Dataflow compiler for QNN inference on FPGAs
- About Us
- Quickstart
- Announcements
- Publications
- Events
- Community
- Developer Docs
- Videos
- Archive
- FINN Examples
- Brevitas
- HLS Library
- FINN compiler
This project is maintained by Xilinx
QONNX and FINN
03 Nov 2021 - Hendrik Borras, Yaman Umuroglu
As an open source exploration tool for FPGA dataflow architecutres, FINN was built with modularity in mind. And part of that philosophy is that FINN itself acts as a backend to a quantization aware training framework in the frontend. With the 0.7 release today, FINN is taking another step towards increasing the flexibility of the framework by supporting a new input format for neural networks. The new format is called QONNX (Quantized-ONNX) and is a dialect to standard ONNX. Similar to the FINN-ONNX dialect used within FINN, QONNX adds new operators, which make flexible quantization possible, while keeping other ONNX operators intact. QONNX was developed together in collaboration with Alessandro Pappalardo, the maintainer of Brevitas, and the hls4ml team.
But what even is QONNX?
Click on the image below to visualize the TFC-w1a2 model expressed in QONNX with Netron
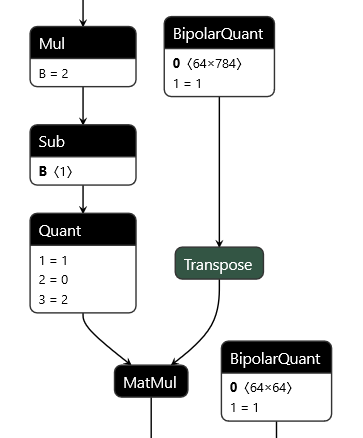
Today, the ONNX standard itself only supports down to 8-bit quantization, whereas QONNX supports expressing down to 1-bit quantization for both weights and activations. At its core QONNX is standard ONNX with three additional node types that enable flexible expression of quantized networks. These are the following:
- Quant
- This node provides basic quantization functionalities for bit widths down to 2-bit. It allows for scaled and zero-point shifted quantization schemes with different rounding modes.
- BipolarQuant
- The BipolarQuant node provides one-bit quantization support and its input parameters can be seen as a subset of those of the Quant node.
- Trunc
- The Trunc node represents a bit level truncation operation, where an integer number is truncated after a certain bit length. This node is as example used for the implementation of quantized global average pooling in QONNX.
Check out the ONNX-style documentation to get a better impression of how these nodes can be implemented in practice. To get a closer look at some QONNX models, check out the QONNX model zoo. Here the colleagues over at hls4ml and we have started to build a collection of QONNX models.
How will QONNX help FINN evolve?
In general, QONNX will enable FINN to be much more flexible in terms of representing weight and activation quantization, especially for higher precisions and fixed-point datatypes. For instance, this will enable future support for higher-precision quantized weights and activations, avoiding streamlining difficulties and expensive MultiThreshold-based activations. The other important thing enabled by QONNX is that with the help of the hls4ml team, FINN will be able to ingest models trained by QKeras in the near future. QKeras is built on top of TensorFlow and is similar to Brevitas in that it enables fine grained quantization aware training. Enabling the ingestion of models trained with QKeras will give users more options in choosing how to train their networks. In turn, this will also enable developers who prefer TensorFlow over PyTorch to also work with FINN.
Okay, how does one use QONNX then?
Both FINN and Brevitas come with all the tools needed to get started with QONNX in their most recent releases.
To export a QONNX model in Brevitas the flow is similar to how one would export a FINN network previously.
Simply use the BrevitasONNXManager instead of the FINNManager, all other syntax remains the same:
from brevitas.export.onnx.generic.manager import BrevitasONNXManager
BrevitasONNXManager.export(brevitas_model, input_shape, export_onnx_path)
Please be aware that due to the more flexible nature of QONNX, Brevitas may export additional inputs in certain scenarios with the new export. Alternatively, one can simply download one of the models from the QONNX model zoo.
On the FINN side things really depend on how one works with the network.
If one is using the DataFlow builder
then everything is already ready to go. Because with the new release of FINN the DataFlow builder includes
a new step called step_qonnx_to_finn, which will convert the supplied QONNX model to the FINN-ONNX dialect.
The build example of the new keyword spotting demo
actually makes use of this new build step and uses a QONNX file as input.
However, if one is using a custom build flow, similar to the one in the tfc_end2end_example notebook then one will need to add two steps at the beginning of the build flow. These steps are:
- Cleaning the QONNX model: This is essentially the equivalent of the tidy up transformations needed for FINN-ONNX.
from finn.core.modelwrapper import ModelWrapper from qonnx.util.cleanup import cleanup_model model = ModelWrapper(“QONNX_model.onnx”) model = cleanup_model(model) - Converting the model from the QONNX dialect to the FINN-ONNX dialect:
from finn.transformation.qonnx.convert_qonnx_to_finn import ConvertQONNXtoFINN model = model.transform(ConvertQONNXtoFINN())
In particular this second step is where most development around QONNX and FINN has been done in the past few months. And since the QONNX dialect can support much more quantization schemes than FINN does, this is also the point at which FINN will check the QONNX model for compatibility and inform the user if incompatible quantization types are found. If you’d like to get a deeper look as to how this conversion from QONNX to FINN works and what’s done under the hood, then we recommend checking out this presentation with status updates about the QONNX ingestion in FINN during development.
QONNX: enabling FINN-hls4ml collaboration
As a FINN user, you may have head of the hls4ml project: it is very similar to FINN, yet very different. At its core hls4ml aims to solve the same problem of bringing neural networks onto FPGAs, using generated HLS code, but the internals of the two frameworks are significantly different in terms of flows, layer support, where the optimizations are focused, and so on. If you’d like to get an impression of how hls4ml works, then we recommend to check out their tutorials or to take a look at their most recent publication.
Both FINN and hls4ml have significant active user bases, and although it’s not possible to merge the two frameworks at this time, we definitely want to see the two communities coming closer together. As a new, shared frontend for both FINN and hls4ml, we hope that QONNX will bring us closer to this goal and foster further collaboration between the two projects. We are already developing Python utilities to manipulate QONNX models in this new shared repo.
Summary
Initial support for the new QONNX format is already included with the 0.7 release of FINN today. This new input format allowed us to include a bunch of improvements with this release, along with making FINN easier to extend in the future.
A few concrete things to look forward to in the coming months are:
- Using QONNX to make exchange between Brevitas, QKeras, hls4ml and FINN possible.
- Synthesise models trained with QKeras with FINN
- Synthesise models trained with Brevitas with hls4ml
- Running the same QONNX model in both hsl4ml and FINN and having more choice in finding the best tool for the job.
- Splitting up a QONNX model to synthesize different portions with FINN and hls4ml.