Regular Expression Engine (reEngine)¶
Overview¶
At kernel level, the L2 reEngineKernel aims to provide an ability that a huge amount of logs could be matched efficiently under a single regular expression pattern where the L1 regex-VM matched only 1 message at a time. Thus, the reEngineKernel would be very suitable for analyzing a partiuclar logs, like Apache2 (httpd), Apache_Error, Nginx, or Syslogs.
User Guide¶
The limitations comes from both kernel side and regex-VM, since our reEngineKernel is built upon L1 regex-VM. We just explain the kernel side limitations here, for those derived from primitive, please kindly refer to Regular Expression Virtual Machine (regex-VM).
As the VM approach in L1 requires a certain size of on-chip RAMs inherently, the reEngineKernel is naturally bounded by RAMs. Thus, we cannot allocate unlimited size of buffer for configuration buffer cfg_buff, message buffer msg_buff, length buffer len_buff, or result buffer out_buff.
Choose the size for each buffer wisely is extremely critical for the overall throughput and XCLBIN buildability. Please find a recommendation in re_engine_kernel.hpp in path L2/tests/text/reEngine/kernel. Insufficient size for these parameters will directly cause the input regular expression pattern cannot be handled by the regex-VM, and the reEngine of course.
reEngine Usage¶
Before instantiating the reEngine, users have to pre-compile their regular expression using the software compiler provided in L1 first to check if the pattern is supported by the current implementation of hardware VM. The compiler will give an error code XF_UNSUPPORTED_OPCODE if the pattern is not supported. A pass code ONIG_NORMAL along with the configurations (including instruction list, bit-set map etc.) will be given if the input is a valid pattern. Then, user should pass these configurations, the input messages, along with its corresponding lengths in bytes under the format defined above to the reEngineKernel to trigger the matching process. The reEngineKernel will automatically be responsible for splitting them to individual inputs and feeding them into the buffers required by L1 regex-VM, also collecting the results after the matching process done and placing them into output result buffer correspondingly.
As mentioned in Regular Expression Virtual Machine (regex-VM), the bit-set map, instruction buffer, message buffer, and offset buffer are needed in hardware VM, and are not handled by itself. We think it is not necessary for users to deal with the details related to L1 at L2. Thus, these buffers will be automatically allocated in reEngineKernel according to the template parameters given by users.
Code Example
The following section gives a usage example for using reEngine in C++ based HLS design.
Firstly, let me introduce the format of three buffer as the inputs of reEngineKernel here:
cfg_buff

msg_buff
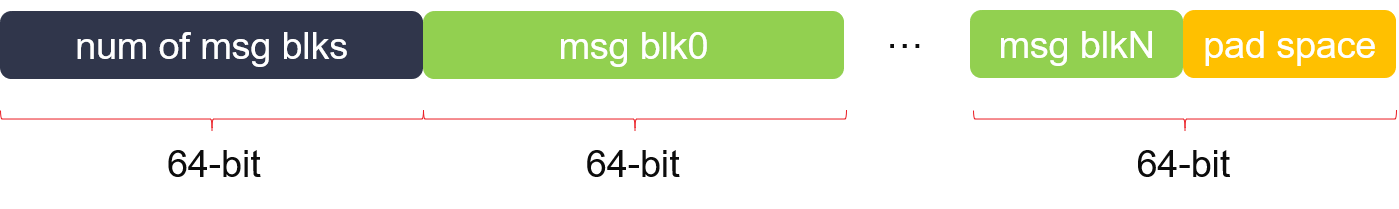
len_buff

To use the regex-VM you need to:
- Compile the software regular expression compiler by running
makecommand in pathL1/tests/text/regex_vm/re_compile - Include the
xf_re_compile.hheader in pathL1/include/sw/xf_data_analytics/textand theoniguruma.hheader in pathL1/tests/text/regex_vm/re_compile/lib/include
#include "oniguruma.h" #include "xf_re_compile.h"
- Compile your regular expression by calling
xf_re_compile
// Number of instructions tranlated from the pattern unsigned int instr_num = 0; // Number of character classes in the pattern unsigned int cclass_num = 0; // Number of capturing groups in the pattern unsigned int cpgp_num = 0; // Bit set map unsigned int* bitset = new unsigned int[8 * CCLASS_NM]; // Configuration buffer uint64_t* cfg_buff = aligned_alloc<uint64_t>(INSTRUC_SIZE); // Suppose 1k bytes is long enough for names of each capturing group uint8_t* cpgp_name_val = aligned_alloc<uint8_t>(1024); // Suppose the number of capturing groups is less than 20 uint32_t* cpgp_name_offt = aligned_alloc<uint32_t>(20); // Leave 2 64-bit space for configuration headers int r = xf_re_compile(pattern, bitset, cfg_buff + 2, &instr_num, &cclass_num, &cpgp_num, cpgp_name_val, cpgp_name_offt); // Print a name table for all of the capturing groups printf("Name Table\n"); for (int i = 0; i < cpgp_num; i++) { printf("Group-%d: ", i); for (int j = 0; j < cpgp_name_offt[i + 1] - cpgp_name_offt[i]; j++) { printf("%c", cpgp_name_val[j + cpgp_name_offt[i]]); } printf("\n"); }
- Check the return value to see if its a valid pattern and supported by hardware VM.
ONIG_NORMALis returned if the pattern is valid, andXF_UNSUPPORTED_OPCODEis returned if it’s not supported currently.
if (r != XF_UNSUPPORTED_OPCODE && r == ONIG_NORMAL) { // Prepare the buffers and call reEngine for acceleration here }
- Once the regular expression is verified as a supported pattern, you may prepare the input buffers and get the results by
// Header for reEngine #include "re_engine_kernel.hpp" // Header for reading log file as std::string #include <iostream> #include <fstream> #include <string.h> // Total number of configuration blocks // leave 2 blocks for configuration header unsigned int cfg_nm = 2 + instr_num; // Message buffer (64-bit width for full utilizing the 2 memory ports of BRAMs) uint64_t* msg_buff = aligned_alloc<uint64_t>(MAX_MSG_SZ); // Length buffer uint16_t* len_buff = aligned_alloc<uint16_t>(MAX_MSG_NM); // Append bit-set map to the tail of instruction list for (unsigned int i = 0; i < cclass_num * 4; i++) { uint64_t tmp = bitset[i * 2 + 1]; tmp = tmp << 32; tmp += bitset[i * 2]; cfg_buff[cfg_nm++] = tmp; } // Set configuration header accordingly typedef union { struct { uint32_t instr_nm; uint16_t cc_nm; uint16_t gp_nm; } head_st; uint64_t d; } cfg_info; cfg_info cfg_h; cfg_h.head_st.instr_nm = instr_num; cfg_h.head_st.cc_nm = cclass_num; cfg_h.head_st.gp_nm = cpgp_num; cfg_buff[0] = cfg_nm; cfg_buff[1] = cfg_h.d; // String of each line in the log std::string line; // We provide a 5k line apache log std::ifstream log_file(log_data/access_5k.log); if (log_file.is_open()) { // Read the apache log line-by-line while (getline(log_file, line)) { if (line.size() > 0) { if (writeOneLine(msg_buff, len_buff, offt, msg_nm, line) != 0) { return -1; } } } // Set the header of message buffer (number of message blocks in 64-bit) msg_buff[0] = offt; // Set the header of length buffer (concatenate the first 2 blocks, it presents the total number of messages in msg_buff) len_buff[0] = msg_nm / 65536; len_buff[1] = msg_nm % 65536; } else { printf("Opening input log file failed.\n"); return -1; } // Result buffer uint32_t* out_buff = aligned_alloc<uint32_t>((cpgp_num + 1) * msg_nm); // Call reEngine reEngineKernel(reinterpret_cast<ap_uint<64>*>(cfg_buff), reinterpret_cast<ap_uint<64>*>(msg_buff), reinterpret_cast<ap_uint<16>*>(len_buff), reinterpret_cast<ap_uint<32>*>(out_buff));
The match flag and offset addresses for each capturing group are presented in out_buff with the format shown in the figure below:
out_buff

Implemention¶
Unlike common L1 primitives, the hardware regex-VM is not using a stream-based interface due to the characteristic of the virtual machine (VM) approach. Thus, the dataflow tricks utilized in kernel level cannot be like the one commonly used in L2 implementation. We will give detailed explanations here.
For the common stream-based dataflow, we would like the interfaces between modules are FIFOs, and this is the reason why you find that the interfaces of L1 primitives are usually defined as hls::stream. By implementing the interface as FIFOs, these connected modules works as systolic array when dataflow region applied to them. A consumer in the stream-based dataflow region goes on only if the producer before it gives a data to its input FIFO. Thus, it is not necessary for us to switch the module on or off manually.
However, for those primitives with buffer interfaces like regex-VM, it comes to a ping-pong buffer structure when dataflow pragma applied to it. Since we have no empty signal as FIFO provided in buffer-based dataflow region, we have to control the modules manually to avoid malfunctioning on the pipeline. This can be explained as follows, suppose we have an input log which the messages within it needs N rounds to be all feeded into the buffers of each PU in reEngineKernel:
| Operation | Round 0 | Round 1 | Round 2 | … | Round N - 1 | Round N | Round N + 1 |
| Feeding buffers | Yes | Yes | Yes | … | Yes | No | No |
| Executing matcher | No | Yes | Yes | … | Yes | Yes | No |
| Collecting results | No | No | Yes | … | Yes | Yes | Yes |
We will not have a N + 2 round, as the whole pipeline finished right after round N + 1.
Note
This kernel implementation is very similar to the working pattern of common pipelined host as we provided in the other libraries, take this as a possible dataflow solution for integrating those primitives with buffer interfaces to L2 kernels. By doing so, you may achieve a reasonable acceleration ratio on hardware with the price of sacrificing double buffer storage.
Profiling¶
The hardware resource utilizations of reEngine (the one given in L2 test as an example on U200) is shown in the table below (performance optimized version at FMax = 200MHz).
| Item | LUT | REG | BRAM | URAM | DSP |
reEngine (U200) |
499292 | 341196 | 792 | 576 | 36 |
| 54.94% | 17.27% | 70.53% | 60.00% | 0.53% |
Number of PUs on each SLR is listed in the table below:
| SLR | Number of PUs |
| 0 | 5 |
| 1 | 2 |
| 2 | 5 |
Therefore, the kernel throughput should be:
Throughput = 12 * 387 MB/s = 4.64 GB/s