MLP Kernels¶
The MLP kernels provided by this release include a one CU (Compute Unit) and a 4-CU Fcn designs.
As shown in the Figure 1, 2 L2 level designs are provided by this release, both are targeting Alveo U250
platform. The single Fcn CU design will instantiate a Fcn kernel which is connected to a DDR channel.
The 4-CU Fcn design instantiates the Fcn Kernel, shown on the left side of Figure 1, 4 times to form
4 CUs. Each CU is connected to a dedicated DDR channel.
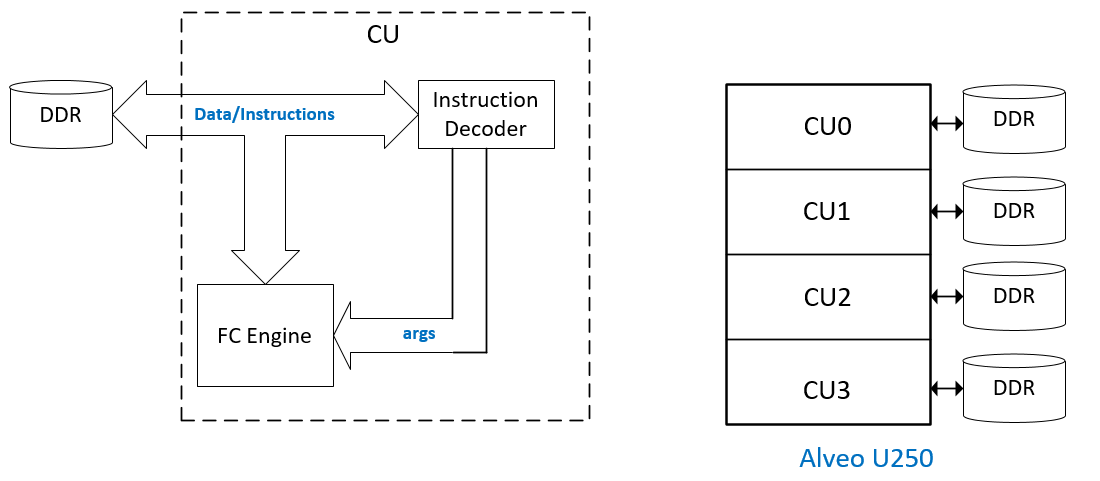
Figure 1. FCN support at L2 level
The Fcn Kernel shown in Figure 1 includes a fully connected (FC) engine implementation that
realizes the dense matrix-matrix multiplication and sigmoid function for each adjacent fully connnected layers.
The chainning of the operations is implemented by the instruction decoder. That is, using instruction
to encode the relationship between the input and output matrices. Each instruction will causes the FC engine to
be triggered once. Each run of the CU can involve several instructions, hence triggering FC
engine several times to complete the inference process of the fully connected neural network.
Users can find the usage of these two designs from directory L2/tests/mlp/fcn_1CU and L2/tests/mlp/fcn_4CU.