Dataflow compiler for QNN inference on FPGAs
- About Us
- Quickstart
- Announcements
- Publications
- Events
- Community
- Developer Docs
- Videos
- Archive
- FINN Examples
- Brevitas
- HLS Library
- FINN compiler
This project is maintained by Xilinx
FINN v0.3b (beta) is released
08 May 2020 - Yaman Umuroglu
We’re happy to announce the v0.3b (beta) release of the FINN compiler. The full changelog is quite large as we’ve been working on a lot of exciting new features, but here is a summary:
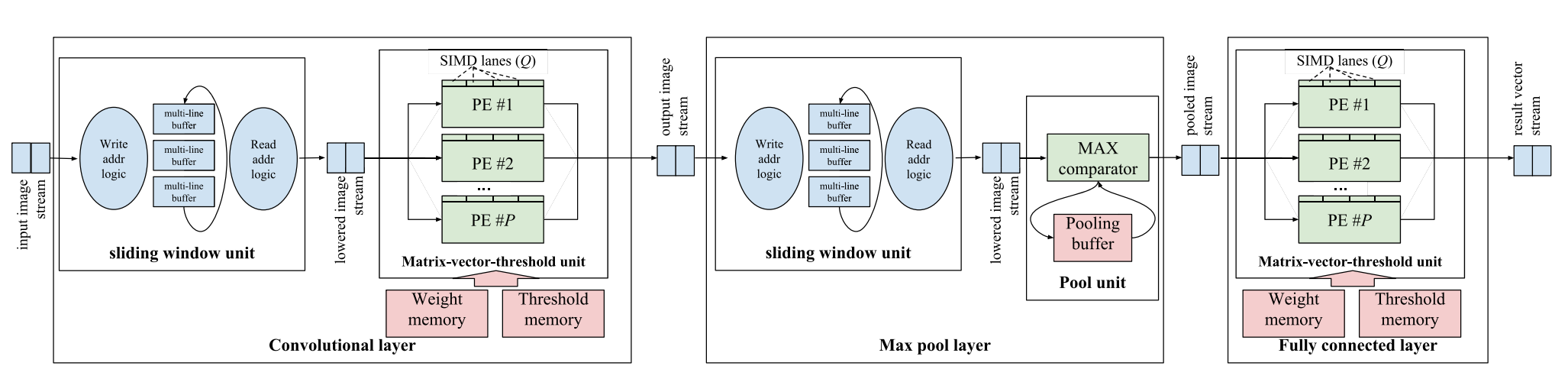
Initial support for ConvNets and end-to-end notebook example. The preliminary support for convolutions is now in place. Head over to the new end-to-end notebook to try out the end-to-end flow for convolutions and build the demonstrator for a simple binarized CNN on CIFAR-10.
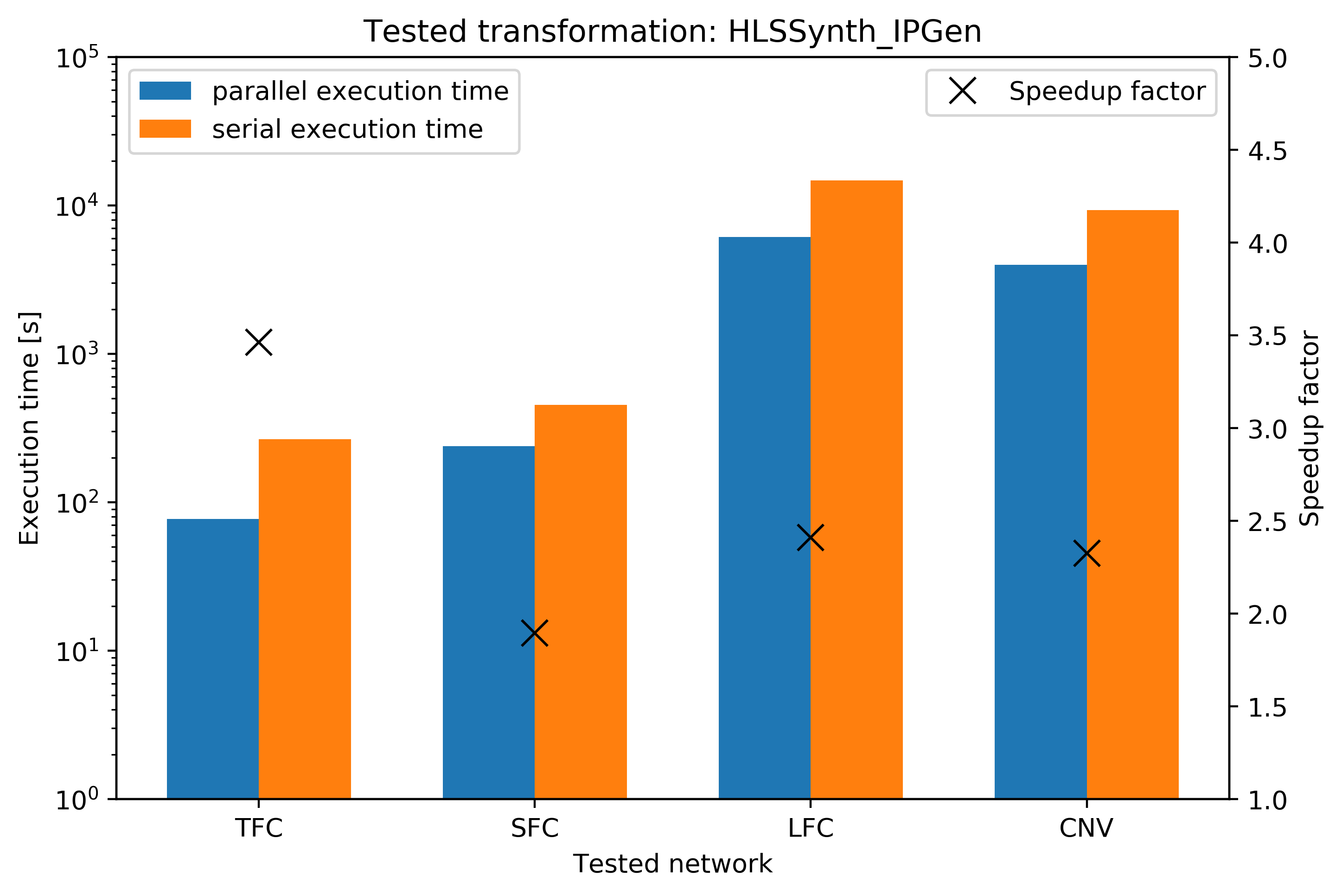
Parallel transformations. When working with larger designs, HLS synthesis and simulation compile times can be quite long. Thanks to a contribution by @HenniOVP we now support multi-process parallelization several FINN transformations. You can read more about those here.

Decoupled memory mode for MVAUs. To have more control over how the weight
memories are implemented, you can now specify the mem_mode and ram_style
attributes when instantiating compute engines. Read more here.
Throughput testing and optimizations. To do a quick assessment of the customized accelerators you build, we now support a throughput test mode that lets you benchmark the accelerator with a configurable number of samples. To get better utilization from the heterogeneous streaming architectures FINN builds, we have also introduced a FIFO insertion transformation. You can see these in action in the updated TFC-w1a1 end2end notebook.
We have a slew of other smaller features, bugfixes and various other improvements. The release (tagged 0.3b) is now available on GitHub. We’re continuously working to improve FINN in terms of layer, network and infrastructure. If you’d like to help out, please check out the contribution guidelines and share your ideas on the FINN Gitter channel!