Internal Design of PageRank¶
Overview¶
PageRank (PR) is an algorithm used by Google Search to rank web pages in their search engine results. PageRank is a way of measuring the importance of website pages. PageRank works by counting the number and quality of links to a page to determine a rough estimate of how important the website is. The underlying assumption is that more important websites are likely to receive more links from other websites. Currently, PageRank is not the only algorithm used by Google to order search results, but it is the first algorithm that was used by the companies, and it is the best known.
Algorithm¶
PageRank algorithm implementation:
\(A, B, C ,D...\) are different vertex. \(PR\) is the pagerank value of vertex, \(Out\) represents the out degree of vertex and \(\alpha\) is the damping factor, normally equals to 0.85
The algorithm’s pseudocode is as follows
for each edge (u, v) in graph // calculate du degree
degree(v) += 1
for each node u in graph // initiate DDR
const(u) := (1- alpha) / degree(u)
PR_old(u) := 1 / total vertex number
while norm(PR_old - PR_new) > tolerance // iterative add
for each vertex u in graph
PR_new(u) := alpha
for each vertex v point to u
PR_new(u) += const(v)*PR_old(v)
return PR_new
Implemention¶
The input matrix should ensure that the following conditions hold:
- directed graph
- No self edges
- No duplicate edges
- compressed sparse column (CSC) format
Note that this is not the “normalized” PageRank:
- The results are the same as some third-party graph databases, ex. Tigergraph
- The results are the same as some third-party graph databases after normalized of order 1, ex. Spark
- In the current version, the weighted PageRank algorithm is implemented by default.
- For the input unweighted graph, the user still needs to initialize the weight buffer manually to make the kernel work normally, as shown in the ./tests/host codes.
The algorithm implemention is shown as the figure below:
Figure 1 : PageRank calculate degree architecture on FPGA

Figure 2 : PageRank initiation module architecture on FPGA
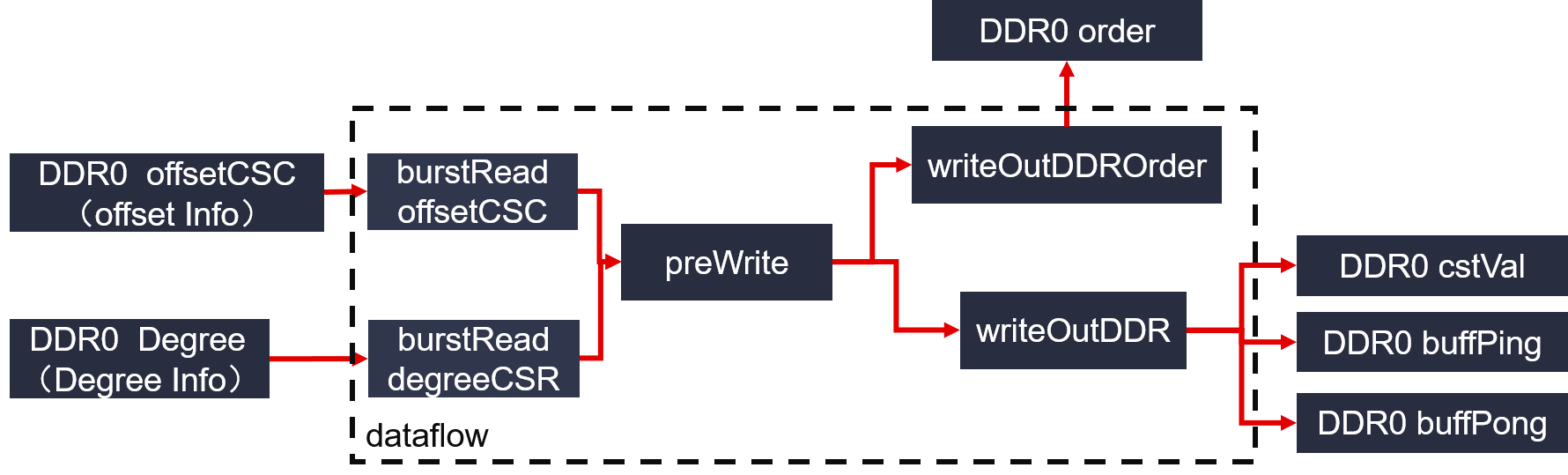
Figure 3 : PageRank Adder architecture on FPGA
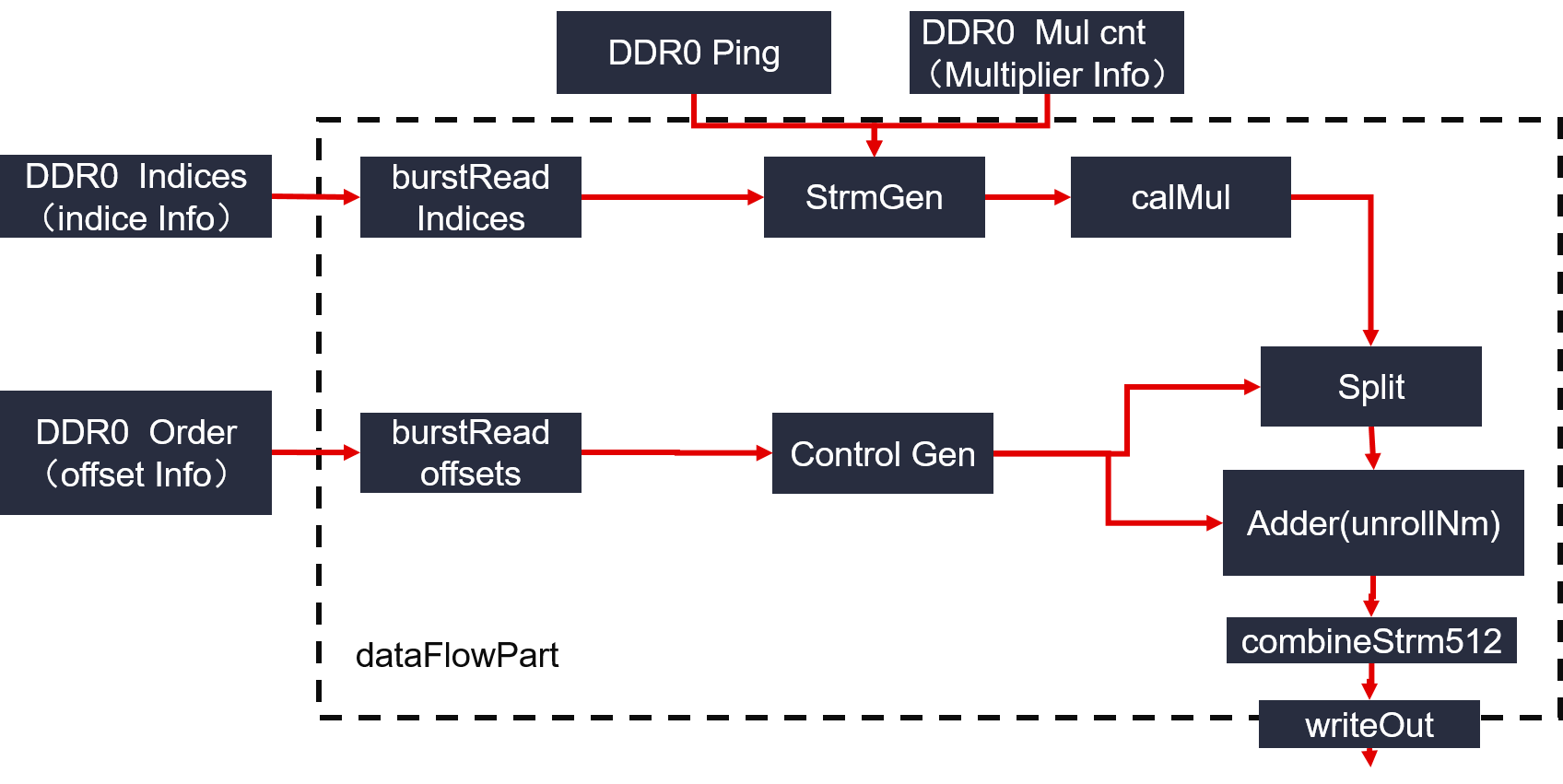
Figure 4 : PageRank calConvergence architecture on FPGA

As we can see from the figure:
- Module calculate degree: first get the vertex node’s outdegree and keep them in one DDR buffer.
- Module initiation: initiate PR DDR buffers and constant value buffer.
- Module Adder: calculate Sparse matrix multiplification.
- Module calConvergence: calculate convergence of pagerank iteration.
Profiling¶
The hardware resource utilizations are listed in the following table. Different tool versions may result slightly different resource.
Table 1 : Hardware resources for PageRank with small cache
| Kernel | BRAM | URAM | DSP | FF | LUT | Frequency(MHz) |
| kernel_pagerank_0 | 546 | 0 | 52 | 401749 | 258942 | 300 |
Table 2 : Hardware resources for PageRank with cache
| Kernel | BRAM | URAM | DSP | FF | LUT | Frequency(MHz) |
| kernel_pagerank_0 | 546 | 224 | 52 | 391591 | 262918 | 225 |
With the increase of cache depth, the acceleration ratio increases obviously, but due to the use of a lot of URAM, the frequency will drop. So the adviced cache depth is 32K for 1SLR of Alveo U250.
Table 3 : Comparison between CPU SPARK and FPGA VITIS_GRAPH
| datasets | Vertex | Edges | FPGA time cache 1 | FPGA time cache 32K | Spark (4 threads) | Spark (8 threads) | Spark (16 threads) | Spark (32 threads) | ||||||||
| Spark time | speedup Cache 1 | speedup Cache 32K | Spark time | speedup Cache 1 | speedup Cache 32K | Spark time | speedup Cache 1 | speedup Cache 32K | Spark time | speedup Cache 1 | speedup Cache 32K | |||||
| as-Skitter | 1694616 | 11094209 | 8.723 | 3.786 | 25.431 | 2.915 | 6.717 | 23.064 | 2.644 | 6.092 | 25.163 | 2.885 | 6.646 | 48.137 | 5.518 | 12.714 |
| coPapersDBLP | 540486 | 15245729 | 6.523 | 4.217 | 29.366 | 4.502 | 6.964 | 23.56 | 3.612 | 5.587 | 27.756 | 4.255 | 6.582 | 58.432 | 8.958 | 13.856 |
| coPapersCiteseer | 434102 | 16036720 | 5.571 | 4.166 | 24.161 | 4.337 | 5.800 | 21.274 | 3.819 | 5.107 | 24.545 | 4.406 | 5.892 | 55.312 | 9.929 | 13.277 |
| cit-Patents | 3774768 | 16518948 | 14.124 | 12.358 | 41.103 | 2.910 | 3.326 | 33.61 | 2.380 | 2.720 | 30.238 | 2.141 | 2.447 | 40.201 | 2.846 | 3.253 |
| europe_osm | 50912018 | 54054660 | 47.376 | 51.919 | 1197.746 | 25.282 | 23.070 | 668.923 | 14.119 | 12.884 | 423.886 | 8.947 | 8.164 | |||
| hollywood | 1139905 | 57515616 | 66.782 | 19.999 | 98.685 | 1.478 | 4.934 | 77.557 | 1.161 | 3.878 | 78.66 | 1.178 | 3.933 | 146.719 | 2.197 | 7.336 |
| soc-LiveJournal1 | 4847571 | 68993773 | 142.526 | 79.792 | 403.137 | 2.829 | 5.052 | 288.605 | 2.025 | 3.617 | 281.886 | 1.978 | 3.533 | 272.344 | 1.911 | 3.413 |
| ljournal-2008 | 5363260 | 79023142 | 166.998 | 66.814 | 447.311 | 2.679 | 6.695 | 258.133 | 1.546 | 3.864 | 208.849 | 1.251 | 3.126 | 281.81 | 1.688 | 4.218 |
| GEOMEAN | 27.604 | 16.121 | 105.891 | 3.837X | 6.571X | 78.899 | 2.858X | 4.896X | 75.152 | 2.723X | 4.663X | 95.115 | 3.772X | 6.976X | ||
Note