Double Precision SpMV Overview¶
As shown in the figure below, the double precision accelerator implemented on the Alveo U280 card consists of a group of CUs (compute units, the instances of Vitis Kernels) connected via AXI STREAMs. In this design, 16 (out ot 32) HBM channels are used to store a sparse matrix NNZ values and their indices. Each HBM channel drives a dedicated computation path involving selMultX and rowAcc to perform the SpMV operation for the portion of the sparse matrix data stored in this HBM channel. In total, 16 SpMV operations are performed simultaneously for different parts of the sparse matrix data.
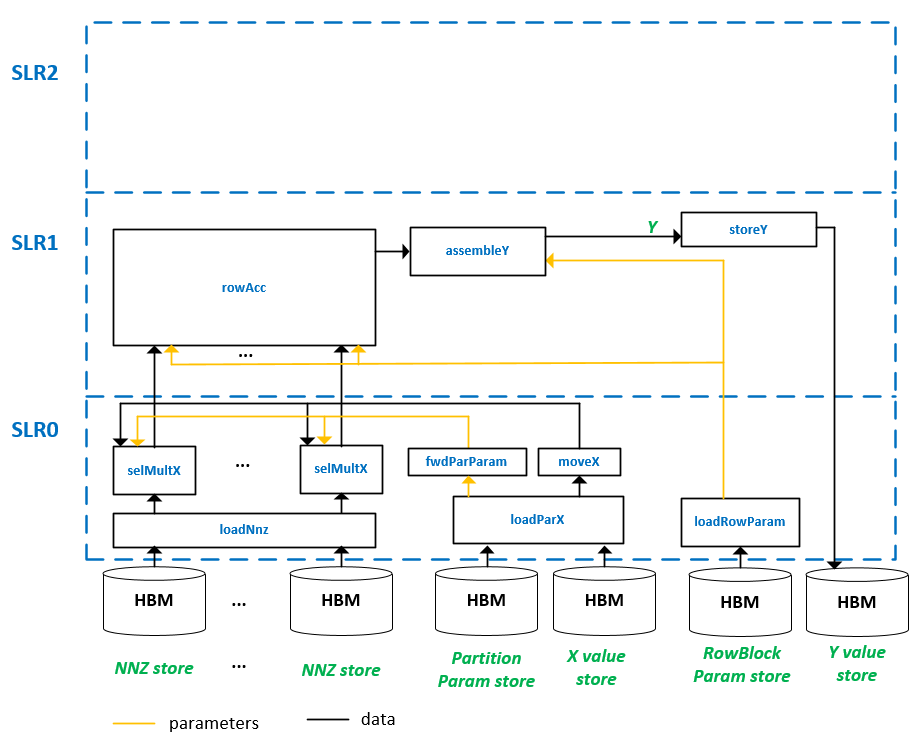
The task of paritioning sparse matrix is done on host via Python code. The information about the partitions are stored in two HBM channels, namely partition parameter store and row block parameter store. The loadParX kernel loads input dense vector and partition information from 2 HBM channels, passes the data to fwdParParam and moveX kernel to distribute the partition information and the X vector to 16 selMultX CUs. The NNZ value and indicies information are loaded by the loadNnz CU and distributed to 16 selMultX CUs. The results of selMultX CUs are accumulated in rowAcc CU and assembled by assembleY CU. Finally, the result vector Y is stored to a HBM channel by storeY CU.
The highlights of this architecture are:
- Using AXI streams to connect a number of CUs (24 CUs in this design) to allow massive parallelism being realized in the hardware
- Using free-run kernel to remove embedded loops and simplify the logic
- Leveraging different device memories to reduce the memory access overhead and meet the computation paths’ data throughput requirements
- Minimanizing the SLR (Super Logic Region) crossing logic to achieve higher clock rate
Although the above hardware architecture offers high computation power, it alone doesn’t provide a guarantee for the high system level performance. To achieve that, the sparse matrix data has to be partitioned evenly across the HBM channels. The following paragraghs present the details of the matrix partitioning strategy implemented in the Python code.
1. Matrix partitioning¶
As illustrated in the figure below, the matrix partitioning algorithm implemnted in the software includes 3 levels of partitioning.
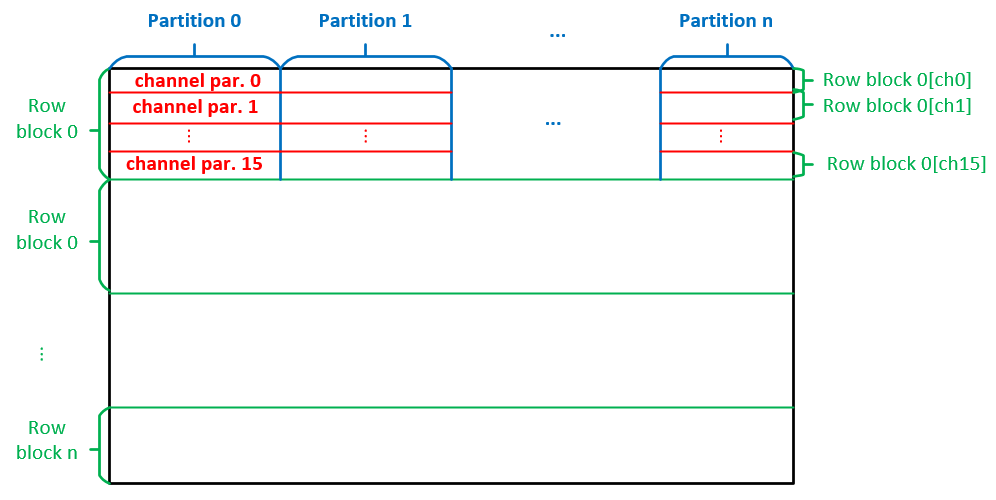
- Partition the matrix along the rows into row blocks. Each row block has less than 4K (configured by SPARSE_maxRows) rows.
- Partiton each row block along the column into partitions. Each partition has less than 4K (configured by SPARSE_maxCols) cols.
- Each partition is divided equally into 16 (configured by SPARSE_hbmChannels) parts, called channel partitions.
- The number of NNZs in each row of the channel partition is padded to multiple of 32 to accommodate double precision accumulation latency (8 cycles, each cycle 4 double precision data entries are processed by
selMultXCU). - Data in each channel partition are stored in row-major order.
Each time a selMultX CU is triggered, a channel partition is processed. Each computation path (16 in total) in the rowAcc CU processes all row blocks for a specific HBM channel.
2. Build and test the design¶
To build and test the design on Linux platform, please make sure your XILINX_VITIS and XILINX_XRT environment variables are set up correctly and point to the corresponding Vitis 2021.1 locations. Once your environment is set up properly, please navigate to the L2/tests/fp64/spmv directory and follow the steps below to run emulation and launch accelerator on Alveo U280.
- To run hardware emulation, please enter following commands. Please replace the $XILINX_VITIS with your Vitis 2021.1 installation location.
make cleanall make run PLATFORM_REPO_PATHS=$XILINX_VITIS/platforms DEVICE=xilinx_u280_xdma_201920_3 TARGET=hw_emu
- To build and launch the hardware accelerator on the Alveo U280, please enter following commands. Please replace the $XILINX_VITIS with your Vitis 2021.1 installation location.
make cleanall make run PLATFORM_REPO_PATHS=$XILINX_VITIS/platforms DEVICE=xilinx_u280_xdma_201920_3 TARGET=hw