ハードウェア アクセラレーション チュートリアルxilinx.com の Vitis™ 開発環境を参照 |
HBM の概要¶
アルゴリズムの中にはメモリ限界のあるものもあり、DDR ベースの Alveo カードで使用可能な帯域幅 77 GB/s に制限されます。これらのアプリケーションには、HBM (広帯域幅メモリ) ベースの Alveo カードがあり、最大 460 GB/s のメモリ帯域幅がサポートされます。このモジュールでは、DDR と HBM の構造的な違いについて説明し、より高い帯域幅の利点を活用する方法を紹介します。
DDR メモリは、数十年にわたってカードやコンピューターで使用されてきました。FPGA には、メモリ コントローラー、PCB からオンカード DDR モジュールのトレースを制御します。メモリ コントローラーは DDR モジュール内のすべてのメモリを認識します。複数の DDR バンクを持つ Alveo カードの場合、FPGA がアプリケーションで使用されるメモリ コントローラーまたは各 DDR モジュールをインプリメントする必要があります。
HBM は、従来の DDR インプリメンテーションよりも多くの帯域幅と帯域幅/ワットにするために、新しいチップ製造技術を利用したメモリ テクノロジです。メモリ メーカーは、スタックド ダイおよびチップ製造技術によるシリコンを使用して、複数の小型 DDR ベースのメモリを 1 つのより高速なメモリ スタックに積み重ねます。
Alveo インプリメンテーションでは、2 個の 16 層の HBM (HBM2 仕様) スタックが FPGA パッケージに組み込まれ、インターポーザーを使用して FPGA ファブリックに接続されます。このインプリメンテーションには、次が含まれます。
8GB の HBM メモリ
バンクとも呼ばれることもある、それぞれ 256 MB (2Gb) の 32 個の HBM 擬似チャネル (PC)
独立した AXI チャネル (疑似チャネルごとにセグメント分割されたクロスバー スイッチを介して FPGA と通信)
2 つの PC ごとに 2 チャネルのメモリ コントローラー
PC 1 つあたり最大 14.375 GB/s の理論上の帯域幅
HBM サブシステムの理論上の最大帯域幅は 460 GB/s (32*14.375 GB/s) で、達成可能な帯域幅は 420 GB/s (~ 90 % 効率)
各 PC の理論上の最大パフォーマンスは 14.375 GB/s ですが、DDR チャネルの理論上の最大パフォーマンスである 19.25 GB/s を下回ります。DDR パフォーマンスよりも優れたパフォーマンスにするには、HBM サブシステムに複数の AXI マスターを効率的に使用する必要があります。
次の図は、32 個の AXI チャネル (上下の矢印の 32 ペア) からセグメントされたクロスバー スイッチ (赤色でハイライトされた 8 個の白いボックス)、そこから擬似チャネルに接続されるメモリ コントローラーへの HBM サブシステムと FPGA 接続を示しています。
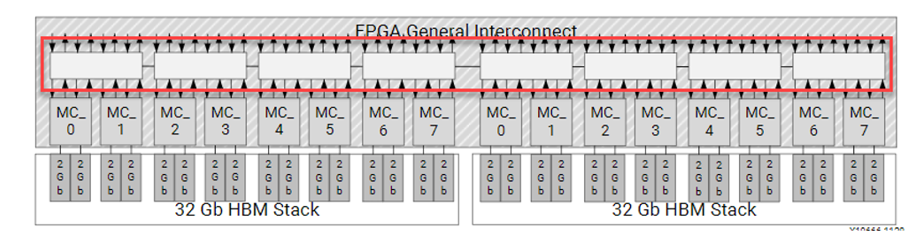
クロスバー スイッチはハード スイッチです。メモリ仕様の簡単なリコンフィギュレーションなど、ほとんど変更のないアプリケーションに優れた柔軟性を提供します。この柔軟性により、このスイッチはロジックをほとんど消費しないので、Alveo デバイスをより多くのカーネル ロジック用に開けたままにしておけます。
セグメントされたクロスバー スイッチは、アプリケーションの実際の HBM パフォーマンスに影響を与えるボトルネックになる可能性があります。スイッチの構造を確認して、スイッチの使用方法をよく理解しましょう。このスイッチは、8 つの 4x4 スイッチ セグメントで構成されています。4x4 セグメントの詳細は、次のとおりです。
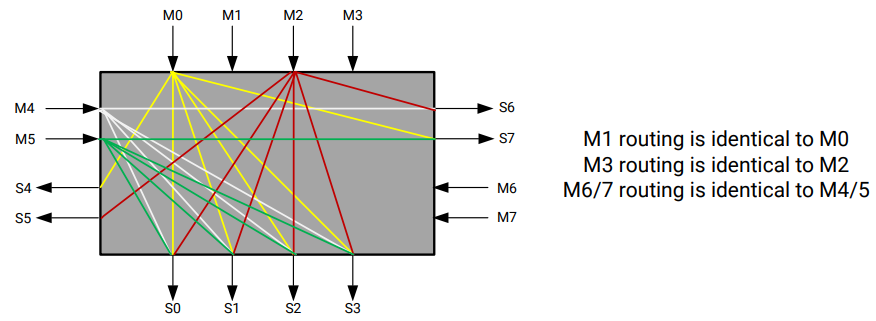
最速の接続は、 AXI チャネルからアライメントされた PC、M0→S0 (0-256MB)、M1->S1(256-512MB) などのメモリ アドレスへの接続で、それぞれ 256 MB のセグメントを持つ 32 の個別の PC へのアクセスに制限されます。セグメントされたクロスバー スイッチを使用すると、パフォーマンスのトレード オフのため、どの AXI マスターでも 8 GB HBM 範囲内のアドレスにアクセスできます。これは、DDR コンフィギュレーション (AXI マスター ポートが DDR0 に接続される場合は、DDR0 内のアドレスのみにアクセスできる) とは異なります。HBM の場合、アドレスがアライメントされた PC の外にあると、セグメント化されたクロスバーを通過して、上に示したローカル 4x4 接続を介して正しい PC に到達するか、または L/R 接続の別の 4x4 スイッチを通過します。1 つのマスター AXI インターフェイスを複数の PC に接続するように指定した場合、特定のカーネル マスター用のメモリ仕様を使用する内部メカニズムがあります。
パフォーマンスは、次の 2 つの要因に影響を受けます。
スイッチの各接続の帯域幅が同じ。
4x4 スイッチから別の 4x4 スイッチへの切り替えにより、レイテンシが増加します。
最速の接続は、AXI マスターから同じスイッチ内の 4 つのアラインされた擬似チャネルの中の 1 つまでの接続になります。複数のマスターが範囲内に広がっている場合、左 ↔ 右のスイッチ構造により帯域幅が飽和される可能性があります。
HBM コントローラーの詳細は、『AXI High Bandwidth Memory Controller v1.0 製品ガイド』を参照してください。
次の手順¶
次の手順では、DDR ベースのアプリケーションを HBM に移行する方法について説明します。
次の手順: アプリケーションの HBM への移行
Copyright© 2020-2022 Xilinx