅 512 が使用されています。
compute_hash_flags関数の入力には、PARALLELIZATION により 512 以外の幅を使用できます。プロセッシング エレメントの境界で、メモリ インターフェイスの幅とプロセッシング ユニット インターフェイスの幅の差に対処するため、Resize ブロックが挿入されています。Buffer というブロックは、ストリームと AXI の間で変換を実行するメモリ アダプターで、Resize ブロックは、使用する構成に選択された PARALLELIZATION 係数に基づいてインターフェイスの幅を調整します。compute_hash_flags_dataflow関数の入力input_wordsは、AXI インターフェイスを介してグローバル メモリからの 512 ビット バースト読み出しが受信されると読み出され、512 ビット値のストリームdata_from_gmemが作成されます。hls_stream::buffer(data_from_gmem, input_words, total_size/(512/32));
compute_hash_flagsで 4 ワードを並列処理するには 128 ビットが必要なので、data_from_gmemから並列ワードのストリームword_stream(PARALLELIZATION 個のワード) が作成されます。hls_stream::resize(word_stream, data_from_gmem, total_size/(512/32));
関数
compute_hash_flags_dataflowは、並列ワードを計算するためcompute_hash_flags関数を呼び出します。PARALLELIZATION=4の設定だと、compute_hash_flagsの出力であるflag_streamは 4*8 ビット = 32 ビットの並列ワードになります。これは、512 ビット値のストリームをdata_to_memとして作成するのに使用されます。hls_stream::resize(data_to_gmem, flag_stream, total_size/(512/8));
512 ビット値のストリーム
data_to_memは、output_flagsを使用して 512 ビット値として AXI インターフェイスを介してグローバル メモリに書き込まれます。hls_stream::buffer(output_flags, data_to_gmem, total_size/(512/8));
#pragmas HLS DATAFLOWは、タスク レベルのパイプライン処理を有効にするため追加されています。これにより DATAFLOW が有効になり、すべての関数を同時に実行して同時に実行するタスクのパイプラインを作成するよう Vitis 高位合成 (HLS) コンパイラに指示します。void compute_hash_flags_dataflow( ap_uint<512>* output_flags, ap_uint<512>* input_words, unsigned int bloom_filter[PARALLELIZATION][bloom_filter_size], unsigned int total_size) { #pragma HLS DATAFLOW hls::stream<ap_uint<512> > data_from_gmem; hls::stream<parallel_words_t> word_stream; hls::stream<parallel_flags_t> flag_stream; hls::stream<ap_uint<512> > data_to_gmem; . . . . }
マイクロ アーキテクチャのインプリメンテーション¶
最上位関数 runOnfpga を適切なデータ幅およびインターフェイス タイプでアップデートしたので、レイテンシおよびスループットを向上するため最適化するループを特定します。
runOnfpga関数は、maxiport1を使用して DDR からブルーム フィルター係数を読み出し、この係数をbloom_filter_localローカル配列に保存します。この読み出しは、1 回のみ必要です。if(load_filter==true) { read_bloom_filter: for(int index=0; index<bloom_filter_size; index++) { #pragma HLS PIPELINE II=1 unsigned int tmp = bloom_filter[index]; for (int j=0; j<PARALLELISATION; j++) { bloom_filter_local[j][index] = tmp; }
#pragma HLS PIPELINE II=1は、各サイクルでバースト DDR アクセスを開始し、ブルーム フィルターを読み出すために追加されています。bloom_filter_sizeは約 16,000 に固定されているので、予測されるレイテンシは 16,000 サイクルです。これは、HLS 合成後に確認する必要があります。
compute_hash_flags関数内では、ループで 4 ワードを並列に計算するため、入れ子のforループに記述し直されています。void compute_hash_flags ( hls::stream<parallel_flags_t>& flag_stream, hls::stream<parallel_words_t>& word_stream, unsigned int bloom_filter_local[PARALLELISATION][bloom_filter_size], unsigned int total_size) { compute_flags: for(int i=0; i<total_size/PARALLELISATION; i++) { #pragma HLS LOOP_TRIPCOUNT min=1 max=10000 parallel_words_t parallel_entries = word_stream.read(); parallel_flags_t inh_flags = 0; for (unsigned int j=0; j<PARALLELISATION; j++) { #pragma HLS UNROLL unsigned int curr_entry = parallel_entries(31+j*32, j*32); unsigned int frequency = curr_entry & 0x00ff; unsigned int word_id = curr_entry >> 8; unsigned hash_pu = MurmurHash2(word_id, 3, 1); unsigned hash_lu = MurmurHash2(word_id, 3, 5); bool doc_end= (word_id==docTag); unsigned hash1 = hash_pu&hash_bloom; bool inh1 = (!doc_end) && (bloom_filter_local[j][ hash1 >> 5 ] & ( 1 << (hash1 & 0x1f))); unsigned hash2=(hash_pu+hash_lu)&hash_bloom; bool inh2 = (!doc_end) && (bloom_filter_local[j][ hash2 >> 5 ] & ( 1 << (hash2 & 0x1f))); inh_flags(7+j*8, j*8) = (inh1 && inh2) ? 1 : 0; } flag_stream.write(inh_flags); } }
こちらを追加:
#pragma HLS UNROLL内部ループが展開され、ハッシュ機能のコピーが 4 つ作成されます。
Vitis HLS は、外部ループを
II=1でパイプライン処理しようとします。内部ループを展開すると、外部ループを各クロック サイクルで開始でき、4 ワードを並列に計算できます。こちらを追加:
#pragma HLS LOOP_TRIPCOUNTmin=1 max=3500000`HLS 合成後に関数のレイテンシがレポートされます。
Vitis ツール フローを使用したカーネルのビルド¶
次に、Vitis コンパイラを使用してカーネルをビルドします。Vitis コンパイラは、Vitis HLS ツールを呼び出して C++ カーネル コードを RTL カーネルに合成します。レポートを参照し、カーネルがパフォーマンスの目標を満たすためのレイテンシ/スループット要件を満たしているかを確認します。
次のコマンドを使用して、カーネルをビルドします。
cd $LAB_WORK_DIR/makefile; make build STEP=single_buffer PF=4 TARGET=hw_emu
このコマンドは
v++コンパイラを呼び出し、コンパイラが Vitis HLS ツールを呼び出して C++ コードを RTL コードに変換します。生成された RTL コードは、ハードウェア エミュレーションの実行に使用できます。注記: このチュートリアルでは、ハードウェア エミュレーションの実行時間を短縮するため、入力ワードの数は 100 個にしています。
次のコマンドを使用して HLS 合成レポートを Vitis アナライザーで表示します。
vitis_analyzer ../build/single_buffer/kernel_4/hw_emu/runOnfpga_hw_emu.xclbin.link_summary
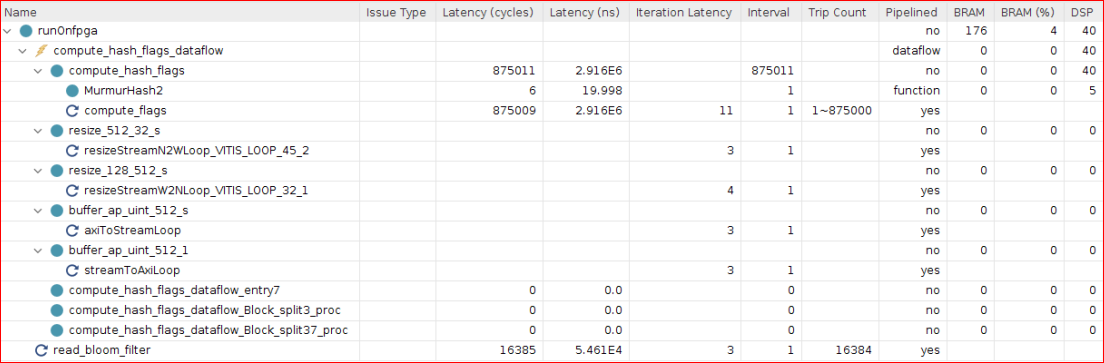
レポートされた
compute_hash_flagsのレイテンシは 875,011 サイクルです。これは、合計 35,000,000 ワードで 4 ワードを並列に計算した場合の結果です。このループの反復回数は 875,000 で、MurmurHash2レイテンシを含めた合計レイテンシ 875,011 サイクルは最適なものです。compute_hash_flags_dataflow関数の [Pinpelined] 列を見ると、dataflowがイネーブルになっています。これは、タスク レベルの並列実行がイネーブルになっており、compute_hash_flags_dataflow関数のサブ関数がオーバーラップして実行されることを示します。レポートされた
read_bloom_filter関数のレイテンシは、bloom_filter maxiポートを使用した DDR からのブルーム フィルター係数の読み出しでは 16,385 です。このループは 16,000 サイクル間反復実行され、ブルームフィルター係数から 32 ビットのデータを読み出します。
HLS レポートから、関数のレイテンシがターゲットを満たしていることを確認できます。ホストと通信する場合は、機能が正しいかどうかを確認する必要もあります。次のセクションでは、初期ホスト コードを確認し、ソフトウェアおよびハードウェア エミュレーションを実行します。
初期ホスト コードの確認¶
アクセラレーション アプリケーション コードの初期バージョンは、元のソフトウェア バージョンの構造に従っています。入力バッファー全体がホストから FPGA に 1 つのトランザクションで転送され、FPGA アクセラレータで計算が実行されます。そして、ポスト プロセスの前に結果が FPGA からホストに戻されます。
次の図に、最初の手順でインプリメントされた順次処理を示します。ホストがデバイスにデータを書き込み、FPGA 上のアクセラレータで計算を実行し、ホストがフラグを読み出すという順番で処理されます。ホストですべてのフラグを受信してから、CPU 上でスコアが計算されます。
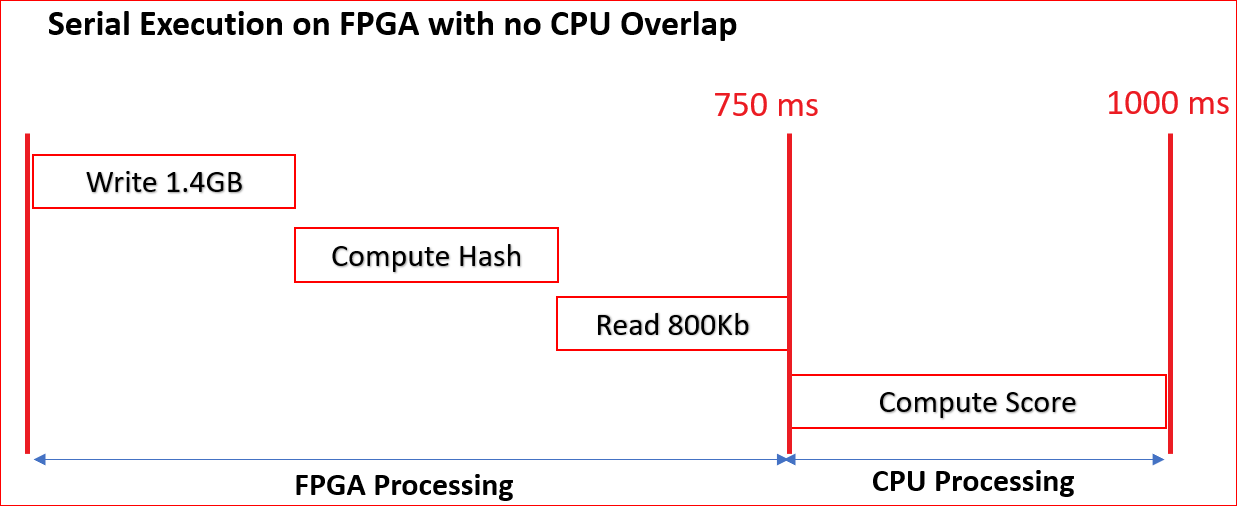
FPGA アクセラレータは、供給された入力ワードのハッシュ値とフラグを計算します。
アクセラレータ カーネルに送信される異なる入力の機能は次のとおりです。
input_doc_words: すべてのドキュメントの 32 ビット ワードを含む入力配列。bloom_filter: 挿入された検索配列ハッシュ値を含むブルーム フィルター配列。total_size: 呼び出されたときに FPGA で処理される合計サイズを表す符号なしint。load_weights: カーネルが複数回起動された場合にbloom_filter配列が FPGA に 1 回だけ読み込まれるようにするブール値。
アクセラレータの出力は次のとおりです。
output_inh_flags: 8 ビット出力の出力配列。8 ビット出力の各ビットは、ワードがブルーム フィルターに存在するかどうか、つまり、CPU でのスコア計算に使用されるかどうかを示します。
ソフトウェア エミュレーション、ハードウェア エミュレーション、およびハードウェア実行¶
次のコマンドを実行して、変更後のアプリケーションでソフトウェア エミュレーションを実行します。
cd $LAB_WORK_DIR/makefile; make run STEP=single_buffer TARGET=sw_emu
ソフトウェア エミュレーションで問題が検出されないことを確認してください。
次のコマンドを使用してハードウェア エミュレーションを実行し、機能が変更されていないことを確認します。
cd $LAB_WORK_DIR/makefile; make run STEP=single_buffer TARGET=hw_emu
「SIMULATION is PASSED」と表示され、問題が検出されなかったことが確認できます。これにより、生成されたハードウェアが機能的に正しいことがわかります。ただし、ハードウェアを FPGA では実行していません。.
注記: このチュートリアル用に、
$LAB_WORK_DIR/xclbin_saveディレクトリにxclbinファイルが用意してあります。hw実行でターゲットがこれらのxclbinファイルを使用するようにするため、SOLUTION=1オプションを追加できます。これらのxclbinファイルは、Alveo U200 カード専用に生成されています。このチュートリアルで使用する各プラットフォームに対して、新しいxclbinファイルを生成する必要があります。次の手順に従って、アプリケーションをハードウェアで実行します。
ハードウェアで 100,000 個のドキュメントを計算します。
cd $LAB_WORK_DIR/makefile; make run STEP=single_buffer ITER=1 PF=4 TARGET=hw
このチュートリアルのソリューションの一部として提供されている
xclbinを使用する場合は、次のコマンドを使用します。cd $LAB_WORK_DIR/makefile; make run STEP=single_buffer ITER=1 PF=4 TARGET=hw SOLUTION=1
4 つのワードを並列に使用するには、
PF=4を使用すると$LAB_WORK_DIR/reference_files/compute_score_fpga_kernel.cppで PARALLELIZATION マクロが 4 に設定されます。ITER=1は、バッファーが 1 回で送信されたこと (1 つのバッファーを使用) を示します。
次の出力が表示されます。
Loading runOnfpga_hw.xclbin Processing 1398.903 MBytes of data Running with a single buffer of 1398.903 MBytes for FPGA processing -------------------------------------------------------------------- Executed FPGA accelerated version | 838.5898 ms ( FPGA 447.964 ms ) Executed Software-Only version | 3187.0354 ms -------------------------------------------------------------------- Verification: PASS
FPGA の合計時間は 447 ms です。これには、ホストから DDR への転送、FPGA での計算、DDR からホストへの転送の時間が含まれます。
100,000 個のドキュメントを計算するのにかかる時間は合計約 838 ms です。
この時点で、プロファイル サマリ レポートおよびタイムライン トレースで、ホストとカーネル間でデータを転送するのにかかる時間、FPGA での計算時間などの情報を確認します。
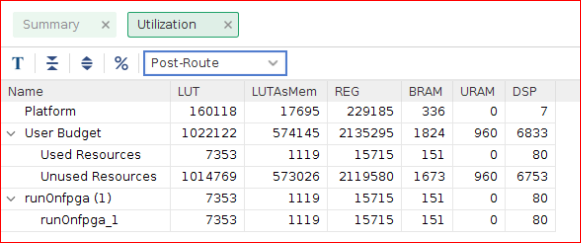
リソース使用量の表示¶
Vitis アナライザーを使用して HLS 合成レポートを表示します。SOLUTION=1 なしでカーネルをビルドし、generate link_summary を生成する必要があります。これはチュートリアルの一部として提供されていません。この手順は省くことができます。
vitis_analyzer $LAB_WORK_DIR/build/single_buffer/kernel_4/hw/runOnfpga_hw.xclbin.link_summaryHLS 合成レポートに、Bloom4x カーネル インプリメンテーションの LUT、レジスタ、およびブロック RAM の使用数が示されます。
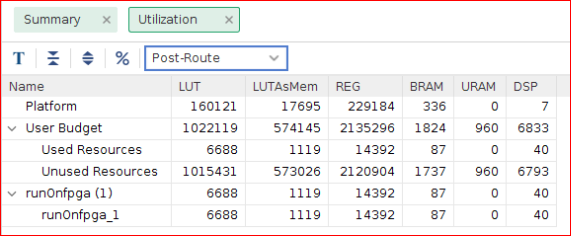
プロファイル サマリ レポートおよびタイムライン トレースの確認¶
Vitis アナライザーを使用して run_summary レポートを表示します。
vitis_analyzer $LAB_WORK_DIR/build/single_buffer/kernel_4/hw/runOnfpga_hw.xclbin.run_summaryプロファイル サマリおよびタイムライン トレース レポートは、FPGA アクセラレーション アプリケーションのパフォーマンスを解析するのに有益です。
プロファイル サマリ レポートの確認¶
[Kernels & Compute Units: Kernel Execution] に、カーネルのエンキューによる合計時間が約 292 ms であることが示されます。

4 ワードが並列に計算されます。アクセラレータは 300 MHz で動作します。計算するワードの総数は 350,000,000 です (各ドキュメントに 3,500 ワード、ドキュメント数 100,000)。
ワード数/(クロック周波数 * カーネルの並列化係数) = 350M/(300M*4) = 291.6 ms。実際の FPGA 計算時間は、理論的な計算時間とほぼ同じです。
[Host Data Transfer: Host Transfer] に、DDR に対するホストの書き込み転送時間は 145 ms、DDR に対するホストの読み出し転送時間は 36 ms であることが示されます。

PCIe の理論的帯域幅 9 GB を使用した場合のホスト書き込み転送は、1399 MB/9 GBps = 154 ms です。
PCIe の理論的帯域幅 12 GB を使用した場合のホスト読み出し転送は、350 MB/9 GBps = 30 ms です。
レポートされた値から、PCIe 転送が最大帯域幅で実行されていることがわかります。
[Kernels & Compute Unit: Compute Unit Stalls] には『外部メモリ ストール 』[External Memory Stalls]) がほとんどないことが示されます。

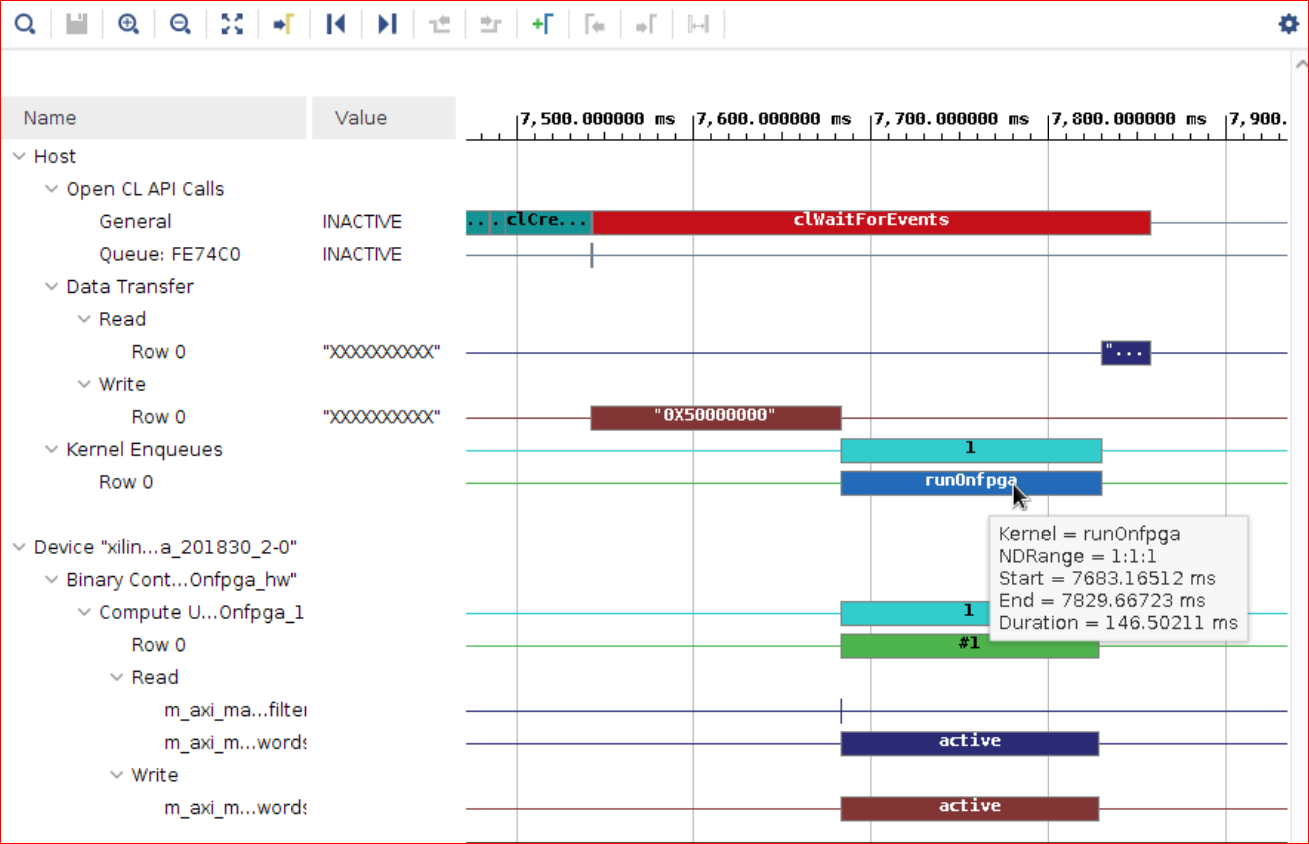
タイムライン トレースの確認¶
タイムライン トレースは、ホストから FPGA、FPGA からホストへのデータ転送を示します。タイムライン トレースから、ホストから FPGA への転送、FPGA での計算、および FPGA からホストへの転送が順次発生することを確認できます。
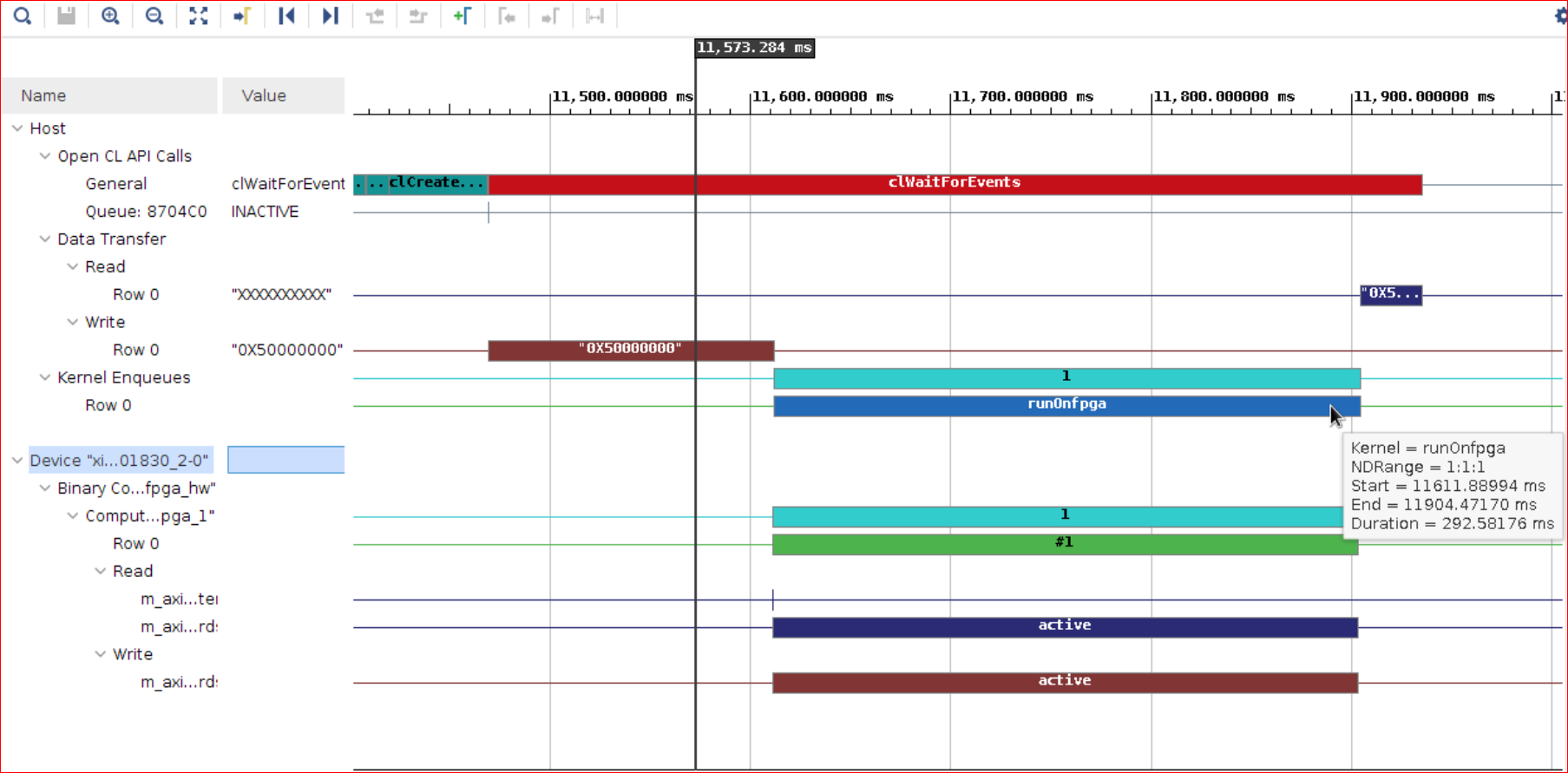
ホストから FPGA へのデータ転送から始まり、FPGA での実行、FPGA からホストへのデータ転送の順次実行があります。
どの時点でも、DDR にアクセスするのはホストまたは FPGA のいずれかのみです。つまり、ホストとカーネルが同じ DDR にアクセスすることによるメモリの競合はありません。
1 つのバッファーを使用することにより、レイテンシが最短となり、最適化されたパフォーマンスが得られます。
達成されたスループット¶
これらの結果から、アプリケーションのスループットは 1399 MB/838 ms = 約 1.66 GB/s であることがわかります。これはアプリケーションをハードウェアで実行する最初の試行であり、ソフトウェアのみのバージョンと比較して 4 倍のパフォーマンスが得られました。
パフォーマンス向上の可能性¶
外部メモリ アクセスに競合はないので、これが 4 ワードを並列に計算するカーネルでの最高のパフォーマンスです。
カーネルは 512 ビットのデータを読み出しますが、4 ワードを並列に計算するために使用されるのは 128 ビットのみです。FPGA にリソースがあるので、カーネルでより多くのワードを計算できる可能性があります。処理するワード数を 8 ワード、16 ワードに増やすことができます。
また、カーネルは最高のパフォーマンスで動作していますが、ホストからの転送が完了するまで待つ必要があります。通常はホストから DDR へ大きなバッファーを送信することをお勧めしますが、非常に大きなバッファーによりカーネルが開始する前に遅延が追加されるので、全体的なパフォーマンスに影響します。
この演習を続行し、8 ワードを並列に計算するカーネルを作成します。次の演習では、ホストとカーネル間のデータの動きを解析し、バッファーを分割してそれがパフォーマンスにどのように影響するかを調べます。
Bloom8x: 8 ワードを並列処理するカーネル インプリメンテーション¶
Bloom4x では、DDR から 512 ビット入力値を読み出し、4 ワードを並列に計算するので、128 ビット入力値のみを使用します。この手順では、8 ワードを並列に計算できるようにします。
これには、コマンド ラインで PF=8 を指定します。次の手順に従って、8 ワードを並列に計算するようにします。
FPGA でのハードウェアの実行¶
次のコマンドを使用して、FPGA 上のハードウェアで実行します。
cd $LAB_WORK_DIR/makefile; make run STEP=single_buffer ITER=1 PF=8次の出力が表示されます。
Single_Buffer: Running with a single buffer of 1398.903 MBytes for FPGA processing
--------------------------------------------------------------------
Executed FPGA accelerated version | 739.4475 ms ( FPGA 315.475 ms )
Executed Software-Only version | 3053.9516 ms
--------------------------------------------------------------------
Verification: PASS
FPGA の合計時間は 315 ms です。これには、ホストから DDR への転送、FPGA での計算、DDR からホストへの転送の時間が含まれます。
予測どおり、8 ワードを並列に計算することにより、ホストとデバイス間のデータ転送も含めた FPGA の合計時間は、447 ms から 315 ms に削減されました。
リソース使用量の表示¶
Vitis アナライザーを使用して HLS 合成レポートを表示します。SOLUTION=1 なしでカーネルをビルドし、link_summary を生成する必要があります。これはチュートリアルの一部として提供されていません。この手順は省くことができます。
vitis_analyzer $LAB_WORK_DIR/build/single_buffer/kernel_8/hw/runOnfpga_hw.xclbin.link_summaryHLS 合成レポートから、Bloom4x カーネル インプリメンテーションと比べて、LUT、レジスタ、およびブロック RAM の使用数が増加したのがわかります。
プロファイル サマリ レポートおよびタイムライン トレースの確認¶
Vitis アナライザーを使用して run_summary レポートを表示します。
vitis_analyzer $LAB_WORK_DIR/build/single_buffer/kernel_8/hw/runOnfpga_hw.xclbin.run_summaryプロファイル サマリ レポートを確認し、メトリクスを Bloom4x と比較します。
[Kernels & Compute Units: Kernel Execution] に、Bloom4x の 292 ms と比較して 146 ms とレポートされます。4 ワードではなく 8 ワードを並列に計算するので、約半分の時間です。
[Host Data Transfer: Host Transfer] セクションには、同じ遅延がレポートされています。
アプリケーションの全体的なパフォーマンスの向上は、カーネルで 4 ワードではなく 8 ワードを並列に計算するようにしたからです。
達成されたスループット¶
これらの結果に基づき、アプリケーションのスループットは 1399 MB/739 ms = 約 1.9 GB/s であることがわかります。ソフトウェアのみのバージョンと比較すると、4 倍のパフォーマンスを得ることができました。
Bloom16x: 16 ワードを並列処理するカーネル インプリメンテーション¶
前の手順では、DDR から 512 ビット入力値を読み出し、8 ワードを並列に計算しました。コマンド ラインで PF=16 を指定すると、16 ワードを並列に計算できます。次の手順に従って、16 ワードを並列に計算するようにします。
FPGA でのハードウェアの実行¶
cd $LAB_WORK_DIR/makefile; make run STEP=single_buffer ITER=1 PF=16次の出力が表示されます。
Processing 1398.903 MBytes of data
Single_Buffer: Running with a single buffer of 1398.903 MBytes for FPGA processing
--------------------------------------------------------------------
Executed FPGA accelerated version | 694.6162 ms ( FPGA 270.275 ms )
Executed Software-Only version | 3052.5701 ms
--------------------------------------------------------------------
Verification: PASS
前の手順と同様、プロファイル サマリ レポートとタイムライン トレース レポートを確認できます。この確認は、ユーザー各自で行ってください。
パフォーマンス向上の可能性¶
この演習では、1 つのバッファーを使用して 4 個、8 個、および 16 個のワードを並列処理する最適化されたカーネルを作成し、レポートを確認しました。タイムライン トレース レポートから、バッファー全体が DDR に転送されるまで、カーネルは計算を開始できないことがわかりました。この転送には、1 つのバッファーを使用すると約 145 ms かかります。Kernel execution time は合計ホスト転送時間よりも短いので、これは大きな遅延です。
次の手順¶
次の演習では、ホストからすべてのドキュメントを一度に送信する代わりに複数のバッファーで送信し、アプリケーションの全体的なアプリケーション パフォーマンスを調べてみます。これには、Bloom8x カーネルおよび Bloom16x カーネルを使用します。
Copyright© 2020-2022 Xilinx