Vitis AI¶
AMD Vitis™ AI is an integrated development environment that can be leveraged to accelerate AI inference on AMD platforms. This toolchain provides optimized IP, tools, libraries, models, as well as resources, such as example designs and tutorials that aid the user throughout the development process. It is designed with high efficiency and ease-of-use in mind, unleashing the full potential of AI acceleration on AMD Adaptable SoCs and Alveo Data Center accelerator cards.
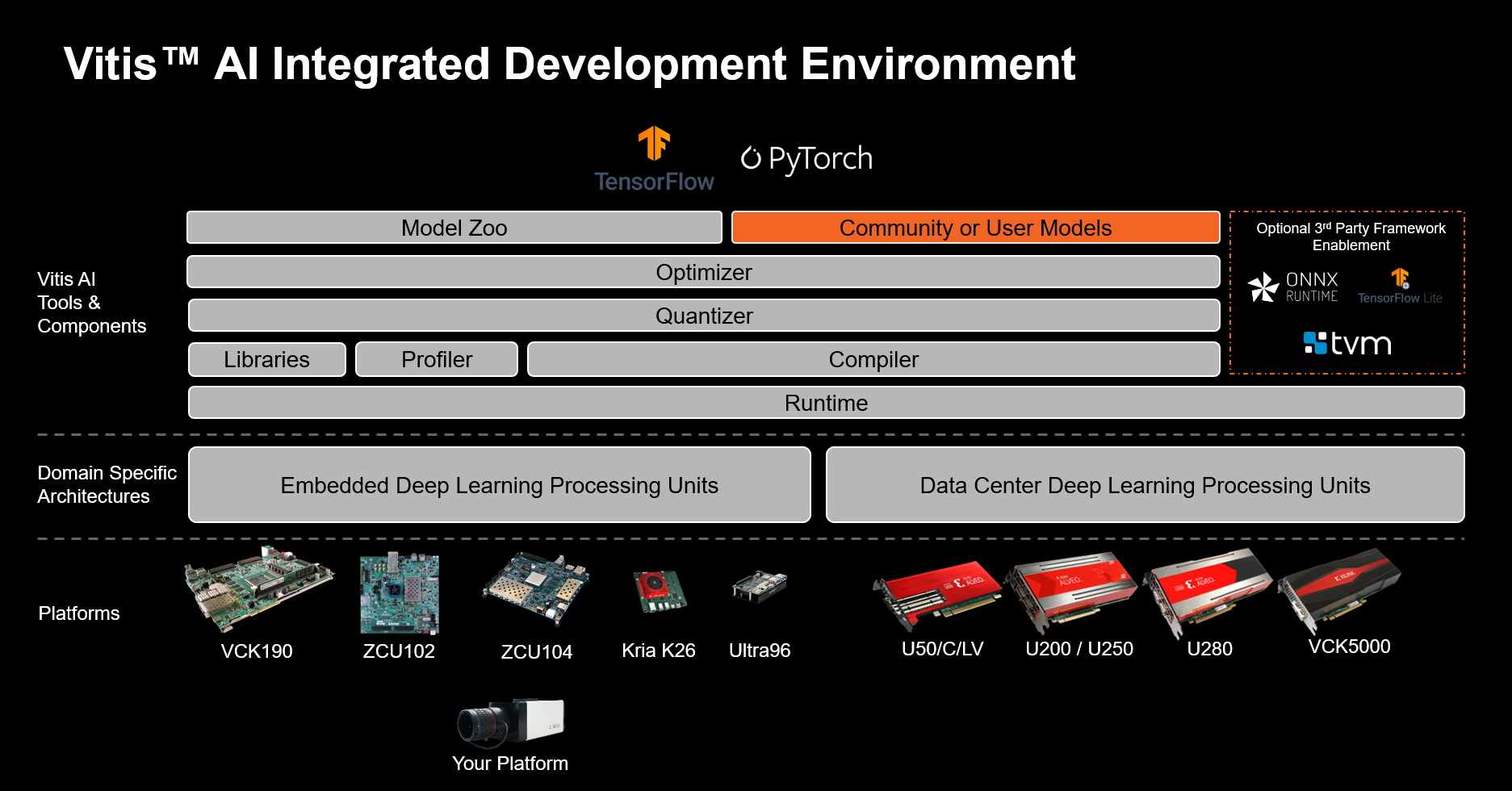
Vitis AI Integrated Development Environment Block Diagram¶
The Vitis™ AI solution consists of three primary components:
The Deep-Learning Processor unit (DPU), a hardware engine for optimized the inferencing of ML models
Model development tools, to compile and optimize ML models for the DPU
Model deployment libraries and APIs, to integrate and execute the ML models on the DPU engine from a SW application
The Vitis AI solution is packaged and delivered as follows:
AMD open download: pre-built target images integrating the DPU
Vitis AI docker containers: model development tools
Vitis AI github repository: model deployment libraries, setup scripts, examples and reference designs
Vitis AI Key Components¶
Deep-Learning Processor Unit¶
The Deep-learning Processor Unit (DPU) is a programmable engine optimized for deep neural networks. The DPU implements an efficient tensor-level instruction set designed to support and accelerate various popular convolutional neural networks, such as VGG, ResNet, GoogLeNet, YOLO, SSD, and MobileNet, among others.
The DPU supports on AMD Zynq™ UltraScale+™ MPSoCs, the Kria™ KV260, Versal™ and Alveo cards. It scales to meet the requirements of many diverse applications in terms of throughput, latency, scalability, and power.
AMD provides pre-built platforms integrating the DPU engine for both edge and data-center cards. These pre-built platforms allow data-scientists to start developping and testing their models without any need for HW development expertise.
For embedded applications, the DPU needs to be integrated in a custom platform along with the other programmable logic functions going in the FPGA or adaptive SoC device. HW designers can integrate the DPU in a custom platform using either the Vitis flow or the Vivado™ Design Suite.
Model Development¶
Vitis AI Model Zoo¶
The Vitis AI Model Zoo includes optimized deep learning models to speed up the deployment of deep learning inference on adaptable AMD platforms. These models cover different applications, including ADAS/AD, video surveillance, robotics, and data center. You can get started with these pre-trained models to enjoy the benefits of deep learning acceleration.
Vitis AI Model Inspector¶
The Vitis AI Model Inspector is used to perform initial sanity checks to confirm that the operators and sequence of operators in the graph is compatible with Vitis AI. Novel neural network architectures, operators, and activation types are constantly being developed and optimized for prediction accuracy and performance. Vitis AI provides mechanisms to leverage operators that are not natively supported by your specific DPU target.
Vitis AI Optimizer¶
The Vitis AI Optimizer exploits the notion of sparsity to reduce the overall computational complexity for inference by 5x to 50x with minimal accuracy degradation. Many deep neural network topologies employ significant levels of redundancy. This is particularly true when the network backbone is optimized for prediction accuracy with training datasets supporting many classes. In many cases, this redundancy can be reduced by “pruning” some of the operations out of the graph.
Vitis AI Quantizer¶
The Vitis AI Quantizer, integrated as a component of either TensorFlow or PyTorch, converts 32-bit floating-point weights and activations to fixed-point integers like INT8 to reduce the computing complexity without losing prediction accuracy. The fixed-point network model requires less memory bandwidth and provides faster speed and higher power efficiency than the floating-point model.
Vitis AI Compiler¶
The Vitis AI Compiler maps the AI quantized model to a highly-efficient instruction set and dataflow model. The compiler performs multiple optimizations; for example, batch normalization operations are fused with convolution when the convolution operator precedes the normalization operator. As the DPU supports multiple dimensions of parallelism, efficient instruction scheduling is key to exploiting the inherent parallelism and potential for data reuse in the graph. The Vitis AI Compiler addresses such optimizations.
Model Deployment¶
Vitis AI Runtime¶
The Vitis AI Runtime (VART) is a set of low-level API functions that support the integration of the DPU into software applications. VART is built on top of the Xilinx Runtime (XRT) amd provides a unified high-level runtime for both Data Center and Embedded targets. Key features of the Vitis AI Runtime API include:
Asynchronous submission of jobs to the DPU.
Asynchronous collection of jobs from the DPU.
C++ and Python API implementations.
Support for multi-threading and multi-process execution.
Vitis AI Library¶
The Vitis AI Library is a set of high-level libraries and APIs built on top of the Vitis AI Runtime (VART). The higher-level APIs included in the Vitis AI Library give developers a head-start on model deployment. While it is possible for developers to directly leverage the Vitis AI Runtime APIs to deploy a model on AMD platforms, it is often more beneficial to start with a ready-made example that incorporates the various elements of a typical application, including:
Simplified CPU-based pre and post-processing implementations.
Vitis AI Runtime integration at an application level.
Vitis AI Profiler¶
The Vitis AI Profiler profiles and visualizes AI applications to find bottlenecks and allocates computing resources among different devices. It is easy to use and requires no code changes. It can trace function calls and run time, and also collect hardware information, including CPU, DPU, and memory utilization.