Random Forest (training)¶
Overview¶
Random forest or random decision forest is an ensemble learning method for classification, regression and other tasks that consisting a multitude of decision trees at training time and outputting the class that is the mode of the classes (classification) or mean prediction (regression) of the individual trees. Random forest uses bagging and feature randomness to create some uncorrelated trees to prevent decision tree’s overfitting to their training set.
Basic algorithm¶
To ensure the diversity of each individual tree, Random Forest uses two methods:
Sample Bagging: Random forest allows each individual tree to randomly select instances from the dataset with replacement, resulting in different trees. This process is known as bagging.
Feauture Bagging: In decision tree, we consider every possible feature and pick the one that get most gains when splitting each tree node. In contrast, each tree in a random forest can pick only from a random subset of features. This forces even more variation amongst the trees in the model and ultimately results in lower correlation across trees and more diversification.
Caution
Current implementation provides without-replacement sample bagging to complete rf framework quickly. When compared with spark, we also choose the same bagging method. With-replacement bagging will come in later updates.
Implementation¶
The random forest framework is shown in the figure below:
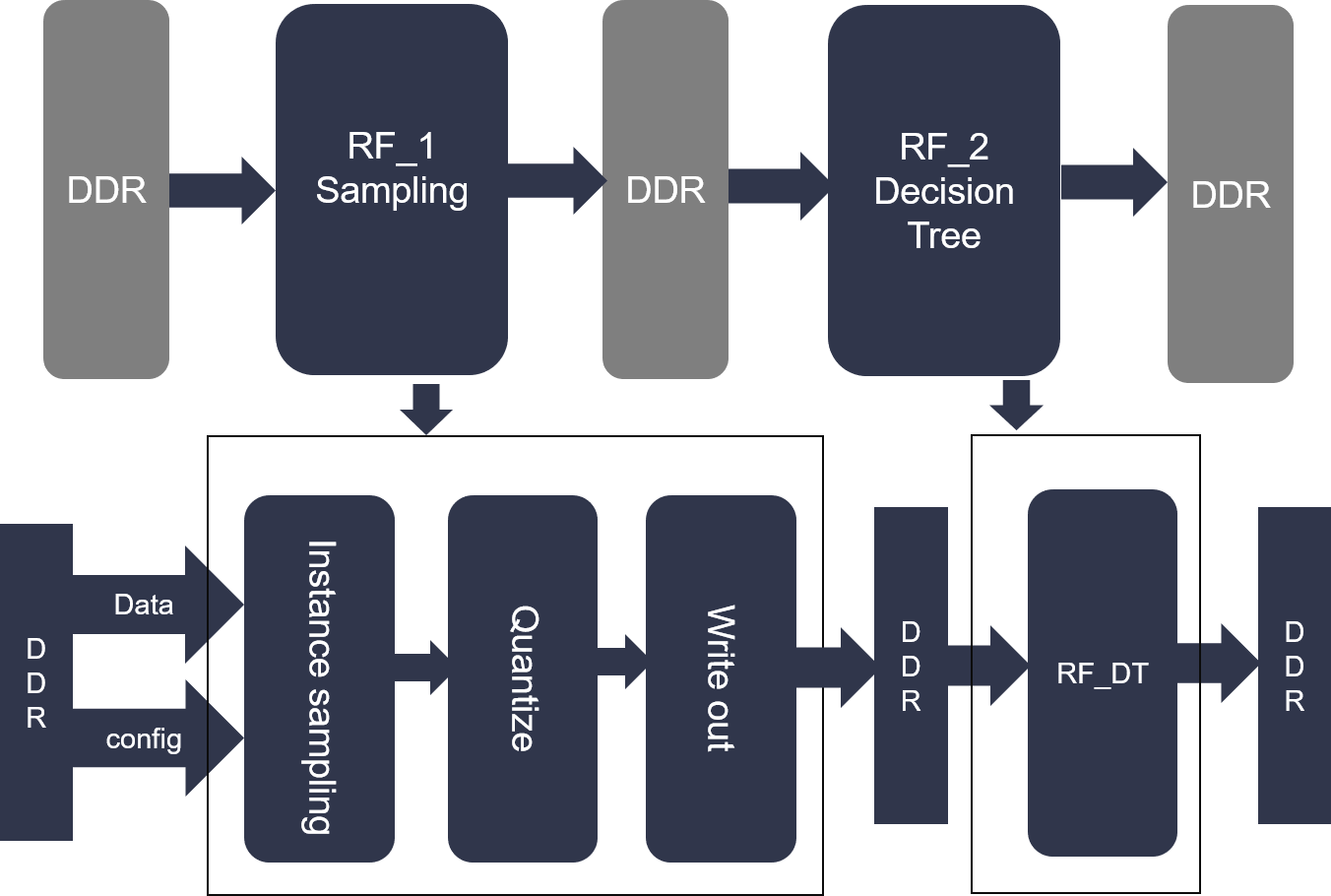
We seperate random forest int sampling modelue and decision tree module. In sampling module, we design some different implementations of bagging methods, each of which implements different sampling methods. Instance sampling: withoutplacement instance sampling, sampling ratio can be set by user.
In particular, withplacement instance sampling is implemented by multi withoutplacement instance samplings.
Feature Quantize: To save bandwith and memory, we learn from spark binned dataset, quantize each feature into a fixed point integer.
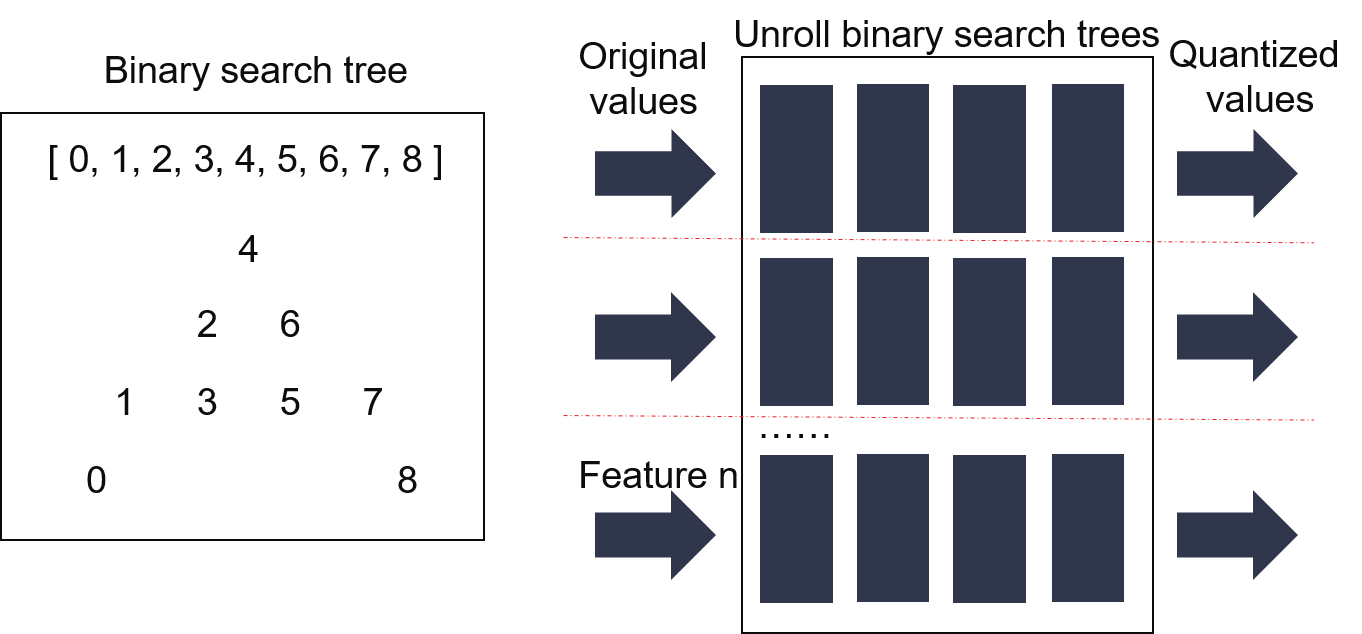
- In quantize method, we binned each feauture value into a fixed point integer, for example, if a feature value is 0.45, while the feature splitting array is [-0.1,0.25,0.50,0.80], the binning rule includes:
- < -0.1 -> 0
- -0.1 ~ 0.25 -> 1
- 0.25 ~ 0.50 -> 2
- 0.50 ~ 0.80 -> 3
- > 0.80 -> 4
so after quantizing, the binned feature value is 2 (0,25<0.45<0.5). In quantize module, the main part is searching the inverval of each value, Figure 2 shows detailed implementation by unrolling a binary search tree.
In decision tree module, we add feature sampling support, so that each tree point reserves its own feature subsets. When spliiting a tree node, it can only select the best feature from the specific subset. In current version, decision tree in random forest implements the quntize optimization for more kernel frequency and performance. We can get a special random forest with one single tree to implement a decision tree. Actually, decision tree from this method can ease IO bound compared with Non-quantized decision tree.
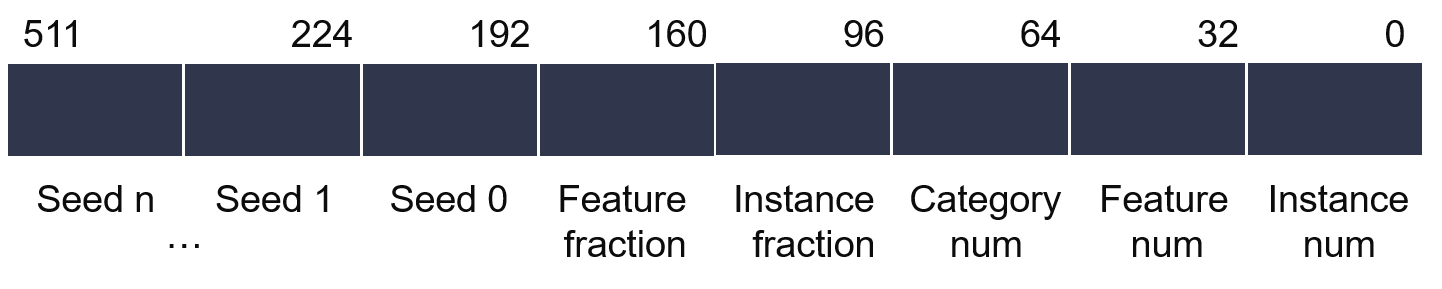
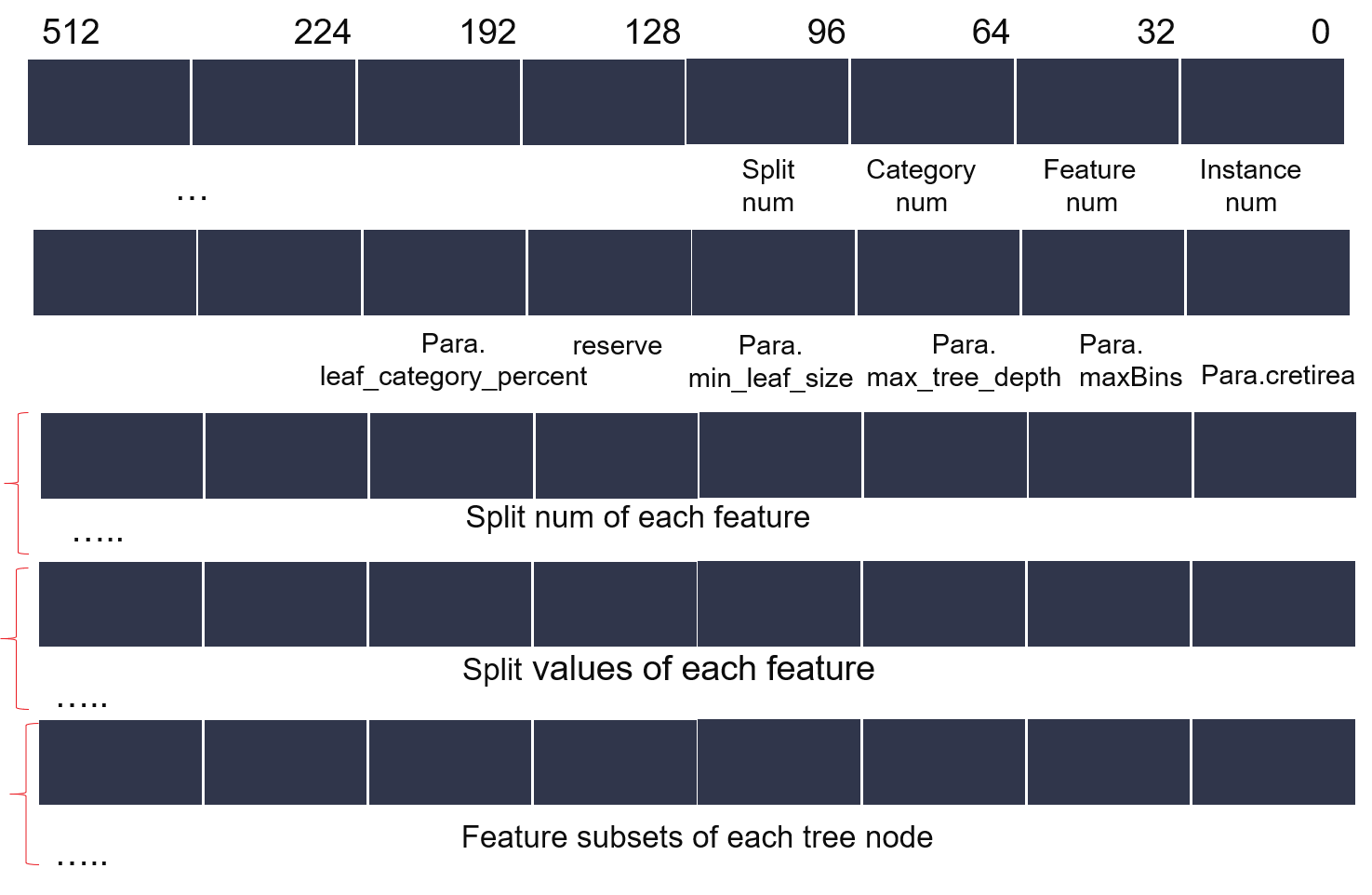
Figure 3 and Figure 4 shows the data layout in the ddr buffer. In figure 3, we reserve last 288 bits in data header for multi-seeds, by setting seedid, the function read corresponding seed from header. After one call done, the corresponding seed will write back an updated seed. The trick is for multi-sampling modlue kernel calls and pcie data write only once.
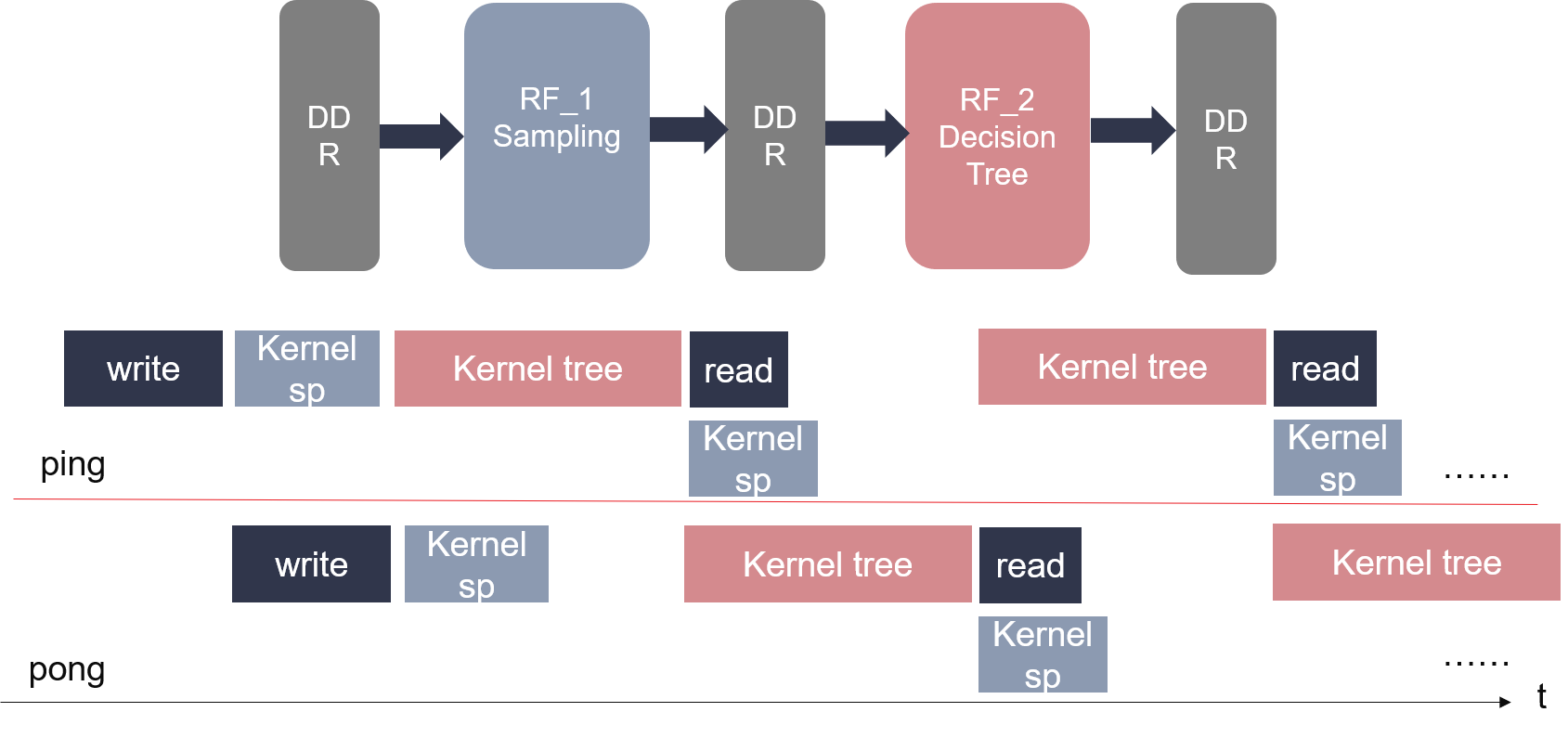
In general, we can only put 1~4 individual trees on board. Figure 5 shows the host implementaion mode of random forest tree. In this mode, we can overlap pcie read,kernel call and pcie write, making the most of the kernel/hardware resources.
Caution
Current rf decision tree has the same limitations with orignal decision tree. For thousands of features, current framework can’t support all features saving in an individual tree, so we implements a feature sampling module for further extention.
Resource Utilization¶
The hardware resources are listed in the table below. This is for the demonstration as configured 2 groups of rf_sampling + rf_decisiontree (in 4 slrs), achieving a 180 MHz clock rate.
The number of engines in a build may be configured by the user.
| Name | LUT | LUTAsMem | REG | BRAM | URAM | DSP |
|---|---|---|---|---|---|---|
| User Budget |
|
|
|
|
|
|
| Used Resources |
|
|
|
|
|
|
| Unused Resources |
|
|
|
|
|
|
| RandomForestKernel_1 |
|
|
|
|
|
|