Deploying a Model¶
Workflow for Deploying a Model¶
Once you have successfully quantized and compiled your model for a specific DPU, the next task is to deploy that model on the target. Follow these steps in this process:
Test your model and application software on one of the AMD platforms for which a pre-built DPU image is provided. Ideally, this would be the platform and DPU that closely matches your final production deployment.
Customize the AMD platform design with any substantive changes required to the DPU IP. Incorporate your final pipeline’s pre- or post-processing pipeline acceleration components. Retest your model.
Port the AMD platform design to your final target hardware platform. Retest your model.
The motivation for this multi-step process is to minimize the number of variables involved in the initial deployment. The process enables the developer to perform verification at each stage. This saves users many hours of frustration and troubleshooting.
In general, the workflow illustrated on the right-hand side of the following diagram is all that is required for the first two steps of deployment. Generally, the platform development component on the left-hand side of the diagram is only required for the third and final step. Part of the convenience of this is that the work can be partitioned between hardware developers and data science teams, enabling the hardware and data science teams to work in parallel, converging at the final step for the deployment on a custom hardware platform. The following image is representative for Vitis designs, but the ability to partition the effort is similar for Vivado designs. Refer to the user documentation for the Vivado and Vitis workflows for additional details of the hardware platform development workflow.
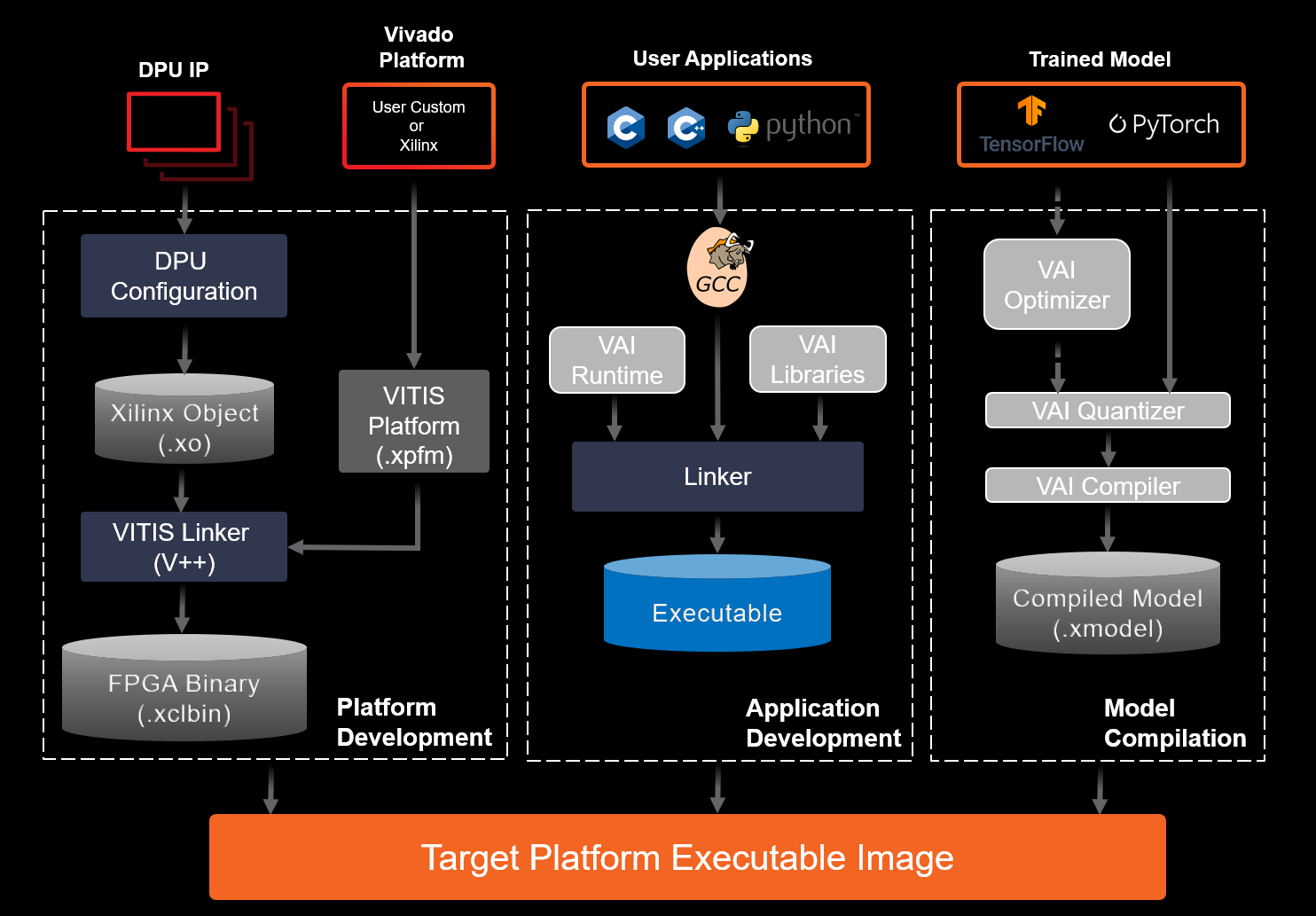
Simplified Vitis Workflow¶
Note
Not captured in this image is the PetaLinux workflow. In the context of AMD pre-built target board images, the goal is to enable the developer without requiring that they modify Linux. An important exception to this is for developers who are customizing hardware IPs and peripherals that reside within the memory space of the target CPU/APU and who wish to customize Linux. Also, in some circumstances, it is possible to directly install Vitis AI on the target without rebuilding the kernel image. Refer to Vitis AI Linux Recipes for additional information.
Embedded versus Data Center Workflows¶
The Vitis AI workflow is largely unified for Embedded and Data Center applications but diverges at the deployment stage. There are various reasons for this divergence, including the following:
Zynq™ Ultrascale+™, Kria™, and Versal™ SoC applications leverage the on-chip processor subsystem (APU) as the host control node for model deployment. Considering optimization and Whole Application Acceleration of subgraphs deployed on the SoC APU is crucial.
Alveo data center card deployments leverage the AMD64 architecture host for execution of subgraphs that cannot be deployed on the DPU.
Zynq Ultrascale+ and Kria designs can leverage the DPU with either the Vivado workflow or the Vitis workflow.
Zynq Ultrascale+ and Kria designs built in Vivado do not use XRT.
All Vitis designs require the use of XRT.
Vitis AI Library¶
The Vitis AI Library provides you with a head-start on model deployment. While it is possible for developers to directly leverage the Vitis AI Runtime APIs to deploy a model on AMD platforms, it is often more beneficial to start with a ready-made example that incorporates the various elements of a typical application, including:
Simplified CPU-based pre and post-processing implementations.
Vitis AI Runtime integration at an application level.
Ultimately most developers will choose one of two paths for production:
Directly leverage the VART APIs in their application code.
Leverage the VAI Library as a starting point to code their application.
An advantage of leveraging the Vitis AI Library is ease-of-use, while the potential downsides include losing yourself in code that wasn’t intended for your specific use case, and also a lack of recognition on the part of the developer that the pre- and post-processing implementations provided by the Vitis AI Library will not be optimized for Whole Application Acceleration.
If you prefer to use the Vitis AI Runtime APIs directly, the code examples provided in the Vitis AI Tutorials will offer an excellent starting point.
Vitis AI Runtime¶
The Vitis AI Runtime (VART) is a set of API functions that support the integration of the DPU into software applications. VART provides a unified high-level runtime for both Data Center and Embedded targets. Key features of the Vitis AI Runtime API are:
Asynchronous submission of jobs to the DPU.
Asynchronous collection of jobs from the DPU.
C++ and Python API implementations.
Support for multi-threading and multi-process execution.
For more information on Vitis AI Runtime, refer to the following documentation:
For the Vitis AI Runtime API reference, see VART Programming APIs and Deploying and Running the Model in the Vitis AI User Guide.
A quick-start example to assist you in deploying VART on embedded devices is available here.
The Vitis AI Runtime is also provided as open-source.
Whole Application Acceleration¶
It is typical in machine learning applications to require some degree of pre-processing, such as illustrated in the following example:

Simplified CNN Pre-Processing Pipeline¶
In addition, many real-world applications for machine learning do not simply employ a single machine-learning model. It is common to cascade multiple object detection networks as a precursor to a final stage (for example, classification, OCR). Throughout this pipeline, the metadata must be time-stamped or attached to the buffer address of the associated frame. Pixels bounded by ROI (Region-of-Interest) predictions are cropped from the associated frame. Each of these cropped sub-frame images is then scaled such that the X/Y dimensions of the crop match the input layer dimensions of the downstream network. Some pipelines, such as ReID, will localize, crop, and scale ten or more ROIs from every frame. Each of these crops may require a different scaling factor to match the input dimensions of the downstream model in the pipeline. An example:

Typical Cascaded CNN Pre-Processing Pipeline¶
These pre-, intermediate, and post-processing operations can significantly impact the overall efficiency of the end-to-end application. This makes “Whole Application Acceleration” or WAA a very important aspect of AMD machine learning solutions. All developers leveraging AMD adaptable devices for high-performance machine learning applications should learn and understand the benefits of WAA. An excellent starting point for this can be found here.
Explore the relevance and capabilities of AMD Vitis Video Analytics (VVAS) SDK, which, while not part of Vitis AI, offers many important features for developing end-to-end video analytics pipelines that employ multi-stage (cascaded) AI pipelines. VVAS also applies to designs that leverage video decoding, transcoding, RTSP streaming, and CMOS sensor interfaces. Another important differentiator of VVAS is that it directly enables software developers to leverage GStreamer commands to interact with the video pipeline.
Vitis AI Profiler¶
The Vitis AI Profiler is a set of tools that enables you to profile and visualize AI applications based on VART. The Vitis AI Profiler is easy to use as it can be enabled post-deployment and requires no code changes. Specifically, the Vitis AI Profiler supports profiling and visualization of machine learning pipelines deployed on Embedded targets with the Vitis AI Runtime. In a typical machine learning pipeline we find neural network operations that can be accelerated on the DPU, as well as functions such as pre-processing or custom operators that are not supported by the DPU. These additional functions may be implemented as a C/C++ kernel or accelerated using Whole-Application Acceleration or customized RTL. Using the Vitis AI Profiler is critical for developers to optimize the entire inference pipeline iteratively. The Vitis AI Profiler lets the developer visualize and analyze the system and graph-level performance bottlenecks.
The Vitis AI Profiler is a component of the Vitis AI toolchain installed in the VAI Docker. The Source code is not provided.
For more information on Vitis AI Profiler see the Profiling the Model section in the Vitis AI User Guide.
Examples and additional detail for the Vitis AI Profiler can be found here.
A tutorial that provides additional insights on the capabilities of the Vitis AI Profiler is available here.