Versal Prime -VMK180 Evaluation Kit PCIe TRD Tutorial |
Hardware Architecture of the Accelerator |
Hardware Architecture of the Accelerator¶
Processing Pipeline¶
A memory-to-memory (M2M) pipeline reads video frames from memory, does certain processing, and then writes the processed frames back into memory. A block diagram of the process pipeline is shown in the following figure.
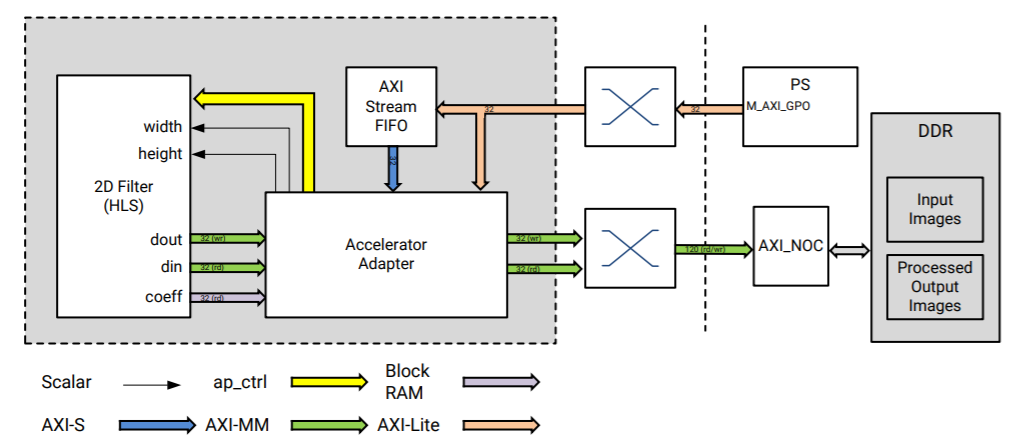
The M2M processing pipeline with the 2D convolution filter in the design is entirely generated by the Vitis™ tool based on a C-code description. The 2D filter function is translated to RTL using the Vivado® HLS compiler. The data motion network used to transfer video buffers to/from memory and to program parameters (such as video dimensions and filter coefficients) is inferred automatically by the v++ compiler within the Vitis tool.
The table below shows utilization numbers after optimization of the hardware design.
Resource usage of current design
| xcvm1802-vsva2197 | CLB LUTs | BRAM | DSP | URAM |
|---|---|---|---|---|
| Available | 899840 | 967 | 1968 | 463 |
| Platform | 3525 | 0 | 0 | 0 |
| Filter2d_pl | 14249 | 84 | 81 | 0 |
| Total | 17774 | 84 | 81 | 0 |
| Total % | 1.9% | 8.6% | 4% | 0% |
Next Steps
License
Licensed under the Apache License, Version 2.0 (the “License”); you may not use this file except in compliance with the License.
You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an “AS IS” BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
Copyright© 2021 Xilinx