ReadFromDataframe¶
Apache Arrow is a cross-language, cross-platform, columnar data format that used in the field of data analytics, database, etc. An Apache Arrow like format “Dataframe” is defined and employed in Vitis library.
This document describes the structure of readFromDataframe() API. This API reads the “Dataframe” format data on DDR, convert to line based storage fomart output. Each output line containes one data from each field.
Input Data¶
The Dataframe meta data on DDR is introduced in detail in writeToDataFrame() API.
To start data processing, all meta info should be loaded to on-chip buffers first, which is implemented in function memToLocalRam(). Thereafter, the DDR data is burst-read in field by field.
Output Data Stream¶
The output data is packed into object stream, which includes valid data, field id, data type and end flags info. The detailed info of Object stream refer to writeToDataFrame API.
Overall Structure¶
After all meta info loaded to LUTRAM/BRAM or URAM. The data reading process is drawn:
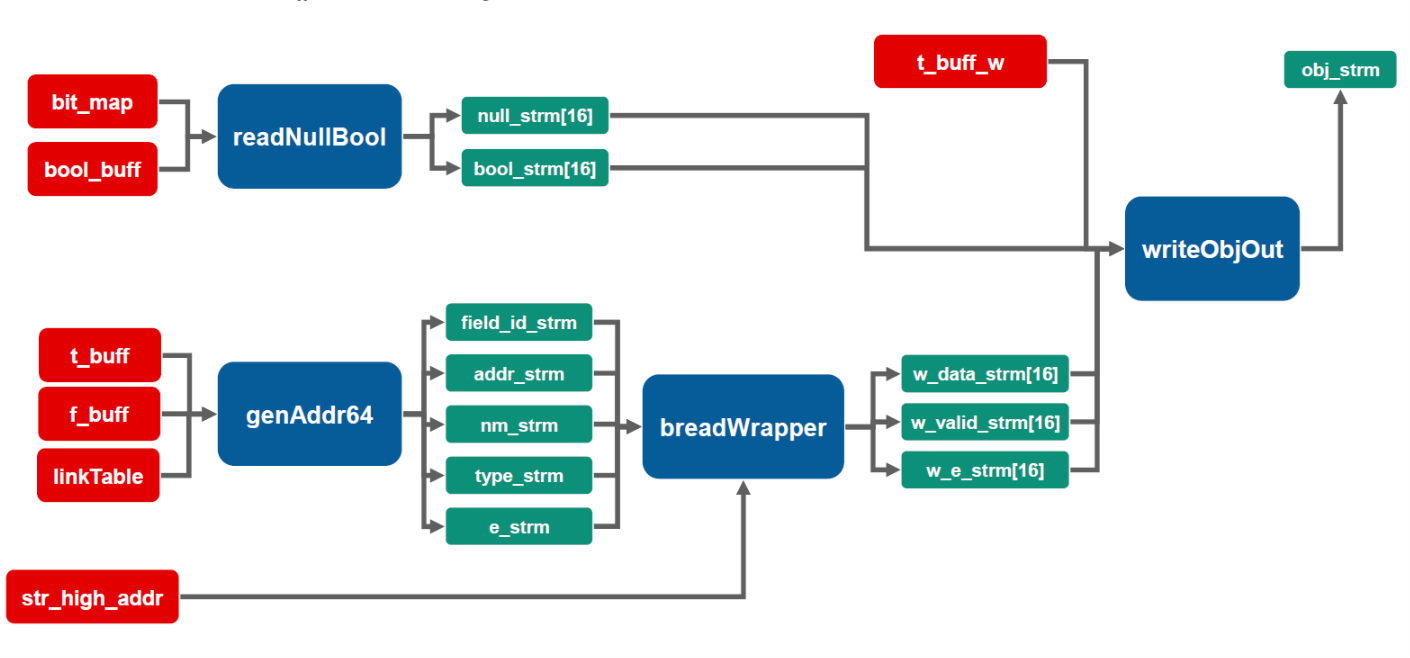
Null and Boolean flag data is read from URAM bit_map and bool_buff. The Int64/Double/Date/String offset data reading address is generated and round-robin output. Thereafter, in breadWrapper module, each field data is read in burst mode.
It is worth mentioning that, to read the valid string data, two times of read are requied: firstly, offset/strlen, then, string data. Deep FIFOs are used to buffer each field burst out data.
Finally, row based data is output by writeObjOut module. Each data is packed into an Object struct.