VVAS C API Guide¶
This document describes general guideline of using VVAS core API for video analytics application development. Refer to the VVAS C API Reference document page to review VVAS core API signature/parameters in details.
We will use the sample video pipeline depicted below to illustrate how to use the VVAS Core APIs.
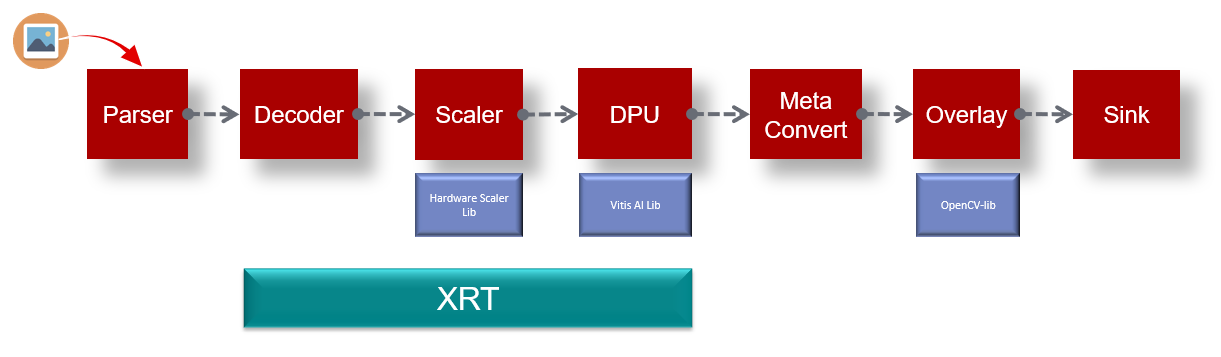
Figure 1: A sample Video Pipeline consisting core VVAS modules¶
Here are the algorithmic steps for building the above pipeline
Create intances of the VVAS core modules (Parser, Decoder, Scaler, Infer, MetaConvert, etc)
Read encoded data from the file and parse it using Parser, if EOS goto #11
Feed the parsed data to the decoder and get the decoded data
Do scaling and pre-processing on decoded buffer using Scaler and keep the decoded buffer as it is.
Do inferencing on scaled and pre-processed buffer using DPU.
Free scaled and pre-processed buffer and upscale the inference bounding box to the resolution of decoded buffer.
Convert DPU inference data to Overlay data using MetaConvert.
Draw inference data on decoded buffer
Consume this buffer (display, file dump, etc.) and then release it for further re-use (in case application is maintaining a pool of free buffers, then return this buffer to the buffer pool).
Go to #2
Destroy all instances of VVAS core modules.
Exit
Also note the following guidelines of VVAS Core API usage.
Note
The VVAS Core APIs are not thread-safe. User must not call Core APIs of same instance of Core module from different thread. A thread should create its own context (
VvasContext) to manage the core modules (Parser, decoder, etc) used in that thread.VVAS Core API provides API to allocate and deallocate the buffers. However, the users should create their own pool of buffers to manage/reuse the buffers in the pipeline.
The VVAS Core Parser can parse only H264 and H265 elementary stream, containerized streams are not supported.
Creating VVAS Context¶
Any application using the VVAS Core APIs should first create a VVAS context using the vvas_context_create() API.
VvasContext* vvas_context_create (int32_t dev_idx, char * xclbin_loc, VvasLogLevel log_level, VvasReturnType *vret)
To create a VVAS context you need to specifiy the xclbin file and the device index. For debug purposes, a log level (such as
LOG_LEVEL_DEBUG,LOG_LEVEL_INFO, etc) can also be specified.It is recommended to create a VVAS context for each component separately if each module will be running in different thread.
When creating VVAS contexts, the xclbin file name is needed for Scaler and Decoder modules only, as they are the only modules using hardware accelerators.
When creating VVAS contexts to use the Parser, MetaConvert or Overlay modules, the xclbin file name can passed as NULL and device index as -1.
Using VVAS Memory¶
Memory allocation: The VVAS Memory is allocated using the vvas_memory_alloc() API. Application code allocate VVAS Memory that is used as a buffer for the elementary stream from the video input. The elementary stream buffer is used as the input of the parser module to genereate encoded access-unit frame.
VvasMemory* vvas_memory_alloc (VvasContext *vvas_ctx,
VvasAllocationType mem_type,
VvasAllocationFlags mem_flags,
uint8_t mbank_idx,
size_t size,
VvasReturnType *ret).
Few notes regarding the arguments of vvas_memory_alloc() API
Argument
VvasAllocationType: The memory allocated to propagate the elementary stream the allocation type isVVAS_ALLOC_TYPE_NON_CMAVvasAllocationFlags: Currently supported allocation flag isVVAS_ALLOC_FLAG_NONE.The
mbank_idxis the index of the memory bank where the memory is allocated. For currently supported platform the memory bank index is 0.The size of the memory, generally 4K or multiple of 4K bytes.
Memory map: To read/write from/to a VvasMemory, it first needs to be mapped using the vvas_memory_map() API.
VvasReturnType vvas_memory_map (VvasMemory* vvas_mem, VvasDataMapFlags flags, VvasMemoryMapInfo *info)
The
VvasDataMapFlagsargument specifies whether the memory should be mapped for reading (VVAS_DATA_MAP_READ) or writing (VVAS_DATA_MAP_WRITE)The
VvasMemoryMapInfostruct contains the virtual pointer and size ofVvasMemory.
Memory unmap: After reading or writing a VvasMemory, it must be unmapped using the vvas_memory_unmap() API.
VvasReturnType vvas_memory_unmap (VvasMemory* vvas_mem, VvasMemoryMapInfo *info)
Memory deallocation: When a VvasMemory is no longer needed, it must be freed using the vvas_memory_free() API.
void vvas_memory_free (VvasMemory* vvas_mem)
Using VVAS Video Frame¶
Video frame allocation: VVAS Video Frame can be created using the vvas_video_frame_alloc() API. The video frames are used for internal pipeline stages. For example, the application can allocate decoder or scaler output video frames to propagate the output from the decoder or scaler module.
VvasVideoFrame* vvas_video_frame_alloc (VvasContext *vvas_ctx, VvasAllocationType alloc_type, VvasAllocationFlags alloc_flags, uint8_t mbank_idx, VvasVideoInfo *vinfo, VvasReturnType *ret)
Argument
VvasAllocationType: The video frames allocated to propagate output from decoder/scaler the allocation type must beVVAS_ALLOC_TYPE_CMAArgument
VvasAllocationFlags: Currently supported allocation flag isVVAS_ALLOC_FLAG_NONE.Argument
mbank_idx: For decoder output video frames the memory bank index could be obtained for decoder output configuration. For currently supported platform the memory bank index is 0.
Video frame map: In order to read or write a VvasVideoFrame, it first needs to be mapped using the vvas_video_frame_map() API.
VvasReturnType vvas_video_frame_map(VvasVideoFrame *vvas_vframe, VvasDataMapFlags map_flags, VvasVideoFrameMapInfo *info)
The
VvasDataMapFlagsargument specifies whether the video frame should be mapped for reading (VVAS_DATA_MAP_READ) or writing (VVAS_DATA_MAP_WRITE)When mapping video frame buffers to be used with a Decoder or a Scaler component, the
VvasAllocationTypeandVvasAllocationFlagsmust be set toVVAS_ALLOC_TYPE_CMAandVVAS_ALLOC_FLAG_NONErespectively.
Video frame unmap: After reading or writing a VvasVideoFrame, it must be unmapped using the vvas_video_frame_unmap() API.
VvasReturnType vvas_video_frame_unmap (VvasVideoFrame* vvas_vframe, VvasVideoFrameMapInfo *info)
Video frame deallocation: When a VvasVideoFrame is no longer needed, it must be freed using the vvas_video_frame_free() API.
void vvas_video_frame_free (VvasVideoFrame* vvas_vframe)
Parsing H.264/H.265 Streams¶
Parser is one of the core module that parse the elementary stream buffer and extract access-units/frames for the downstream pipeline.
Parser instantiation: Once VVAS context is created, we can create the Parser module using the vvas_parser_create() API.
VvasParser* vvas_parser_create (VvasContext* vvas_ctx, VvasCodecType codec_type, VvasLogLevel log_level):
Extracting the access-units/frames: For the parser input, we allocate VvasMemory and copy the encoded elementary stream buffer into it. From the parser output we obtain access-units and the decoder’s input configuration.
VvasReturnType vvas_parser_get_au (VvasParser *handle, VvasMemory *inbuf, int32_t valid_insize, VvasMemory **outbuf, int32_t *offset, VvasDecoderInCfg **dec_cfg, bool islast)
If return value from above API is
VVAS_RET_NEED_MOREDATA, it means that the encoded buffer which you fed to not sufficient for the parser and it need more data.While feeding above API you need to be careful of offset value, this is both in and out parameter for the API
As input it should be pointing to the offset in input encoded buffer, and when this API returns it will contain the offset till which parser consumed the encoded buffer, hence while feeding this API again you should feed the remaining data if parser was not able to parse the complete data given to it.
Above API will also return the stream parameters into dec_cfg, this configuration is generated whenever parser finds any change in the stream parameter or if it is the very first encoded frame. This dec_cfg will be used to configure the decoder, you must free it after you use it.
On
VVAS_RET_SUCCESSfrom the API would get the parsed AU frame in outbuf. This outbuf can be now fed to the decoder. This outbuf is allocated inside parser module, hence must be freed by the use after use.
Decoding H.264/H.265 Streams¶
Decoder is the core module to decode the encoded access-units/frames.
Decoder instantiation: Once the VvasContext is created, we can create the decoder instance using the vvas_decoder_create() API.
VvasDecoder* vvas_decoder_create (VvasContext *vvas_ctx, uint8_t *dec_name, VvasCodecType dec_type, uint8_t hw_instance_id, VvasLogLevel log_level)
For the current platform, the
dec_name(Decoder name) iskernel_vdu_decoder:{kernel_vdu_decoder_xx}where xx can be from 0 – 15, and each index represents one unique instance of the decoder.hw_instance_idis the instance id of the decoder,hw_instance_id = 0, when dec_name (decoder name) is
kernel_vdu_decoder:{kernel_vdu_decoder_xx1}, where xx1 is any number from 0 to 7hw_instance_id = 1, when dec_name (decoder name) is
kernel_vdu_decoder:{kernel_vdu_decoder_xx2}, where xx2 is any number from 8 to 15
Decoder configuration: Once the decoder instance is created, we need to configure it first using the vvas_decoder_config() API.
VvasReturnType vvas_decoder_config (VvasDecoder* dec_handle, VvasDecoderInCfg* icfg, VvasDecoderOutCfg* ocfg)
The decoder input configuration or
VvasDecoderInCfgis obtained from the parser (or if you are using an external parser then this needs to be filled with correct values). For detail of the parser API generating decoder input configuration please refervvas_parser_get_au()On the other hand the decoder output configuration or
VvasDecoderOutCfgis obtained as output from thevvas_parser_get_auAPI.
The decoder output configuration tells us the following information
How many minimum buffers we must allocate and feed to the decoder
The memory bank index where these buffers must be allocated.
The
VvasVideoInfoof the video frames required by the decoder output
If the incoming video stream’s property does not change, we need to configure the decoder only once for that video stream.
Decoder algorithm
The core decoder operation is performed by using two APIs, vvas_decoder_submit_frames() and vvas_decoder_get_decoded_frame()
API vvas_decoder_submit_frames() is used to submit encoded access units/frames to the decoder.
VvasReturnType vvas_decoder_submit_frames (VvasDecoder* dec_handle, VvasMemory *au_frame, VvasList *loutframes)
If the above API returns
VVAS_RET_SEND_AGAIN, this means the decoder didn’t consume the current access unit frame and we need to feed it again. One possible reason for this return value could be there is no room for decoded buffer.If the above API returns
VVAS_RET_SUCCESS, this means the decoder successfully consumed the access unit frame and we can now free theau_frame.
API vvas_decoder_get_decoded_frame() is used to get the decoded frame from the decoder.
VvasReturnType vvas_decoder_get_decoded_frame (VvasDecoder* dec_handle, VvasVideoFrame ** output)
If the above API returns
VVAS_RET_NEED_MOREDATA, this means the decoder doesn’t have any decoded buffer yet, we need to feed more data to the decoder usingvvas_decoder_submit_frames()API and call this API again.If the above API returns
VVAS_RET_EOS, this means that there are no more decoded frames from the decoder.If the above API return
VVAS_RET_SUCCESS, this means that the decoder has returned a decoded buffer into output, note that this output buffer is not allocated by the decoder, it is one of the buffers which you have fed to the decoder usingvvas_decoder_submit_frames()
Now let’s understand the decoder algorithm in detail
The API vvas_decoder_config is used to configure the decoder.
Configuration information for the decoder is retrieved from the parser API
vvas_parser_get_au. When this parser API is called for the first time with encoded data, the parser will returndec_cfgparameter as an output. For details, refer to :c:type`vvas_parser_get_au`.If the incoming video stream’s property does not change, we need to configure the decoder only once for that video stream.
The next two APIs vvas_decoder_submit_frames and vvas_decoder_get_decoded_frame are asynchronous to each other. The API vvas_decoder_submit_frames is only for submitting access-units (encoded frames) for decoding, and this API is asynchronous (that means it submits access-unit frame for the decoding and does not wait for the actual decoding process to complete). It is very much possible when we are submitting an access-unit frame through API vvas_decoder_submit_frames, the decoder finished decoding a previously submitted access-unit/frames. To get decoded frame from the decoder, we have to call vvas_decoder_get_decoded_frame API. This API will return one decoded frame that is the oldest in display order. This API can be called multiple times as long as the decoder is returning the decoded frames.
With this understanding above, let’s review the steps for the complete decoder operation
Create Decoder instance (API
vvas_decoder_create)Obtain input configuration for the decoder from the parser output (API
vvas_parser_get_au)Configure the decoder and get the decoder output configuration (API
vvas_decoder_config)From the obtained decoder output configuration, we know what is the minimum number of output decoded video-frame buffers to be allocated. This number of decoder output video frames (also called the “decoder output buffers” ) is minimally required for the smooth pipeline flow. However, often we need to allocate more decoder output video frames depending on the downstream video pipeline. For example, if the downstream inference stage requires a batch of 14 frames, we should allocate these extra decoder output video frames (or decoder output buffers) for the decoder output pipeline. Hence we calculate the required number of decoder output video frames (or decoder output buffers) as below
The number of decoder output video frame buffers = VvasDecoderOutCfg.min_out_buf + Additional video frames (buffers) depending on the downstream pipeline
Now we allocate the calculated number (from the previous step) of decoder output video frames by API
vvas_video_frame_allocfor the decoder output. We also create a list,VvasList, containing those output video frames. This list will be used for subsequent API calls. For the rest of the discussion, let’s refer this list as available_video_frame_listNow we submit the current encoded access-unit/frame (obtained from parser output) to the decoder through API
vvas_decoder_submit_frames.
If the API
vvas_decoder_submit_framesreturnsVVAS_RET_SUCCESS, then we know the current input access-unit/frame is submitted successfully. So we can re-use the buffer containing this access-unit/frame as this access unit/frame has been copied into the internal buffer of the decoder. We need to make sure to call parser APIvvas_parser_get_auwith more encoded data to obtain the next access-unit/frame before the next time we callvvas_decoder_submit_frames).On the other hand, if the API
vvas_decoder_submit_framesreturnsVVAS_RET_SEND_AGAIN, then this indicates the submission of the current access-unit frame is not completed. One of the reasons could be all the previously allocated (in step 5) decoder output video frames (or decoder output buffers) are now consumed by the decoder and there is no free buffer available to store the decoded frame corresponding to the current encoded access unit/frame. Hence we need to wait until the downstream pipeline finishes using the output buffers and then frees that buffer so that this buffer is added back to the list of available free output buffers. Once the free buffers are available, send these free buffers to the decoder along with the encoded access-unit frame again. For example, let’s assume we are doing a single-stage inference that requires a batch size of 14. Hence after the inference and post-processing stage when we have inference output, we can easily add those 14 video frames back to our list of available video frames, i.e. to available_video_frame_list.
Irrespective of what we get from the output of
vvas_decoder_submit_frames, we should free the list of video frames, available_video_frame_list, because the content of the list, i.e. decoder output buffers, or decoder output video frames are already submitted to the decoder.Now we try to obtain the decoder output by calling API
vvas_decoder_get_decoded_frame
If
vvas_decoder_get_decoded_framereturnsVVAS_RET_SUCCESSthat means we have exactly one decoded frame returned by the decoder. We can now send this decoded frame (available in the output video frame buffer) through the rest of the pipeline (i.e. for subsequent pre-processing, inference, post-processing, etc). Once the frame has been processed and is no more needed then we have to put this video frame buffer back into our list of free video-frame buffers (available_video_frame_list) so that we can submit these free video frame buffers to the decoder throughvvas_decoder_submit_framesAPI in Step 6If
vvas_decoder_get_decoded_framereturnsVVAS_RET_NEED_MOREDATA, this means the decoder is not able to generate any decoded frame, and it requires more encoded access Unit/frame data to be submitted to the decoder through the APIvvas_decoder_submit_frames.If
vvas_decoder_get_decoded_framereturnsVVAS_RET_EOS, then this means the decoder has processed all the data user has given to it and the user can exit the loop and destroy the decoder instance. Decoder will returnVVAS_RET_EOSonly when the user has initiated flushing of the decoder by sending NULL input buffer invvas_decoder_submit_frames, indicating that there will be no more new input data available to submit to the decoder and decoder shall finish processing of all the data that has been submitted till now.In case there is no more input data to submit to the decoder and the user has initiated decoder flush, as mentioned in step 8c above, and
vvas_decoder_get_decoded_framehas not returnedVVAS_RET_EOS, this means decoder still has some data to process and some more output buffers are available. In this case, the loop goes back to step 6 and calls thevvas_decoder_get_decoded_frameuntil decoder returnsVVAS_RET_EOS.
If not exiting the loop in step 8c, the loop goes back to step 6 and submits an access-unit frame with vvas_decoder_submit_frames API a. The frame can be a next access-unit frame (if the current access-unit frame was sucessfully submitted, as discussed in Step 6a b. Or the frame is the same current frame (if the current access-unit frame was not sucessfully submitted as discussed in Step 6b
Scaling/Cropping/Pre-Processing Video Frames¶
Scaler instantiation: A Scaler instance can be created using the vvas_scaler_create() API.
VvasScaler * vvas_scaler_create (VvasContext * ctx, const char * kernel_name, VvasLogLevel log_level)
Kernel name for V70 is
image_processing:{image_processing_1}orimage_processing:{image_processing_2}
Adding channels for scaler processing: For processing any data using scaler we need to add them as processing channels using the vvas_scaler_channel_add() API.
VvasReturnType vvas_scaler_channel_add (VvasScaler * hndl, VvasScalerRect * src_rect, VvasScalerRect * dst_rect, VvasScalerPpe * ppe, VvasScalerParam * param)
Information about the scaler inputs and outputs are provided using
VvasScalerRectdata structures. These data structures include a pointer to theVvasVideoFrame, the width and height of the region of interest as well as its x and y coordinates.The src_rect and dst_rect information should always be provided to the scaler
For scaling, the x and y of src_rect must be zero, and the width and height must be the width and height of the input frame. Additional scaling parameters can be set using the
VvasScalerParamdata structure.For cropping, set x, y, width and height of src_rect as per the crop requirement.
For pre-processing, pass the desired alpha/mean and beta/scale parameters in a
VvasScalerPpedata structure, otherwise setppeto NULL.
Example 1
Scaling the input frame down from 1920x1080 to 640x480
Src_rect.x = 0;
Src_rext.y = 0;
Src_rect.width = 1920;
Src_rect.height = 1080;
Src_rect.frame = input_frame;
Dst_rect.x = 0;
Dst_rect.y = 0;
Dst_rect.width = 640;
Dst_rect.height = 480;
Dst_rect.frame = output_frame;
Example 2
Cropping a 278x590 section at x=300, y=350 in the input frame, and scaling this cropped section to 224x224
Src_rect.x = 300;
Src_rect.y = 350;
Src_rect.width = 278;
Src_rect.height = 590;
Src_rect.frame = input_frame;
Dst_rect.x = 0;
Dst_rect.y = 0;
Dst_rect.width = 224;
Dst_rect.height = 224;
Dst_rect.frame = output_frame;
Scaler Processing: Once channels are added to the scaler, we can process all of them in one go using the vvas_scaler_process_frame() API.
VvasReturnType vvas_scaler_process_frame (VvasScaler * hndl)
Deallocating scaler instance: One done with scaler; we need to destroy this scaler instance using the vvas_scaler_destroy() API.
VvasReturnType vvas_scaler_destroy (VvasScaler * hndl)
Inferencing on Video Frames¶
DPU instantiation:
To perform inferencing on video frames first we need to create the DPU instance using the vvas_dpuinfer_create() API.
VvasDpuInfer * vvas_dpuinfer_create (VvasDpuInferConf * dpu_conf, VvasLogLevel log_level)
The parameter VvasDpuInferConf is used to provide the model information (such as compiled model artifacts path, model name, model class, etc) for the DPU instance. The parameter is also used to provide a few more inference specific information such as desired batch size, the maximum number of object detection per frame (for object detection models), etc.
Obtaining DPU configuration:
Every DPU model has its requirements, such as input height and width, pre-processing parameters such as mean subtraction and scaling factor for all the channels, and batch size. These requirements can be queried from the DPU using the vvas_dpuinfer_get_config() API.
VvasReturnType vvas_dpuinfer_get_config (VvasDpuInfer * dpu_handle, VvasModelConf * model_conf)
Preprocessing:
The preprocessing can be done in software (using the Vitis-AI library) or using the hardware accelerator.
Software-based scaling occurs if the input frames being submitted are not of the same resolution as DPU is expecting.
Software-based pre-processing can be enabled explicitly by setting
VvasDpuInferConf.need_preprocesstotrue.
However, the software-based preprocessing can potentially impact performance, hence the user can use a hardware accelerator for doing pre-processing and scaling in one operation. This can be done by instantiating the Scaler module discussed in the previous section.
Inference:
DPU supports batching mode, the number of frames that DPU can process in one batch is called batch size. The batch size can be queried using vvas_dpuinfer_get_config API. For better performance, it is advised to call vvas_dpuinfer_process_frames after batching multiple frames as inputs for object detection. For classification cases, we can also batch multiple images (images of the detected objects from the object detection stage) and send all of them together for classification.
The vvas_dpuinfer_process_frames() API is used for inferencing on input frame(s)/image(s).
VvasReturnType vvas_dpuinfer_process_frames (VvasDpuInfer * dpu_handle, VvasVideoFrame *inputs[MAX_NUM_OBJECT], VvasInferPrediction *predictions[MAX_NUM_OBJECT], int batch_size)
Upon completion of the above API, for each of the DPU inputs (VvasVideoFrame *inputs[MAX_NUM_OBJECT]), the argument VvasInferPrediction *predictions[MAX_NUM_OBJECT] points to the tree structures containing prediction results from the inference.
Now we will take a closer look prediction result tree(s) obtained from the above API.
Prediction Result Tree
While calling API vvas_dpuinfer_process_frames, if passed predictions[x] is NULL, then DPU will create a tree structure consisting of VvasInferPrediction nodes and return it when there is any detection/classification. If predictions[x] is not NULL then VvasInferPrediction is appended as children to the passed VvasInferPrediction node.
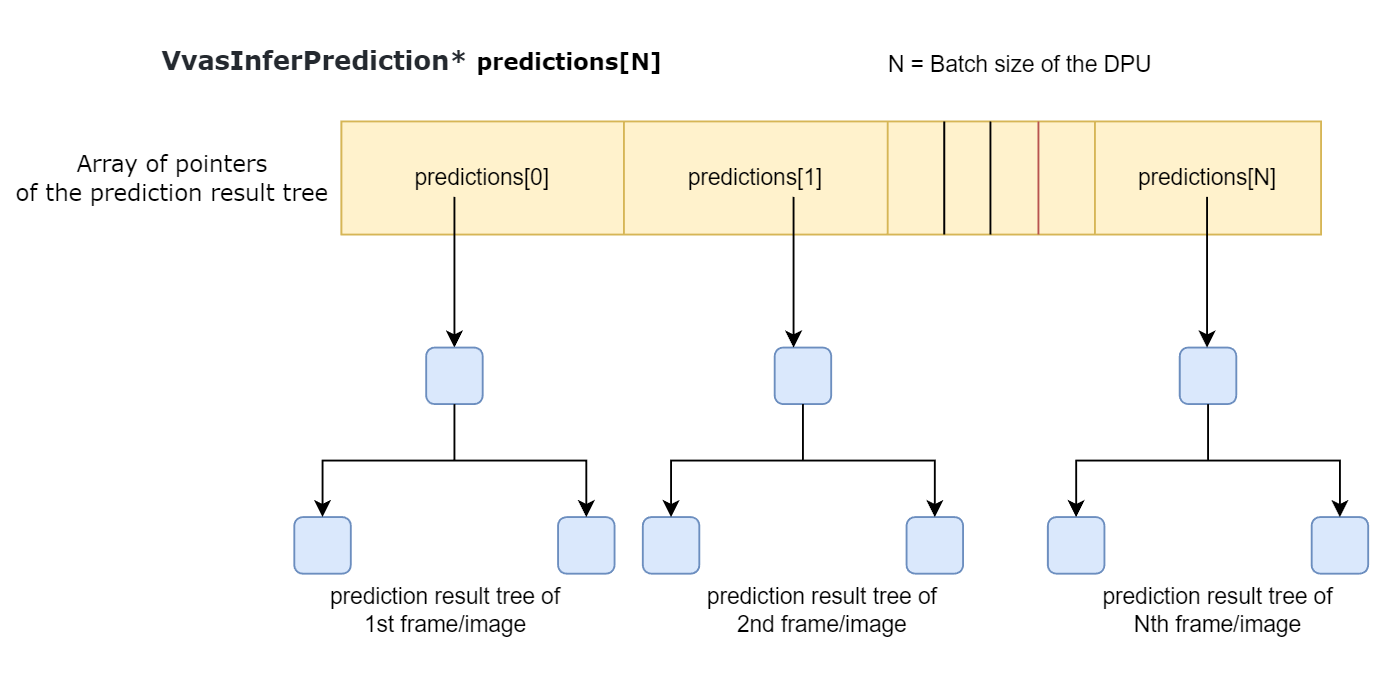
Figure 2: A visual representation of prediction result trees obtained from inference¶
As shown in the above diagram predictions[x] points to the “prediction result tree” of the Xth frame (for object detection case) or Xth image (for classification case).
It is the user’s responsibility to free these trees (VvasInferPrediction nodes) after use. The API vvas_inferprediction_free can be used for this purpose.
Prediction result tree from Object detection: Now let’s understand the structure of an individual prediction result tree for an object detection case.
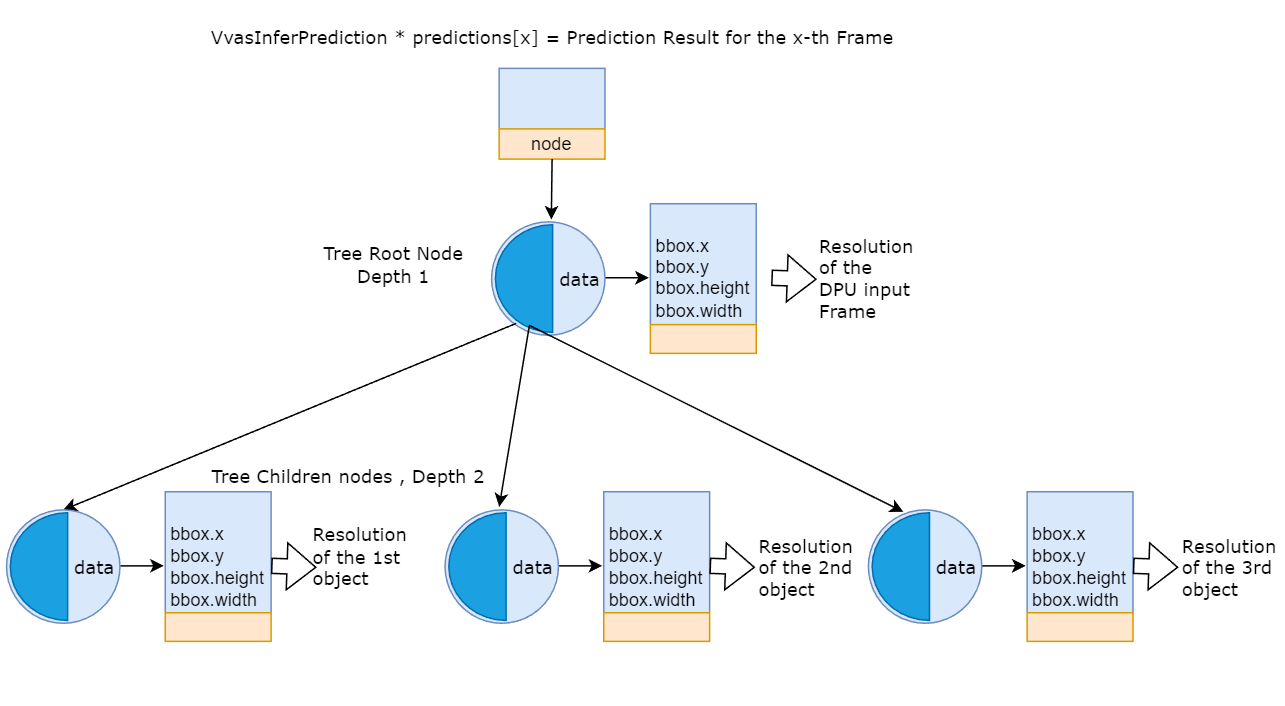
Figure 3: Example of a prediction result tree for objects detection¶
The above diagram shows an example of a prediction tree for a particular frame. As the diagram shows for this frame, 3 objects are detected.
The structure
VvasInferPredictioncontainsVvasTreeNode *node, which is used byprediction[x]to point to the prediction result tree of the Xth Frame.The tree root node has three child nodes capturing the results of three detected objects
The data part (
node->data) of the tree root node points to itsVvasInferPredictionnode containing resolution data for the DPU input framesThe data part of the child nodes points to corresponding
VvasInferPredictionnodes containing the resolution of the bounding boxes of the detected object.The resolution of the bounding boxes of the detected objects is relative to the resolution of the DPU input frame. Typically during the preprocessing stage, the decoder output video frames are resized (scaled down) as per DPU’s requirement. Hence the resolution metadata for each detected object needs to be scaled up when referring to the original video frames.
The prediction result tree can be traversed by the VVAS tree utility traversal API
vvas_treenode_traverse, which provides the facility for a user-defined callback function to be called for each node.Note that the root node’s depth is 1, and each child node’s depth is 2. This depth can be checked at any node by VVAS tree utility API
vvas_treenode_get_depth
Prediction result tree from image classification: VVAS supports running multiple classification models for the detected object from the object detection stage. Here we can pass the prediction result tree obtained from the previous inference call (i.e. vvas_dpuinfer_process_frames API call) to the subsequent inference calls. In this case, the new prediction results will be added as children to the passed tree.
For example, in the below example code, we are showing running three classification models.
VvasDpuInfer *resnet18_car_make_handle; // Dpu instance of Resnet car make inference
VvasDpuInfer *resnet18_car_type_handle; // DPU instance of Resnet car model inference
VvasDpuInfer *resnet18_car_color_handle; // DPU instance of Resnet car color inference
// For brevity we are not showing the code of creating the above DPU instances
VvasInferPrediction *resnet18_pred[DPU_BATCH_SIZE] = {0};
// For brevity we are not showing error checking after each inference call below
vret = vvas_dpuinfer_process_frames (resnet18_car_make_handle, resnet18_dpu_inputs, resnet18_pred, cur_batch_size);
vret = vvas_dpuinfer_process_frames (resnet18_car_type_handle, resnet18_dpu_inputs, resnet18_pred, cur_batch_size);
vret = vvas_dpuinfer_process_frames (resnet18_car_color_handle, resnet18_dpu_inputs, resnet18_pred, cur_batch_size);
In the above simple code example, we are calling three inferences for three types of classifications ( car make classifier, car color classifier, and car type classifier). We are passing the same resnet18_pred in each inference call. Hence prediction result tree will be grown after each inference call, so at the end, the final prediction result tree will contain all three classification results.
We also can use the prediction result tree from the object detection stage to the classifications stage. Considering the example we have shown above, each of the three VvasInferPrediction nodes at the depth two (node containing object detection result) can be passed to the classifiers. Towards that end, we will obtain a tree with depth three, where the treenodes at the depth three contain classification results of each detected object.
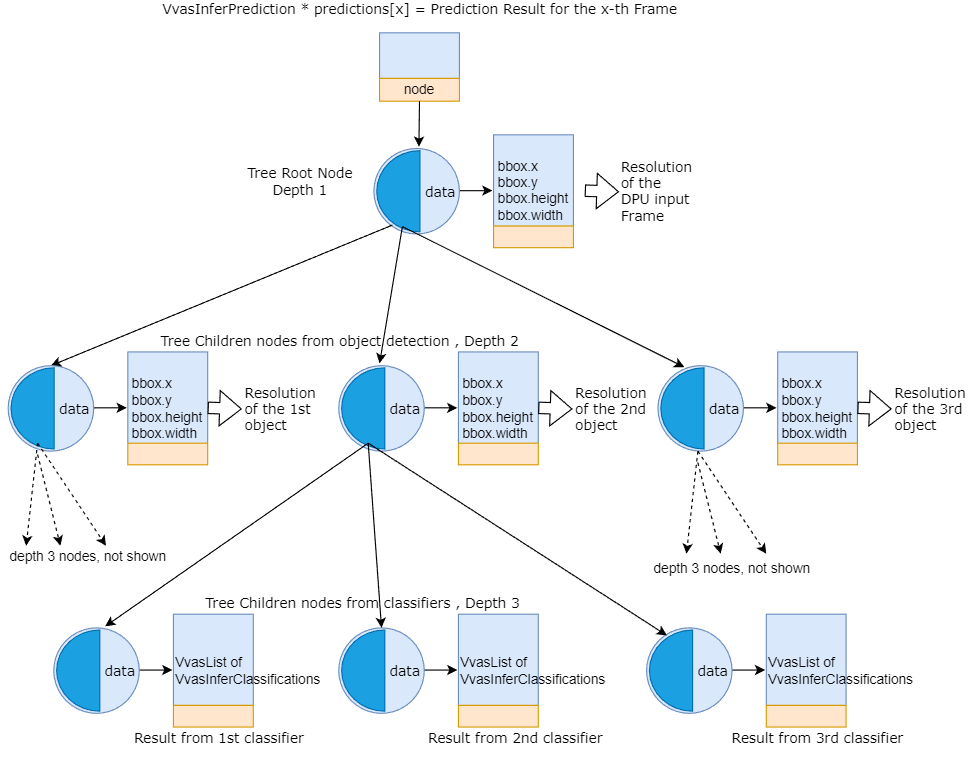
Figure 4: Example of a prediction result tree for objects detection and classification¶
As shown in the above diagram, when passing the VvasInferPrediction node of object detection results (from depth two) to the classifiers, the classifier results are populated to the new tree nodes at depth three. Towards that end, the user can then traverse the combined detection and classification result tree for each frame to extract the metadata for further processing into their business logic.
Deallocating DPU instance: Once done with the inferencing of all frames, we need to destroy the DPU instance using the vvas_dpuinfer_destroy() API.
VvasReturnType vvas_dpuinfer_destroy (VvasDpuInfer * dpu_handle)
Drawing Bounding Box/Classification Information on Video Frames¶
For drawing bounding box/classification data onto the video frame we can use the Overlay module. But this Overlay module doesn’t directly accept data generated from the DPUInfer module. Hence we need to convert DPUInfer output data formats to the format which the Overlay module accepts using the MetaConvert module.
Metaconvert instantiation: MetaConvert module’s instance can be created using the vvas_metaconvert_create() API
VvasMetaConvert *vvas_metaconvert_create (VvasContext *vvas_ctx, VvasMetaConvertConfig *cfg,VvasLogLevel log_level, VvasReturnType *ret)
While creating a metaconvert module instance, the argument VvasMetaConvertConfig is used to configure the metaconvert module. Here we can do a lot of customization by selecting many details about the desired bounding box, such as font type, font size, line thickness, selecting specific labels, annotating probabilities and many others. For details please review the structure VvasMetaConvertConfig.
Using Metaconvert: Once MetaConvert instance is created we can use it to convert VvasInferPrediction to VvasOverlayShapeInfo.
VvasReturnType vvas_metaconvert_prepare_overlay_metadata (VvasMetaConvert *meta_convert, VvasTreeNode *parent, VvasOverlayShapeInfo *shape_info)
The argument
VvasTreeNode *parentis a treenode of the inference prediction result tree. From our example of the prediction result tree above, we can pass each treenode at depth one which is a parent node of the nodes (at depth two) containing detection results of all the frames.The argument
VvasOverlayShapeInfo *shape_infois the output that we obtain after the API call, containing all the information required for the subsequent Overlay module. TheVvasOverlayShapeInfocontains all the converted metadata such as rectangles, text, lines, arrows, etc.
Using Overlay module: To use the overlay module we need to pass the video frame (VvasVideoFrame), overlay shape info (VvasOverlayShapeInfo) obtained from the metaconvert module, and overlay clock information (VvasOverlayClockInfo). The argument of type VvasOverlayFrameInfo is constructed with this information and ready to be passed to the Overlay module.
We can use the Overlay module to draw the inference data using the vvas_overlay_process_frame() API.
VvasReturnType vvas_overlay_process_frame (VvasOverlayFrameInfo * pFrameInfo)
Deallocating Metaconvert instance: Once done with the Metaconvert instance, destroy it using the vvas_metaconvert_destroy() API.
void vvas_metaconvert_destroy (VvasMetaConvert * meta_convert)
Sink¶
After the overlay operation as inference data is rendered over the original decoded data, we can consume this video-frame/buffer; either dump it into a file or display it or do whatever it is needed to do. Once this video-frame/buffer is consumed, we can re-feed it to the decoder for reusing it.