Internals of Hash-Join-v3 and Hash-Build-Probe-v3¶
This document describes the structure and execution of Hash-Join-V3 and Hash-Build-Probe-v3, implemented as hashJoinV3 and hashBuildProbeV3 function.
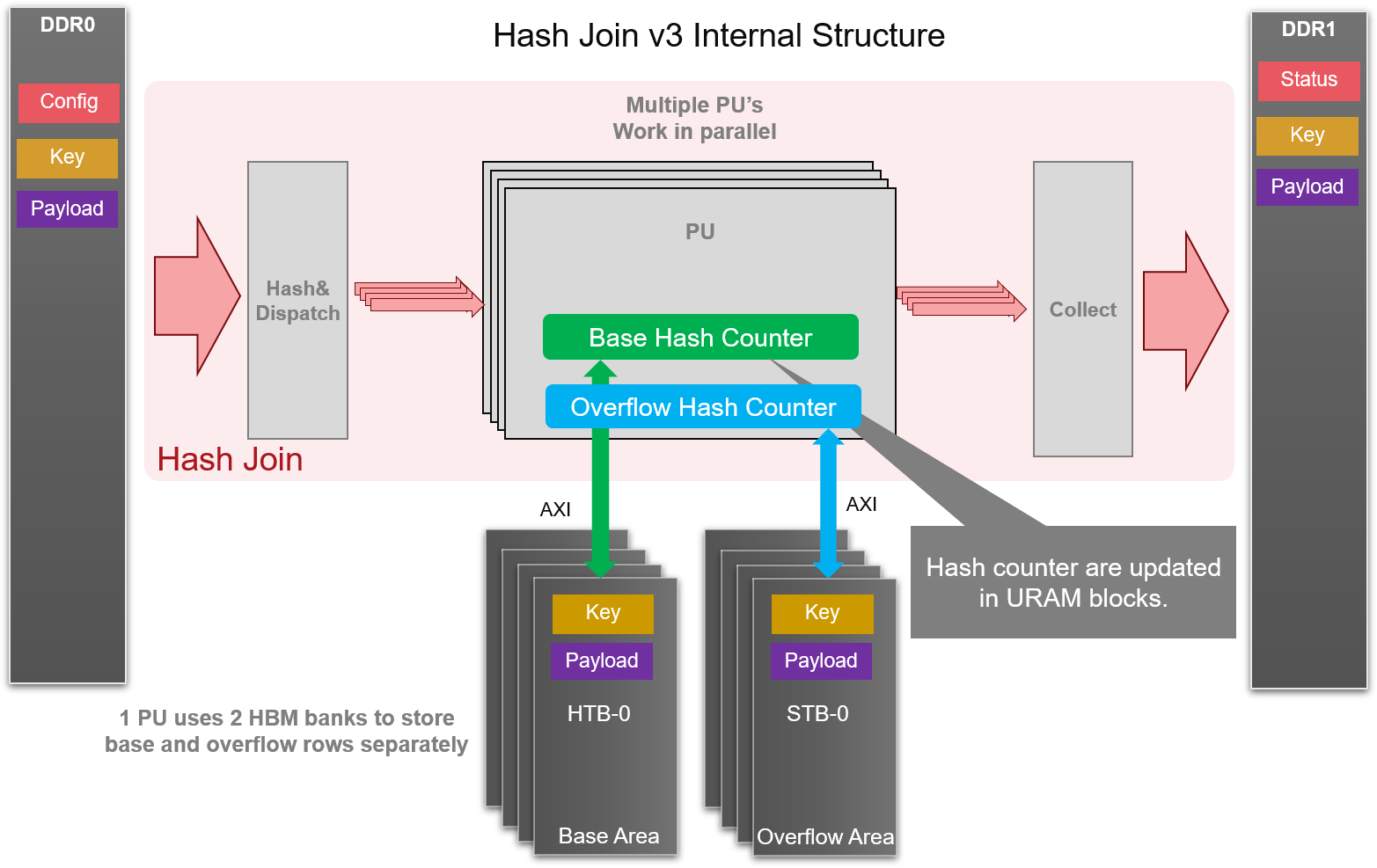
The Hash-Join-v3 and Hash-Build-Probe-v3 are general primitives to accelerate Hash-Join algorithm utilizing the advantage of high memory bandwidth in Xilinx FPGA. Hash-Join-v3 performs Hash-Join in single-call mode which means the small table and the big table should be scanned one after another. Hash-Build-Probe-v3 provides a separative solution for build and probe in Hash-Join. In Hash-Build-Probe, incremental build is supported, and the work flow can be scheduled as build0 -> build1 -> probe0 -> build2 -> probe2…
Workload is distributed based on MSBs of hash value of join key to Processing Unit (PU), so that each PU can work independently. Current design uses maximum number of PUs, served by 4 input channels through each of which a pair of key and payload can be passed in each cycle. By the way, overflow processing is provided in this design.
The number of PU is set to 8, as each PU requires two dedicated bank to temporarily store rows in small table (one for base rows and another for overflow rows). Due to DDR/HBM memory access delay, 4 channels can serve enough data to these PUs. Each PU performs HASH-JOIN in 3 phases.
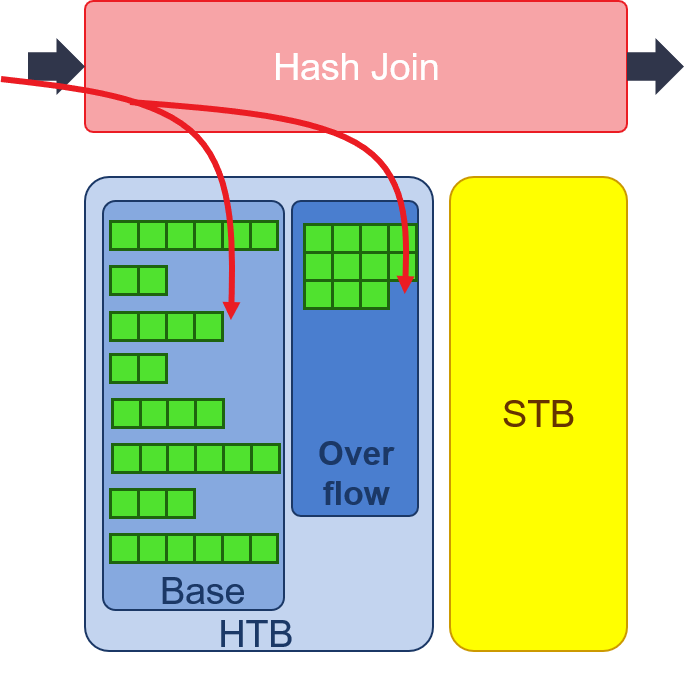
- Build: with small table as input, the number of keys falls into each hash values are counted. The value of hash counters are stored in bit vector in URAM. Every hash value has a fixed depth of storage in HBM to store rows of small table. If the counter of hash value is larger than the fixed depth, it means that overflow happens. Another bit vector is used for counting overflow rows. Also, the overflow of small table will be stored in another area in HBM.
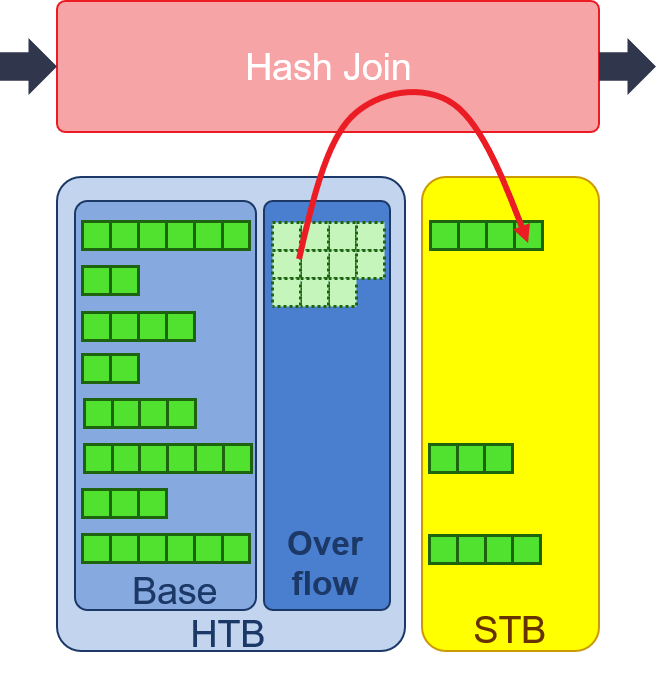
- Merge: accumulating the overflow hash counter to get the offsets of each hash value. Then, the overflow rows will be read in form one HBM and write out to another HBM. The output address of overflow rows is according to the offset of its hash value. By operation of Merge, we can put the overflow rows into its right position and waiting for Probe. In order to provide high throughput in this operation, two dedicated HBM ports is required for each PU, which provides read and write accessibilities at the same time.
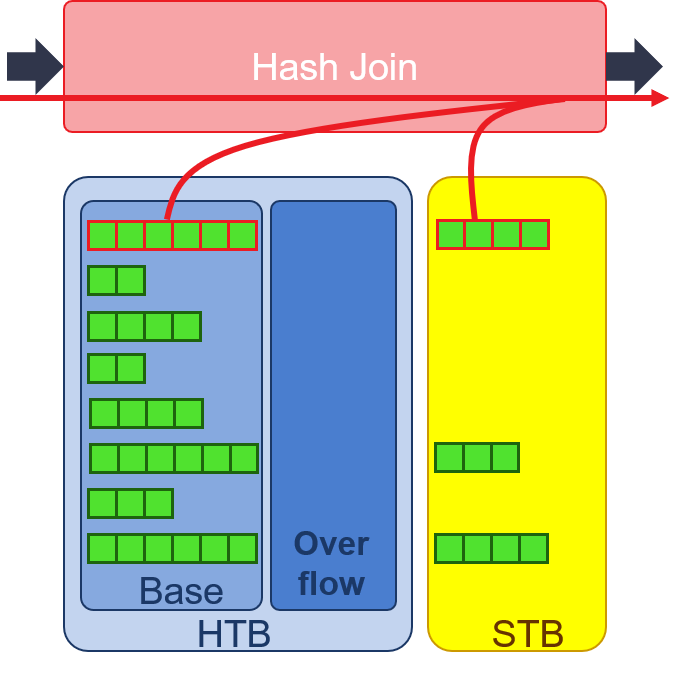
- Probe: finally, the big table is read in, and we can know the number of hash collision and offset of overflow rows with the same hash by referencing the hash counter in URAM. Then the possible matched key and payload pairs can be retrieved from HBM, and joined with big table payload after key comparison.
Important
Make sure the size of small table is smaller than the size of HBM buffers. Small table and big table should be fed only ONCE.
Caution
Currently, this primitive expects unique key in small table.
The primitive has only one port for key input and one port for payload input. If your tables are joined by multiple key columns or has multiple columns as payload, please use combineCol to merge the column streams, and use splitCol to split the output to columns.
There is a deep relation in the template parameters of the primitive. In general, the maximum capacity of rows and depth of hash entry is limited by the size of HTB. Each PU has one HTB in this design, and the size of one HTB is equal to the size of one pseudo-channel in HBM. Here is an example of row capacity when PU=8:
HTB Size Key Size Payload Size Row Capacity Hash Entry Max Depth for Hash Entry Overflow Capacity 8x256MB 32 bit 32 bit 64M 1M 63 (base rows take 63M) 1M 8x256MB 128 bit 128 bit 16M 1M 15 (base rows take 15M) 1M
The Number of hash entry is limited by the number of URAM in a single SLR. For example, there are 320 URAMs in a SLR of U280, and 1M hash entry will take 192 URAMs (96 URAMs for base hash counter + 96 URAMs for overflow hash counter). Because the number of hash entry must be the power of 2, 1M hash entry is the maximum for U280 to avoid crossing SLR logic which will lead to a bad timing performance of the design.