WriteToDataFrame¶
Apache Arrow is a cross-language, cross-platform, columnar data format that used in the field of data analytics, database, etc. An Apache Arrow like format “data-frame” is defined and employed in Vitis library.
This document firstly introduces the data-frame format and the difference between data frame and Apache Arrow. Thereafter, the structure of WriteToDataFrame() implementation is explained. WriteToDataFrame() reads in parsed data from JSON parser etc., re-format the data according to different data type, and save the data in data-frame format.
Data Frame format (on DDR)¶
An Apache Arrow format data can be represented in the illustrated figure leftside. The whole data is seperated into multiple record batches, each batch consists of multiple columnes with the same length.
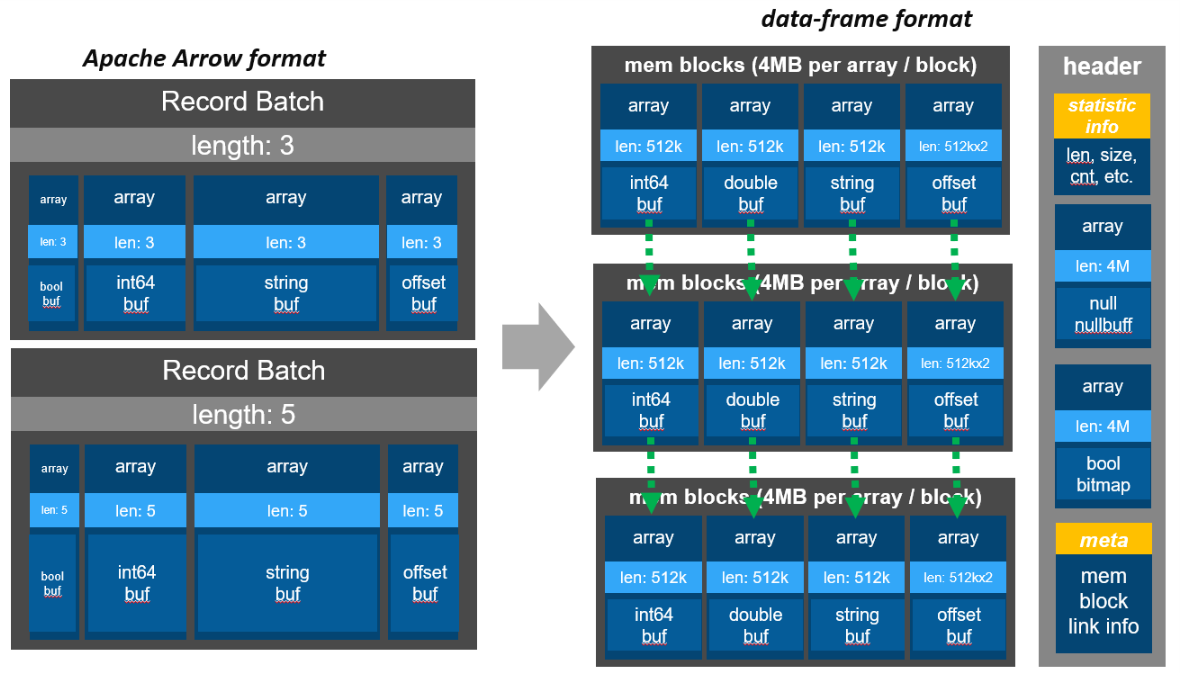
It is worth mentioning that the length of each record batch is a statistic info, unknown while reading/writing each record batch data. Besides, the data width of different data types are different, especially for string, since the length of each string data is variable.
Thus, the apache arrow columnar data format can not be implemented directly on hardware. A straight-forward implementation of arrow data would be, for each field id, one fixed size ddr buffer is pre-defined. However, since the number and data type of each field is unknow, DDR space is wasted heavly. To fully utilize the DDR memory on FPGA, the “data-frame” format is defined and employed, which can be seen in the right side figure above.
The DDR is split into multiple mem blocks. Each block is 4MB size with 64-bit width. The mem block address and linking info is recored on the meta section of DDR header. In other words, for each column / field, the data is stored in 4M -> 4M -> 4M linkable mem blocks. The length, size, count etc info are also saved in the DDR header.
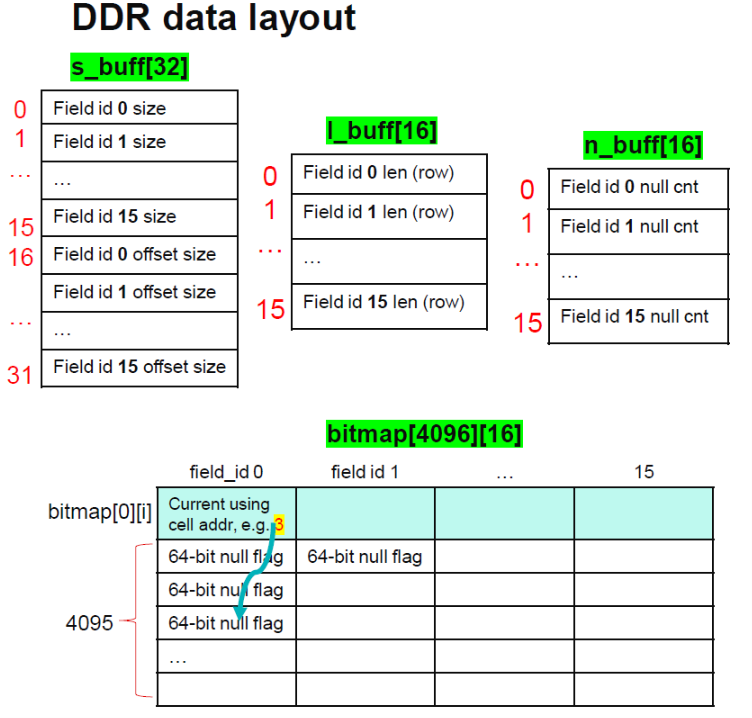
Three types of data are columnar stored differently comparing to the Apache Arrow format, namely, Null, Boolean and String. For Null and Boolean, due to only 1-bit is required for each data, bitmap[4096][16] and boolbuff[4096][16] (each data 64-bit) is used to save these data, respectively. Figure below illustreates the bitmap layout, each 64-bit data indicates 64 x input data, the maximum supported number of input data number of 64 x 4096. And supported maximum field num is 16. Same data storage buffer is employed for Boolbuff.
As for the String data, an four lines of input example is provided. The input data are given at the left side, the compact arrow format data storage is in the middle. It is clear that no bubbles exist in the data buffer. And in data-frame, the string data layout is shown on the right side. Each input string data is consist of one or multi-lines of 64 bit data, each char is 8 bit. If the string is not 64-bit aligned, bubbles are inserted to the ending 64-bit string. The reason that we introduced bubbles to data-frame storage is to ensure each string data is started in a new DDR address. This greatly guarteened the string data acess is faster without timing issue. Simliar to arror format, the offset buffer always points to the starting address of each string input.

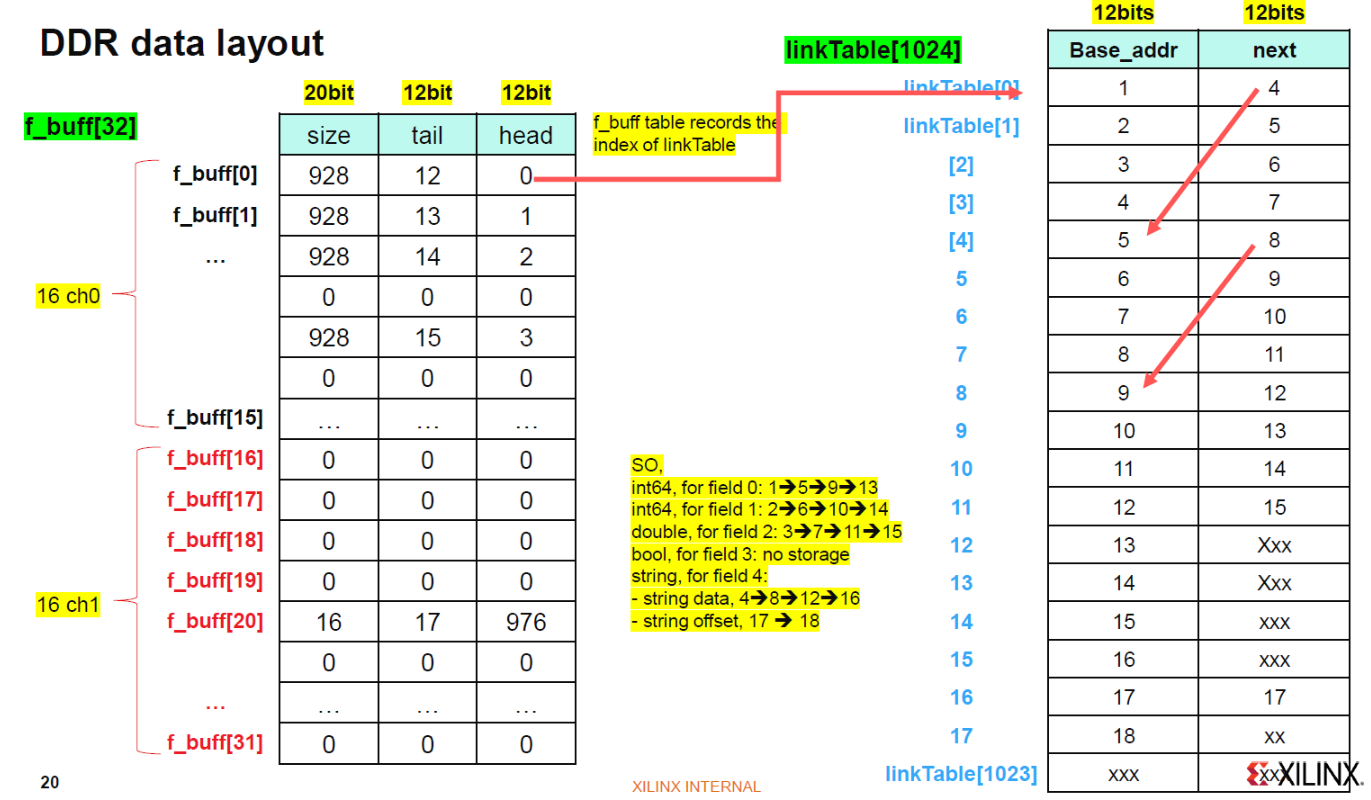
For the normal 4MB mem blocks, the f_buff saves the starting and ending Node address of each mem block. The tail mem block size is also counted. The detailed info of each node is provided in the LinkTable buffer.
Beside the data, input data length, size, etc info are also counted and added to the according buffer when the input stream ends.
Input Data Stream¶
After introducing the data-frame layout, now let’s swithch to another general used struct: Object struct. The Object struct defines the input data and all related info of each parsed data, which is represented as follows:
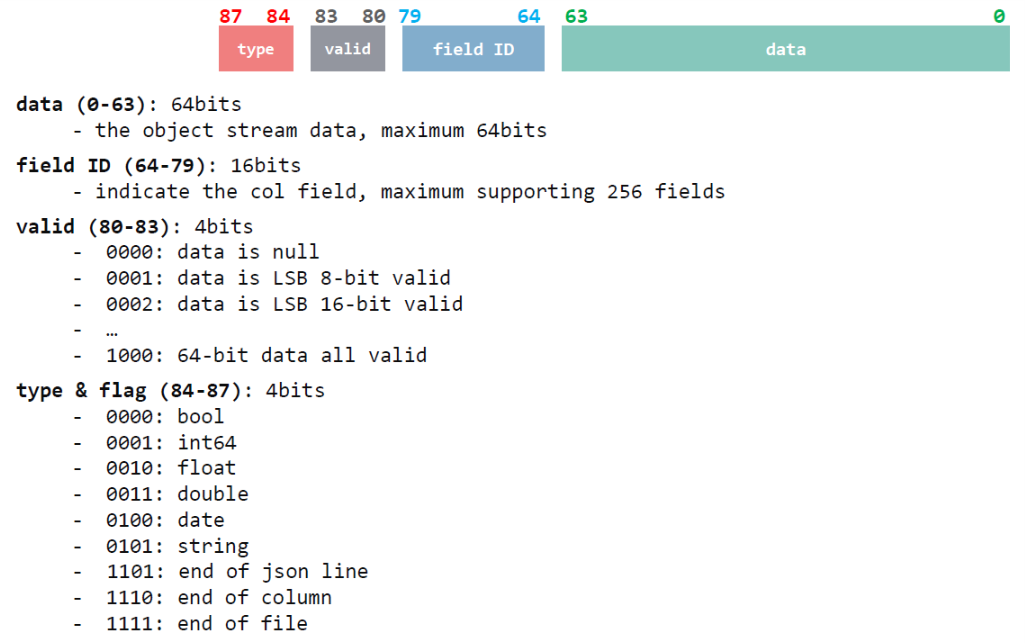
As can be seen from the struct, the valid data bits, field id, data type and flags are all provided for each data. Our data-frame APIs achieve read and write the data-frame format data to / from data streams that packed as Object struct. For instance, the CSV / JSON parser results are structed as Object struct stream.
Overall Structure¶
The writeToDataframe() process includes two stages: 1) parse input data and lively store Null/Boolean data to LUTRAM/BRAM/URAM, Int64/Double/Date/String data to DDR; 2) save the on-chip memory data to DDR.
The structure of stage One is as below:
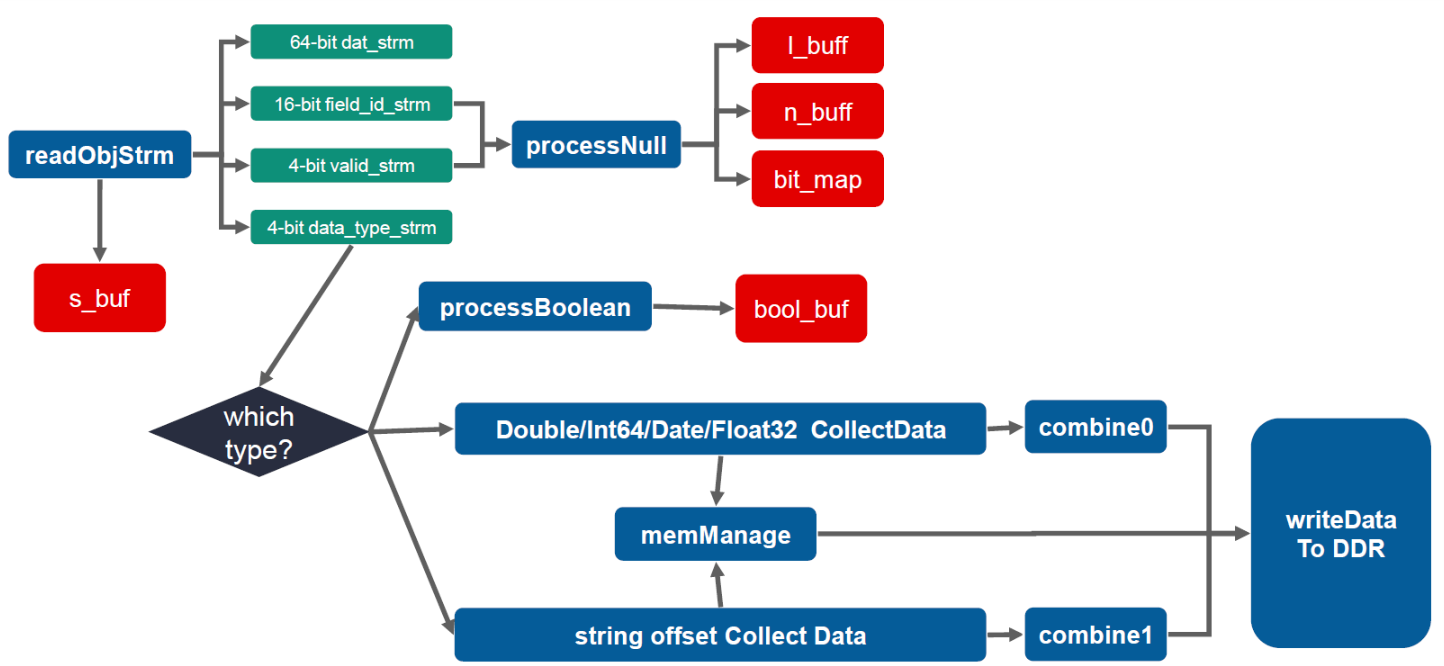
ProcessNull module adds a 1-bit flag to each data, to indicate whether each input data is null or not. This flag info is saved in an URAM bit_map. Meanwhile, the row number of input data, the number of null data are recorded on l_buff and n_buff.
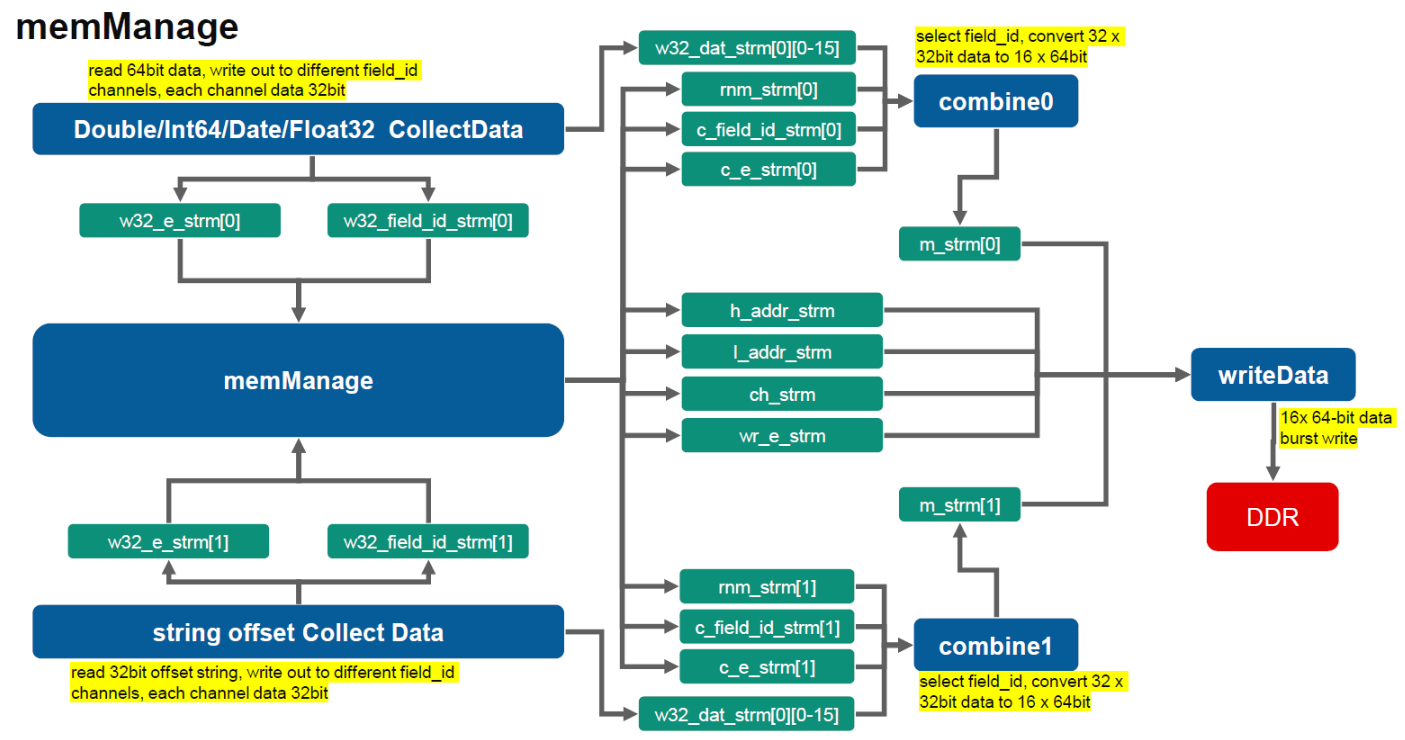
If the input data is not null, based on the data type, different actions are taken. For boolean data, similart to null, 1-bit value is used to save the real value and saved on bool_buf. For other non-string data type, a module collectData is employed to vovert the data from 64-bit to 32-bit.
For string data type, the offset / length of each string data is recorded. Due to this length info for each data is 32-bit. Another collectData module is employed here.
While outputing 32-bit data from two collectData module, each data generates 1x 32-bit data write request to memManage module. This module accumulates the request number to 32 and generate burst write 32x 32-bit data requenst. This request includes writing address and data number. The acctual 32x32-bit data is bufferred in combine module.
The reason that these two combine modules are added here is due to the DDR is 64-bit and our data is 32-bit. These two modules are converting the data again from 32-bit to 64-bit. A detailed explaination graph is provided.