Dataflow compiler for QNN inference on FPGAs
- About Us
- Quickstart
- Announcements
- Publications
- Events
- Community
- Developer Docs
- Videos
- Archive
- FINN Examples
- Brevitas
- HLS Library
- FINN compiler
This project is maintained by Xilinx
FINN v0.4b (beta) is released
21 Sep 2020 - Yaman Umuroglu
Version v0.4b (beta) of the FINN compiler is now available. As with the previous release there’s a whole lot of new features and bugfixes that have gone in, but here are some highlights:

Build support for Alveo/Vitis + more Zynq variants. We now have a
VitisBuild transformation to provide a FINN flow that goes all the way to
bitfiles targeting Xilinx Alveo platforms. This transformation takes care of
FIFO, datawidth converter and DMA engine insertion so you can simply give it a
FINN model with HLS layers and let it run.
Similarly, we’ve simplified the Zynq build flow with ZynqBuild to provide a
similar experience, which should now be able to support most Zynq and Zynq
UltraScale+ platforms.
You can read more about the new hardware build transformations
here.
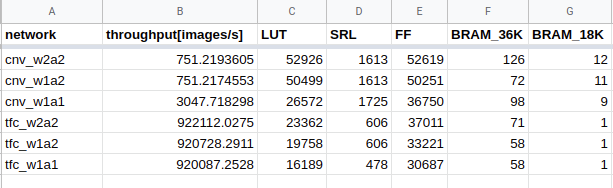
Fully-accelerated end-to-end examples + dashboard. The FINN end-to-end example networks are now fully accelerated on the FPGA, allowing raw images to be directly fed in and top-1 indices to be retrieved. We now also have a dashboard which gets automatically updated with the latest build results from end-to-end examples, including FPGA resources and performance. This also enables running full-performance accuracy validation on hardware, which is now incorporated into the end-to-end notebooks.
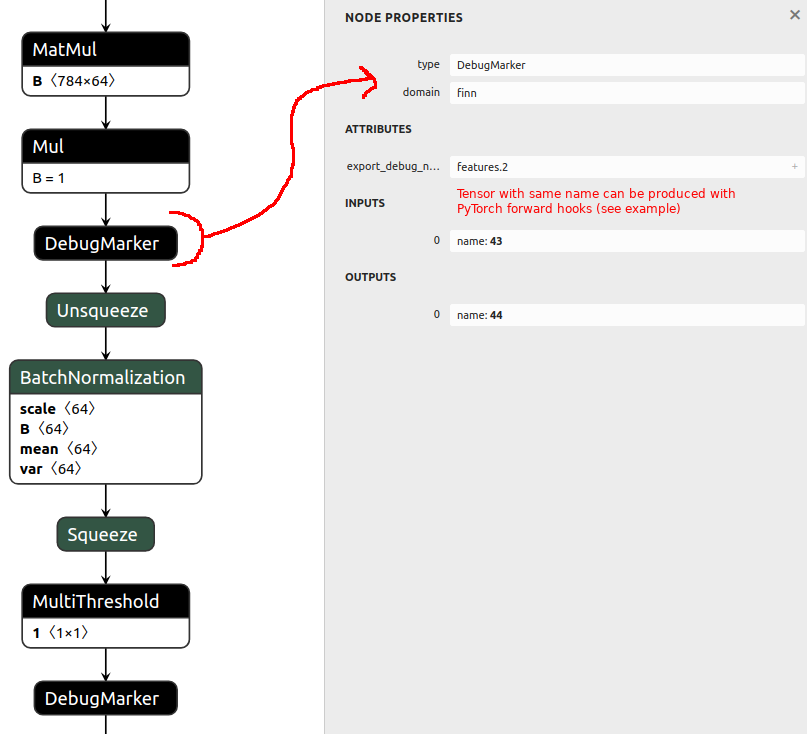
Brevitas-FINN co-debug support. We can now export graphs from Brevitas with special DebugMarker nodes (like above) and PyTorch forward hooks to compare intermediate activations between the Brevitas version and FINN-ONNX exported version. This is handy for debugging especially larger networks when they don’t export correctly. Here is an example of how to use this.
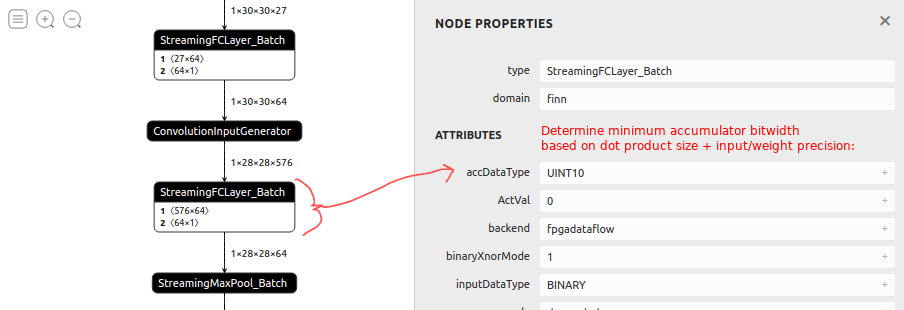
Accumulator minimization. When converting to HLS layers, FINN will now automatically try to pick a minimal bitwidth for each accumulator, based on the precision and size of the dot product it accumulates over. While prior accumulators were at a fixed bitwidth like 32-bits, the new approach can significantly save on resources by picking e.g. 10-bit accumulators (as per above) where possible. We’ve also expanded the range of DataTypes available in FINN to cover everything between 1-32 bits to provide more flexibility.
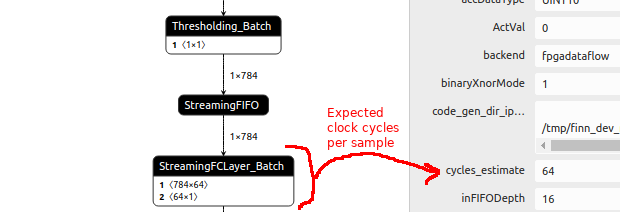
New layers and cycle estimation. We’ve been working on supporting more of the finn-hlslib layers in FINN and the list has expanded significantly. Many of these layers (and their accompanying conversion transformations) will be utilized for new FINN end-to-end example networks, like MobileNet-v1, ResNet-50 and a QuartzNet, over the course of the next few releases. These layers also support clock cycle estimation based on workload and parallelization parameters, allowing the user to estimate performance without having to go to synthesis.
The release (tagged 0.4b) is now available on GitHub. We’re continuously working to improve FINN in terms of layer, network and infrastructure. If you’d like to help out, please check out the contribution guidelines and share your ideas on the FINN Gitter channel!