Internals of Group-Aggregate (Using Sorted Rows)¶
This document describes the structure and execution of group aggregate, implemented as groupAggregate function.
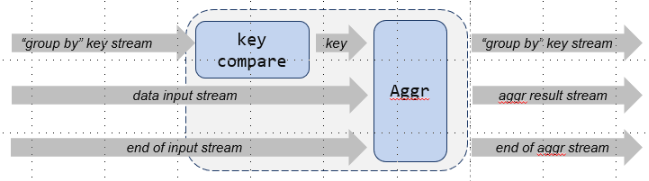
Group aggregate is similar like the primitive aggregate, but categorized the input items by group key. For each group key, an normal aggregate is performed.
The classification process of the group by is done by Sort. Therefore, this group-aggregate primitive is actually the block that connected after a sort primitive. In other words, the input streams of this primitive is already sorted by group-by key.
- The supported primitives of group-aggregate are:
- group_aggr_max
- group_aggr_min
- group_aggr_sum
- group_aggr_count
- group_aggr_cnz
- group_aggr_mean
- group_aggr_variance
- group_aggr_normL1
- group_aggr_normL2
- Correspondingly, the related OPS are:
- AOP_MAX
- AOP_MIN
- AOP_SUM
- AOP_COUNT
- AOP_COUNTNONZEROS
- AOP_MEAN
- AOP_VARIANCE
- AOP_NORML1
- AOP_NORML2
Caution
- For the primitve group_aggr_sum, group_aggr_mean, group_aggr_variance, group_aggr_normL1, group_aggr_normL2, double is used as the sum result of intermediate calculation, therefore, the II of these primitives is 15. For other primitives, the II is equal to 1.
- In groupAggregate primitives, only one group-by key / indexing key is supported. However, in a SQL query, normally, several indexing key are used together. Therefore, before the group_aggregate block, several indexing keys are combined to one key by combine-unit, and then pass the newly generated combined indexing key to groupAggregate primitive.