Internal Design of Connected Component¶
Overview¶
In graph theory, a component, sometimes called a connected component, of an undirected graph is a subgraph in which any two vertices are connected to each other by paths, and which is connected to no additional vertices in the supergraph (from wikipedia). The API will compute the (weakly) connected component (CC) of each vertex and return a graph with the vertex value containing the lowest vertex id in the CC containing that vertex.
Algorithm¶
The implemented Connected Component is based on Breadth-first Search graph traversal equiped with one First-In-First-Out queue. The pseduo-code is shown as below:
procedure ConnectedComponent(graph_CSR)
grpah_CSC := csr2csc(graph_CSR)
for each vertex v in graph
result(v) := -1
result(0) := 1
push node 0 into Queue
while all vertexs have been labeled
while Queue is not empty
u := pop Queue
for each edge(u, v) in both graph_CSR and graph_CSC
if result(v) == -1 then
result(v) := u + 1
push v into Queue
end if
end for
end while
newRoot := findNewRoot(result)
push root node into Queue
end while
return result
Here, connected component will get all indegree and outdegree of each u when the input graph is directed. As a result, one addition csr2csc operation is required at the begining.
Interface¶
The input should be a directed/undirected graph in compressed sparse row (CSR) format. The result will return a vertex list with each vertex value containing the lowest vertex id in the CC.
Implemention¶
The detail algorithm implemention is illustrated as below:
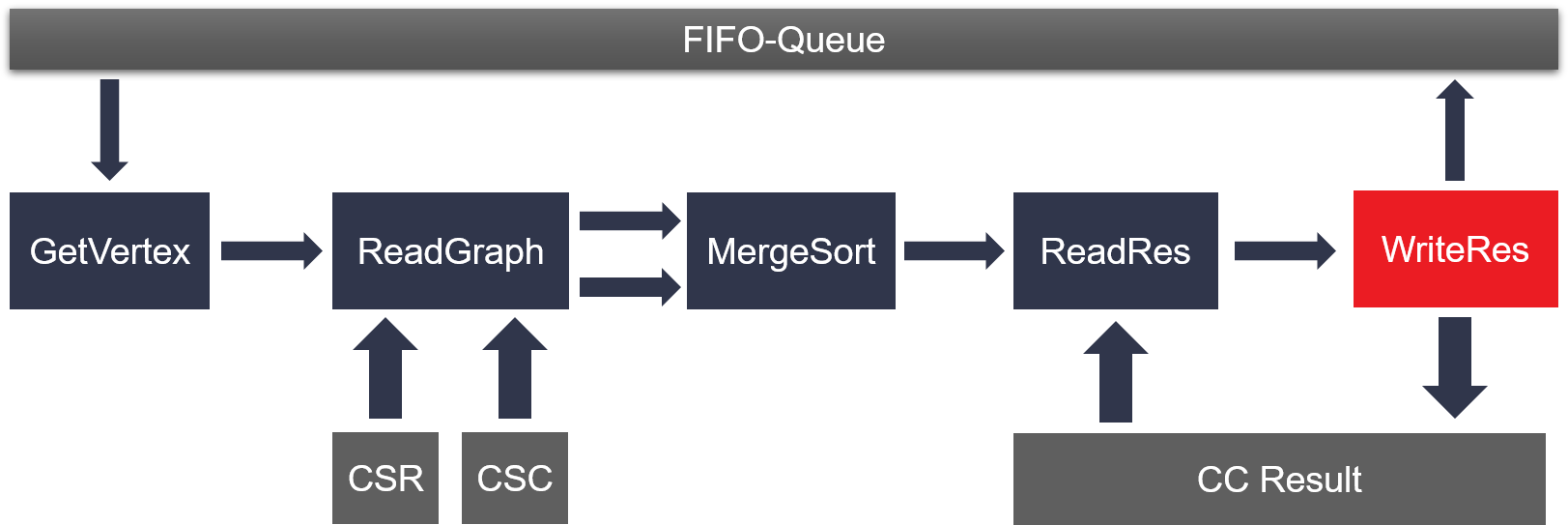
The overall diagram of this kernel is mostly same as BFS kernel except for extra input CSC graph and one mergeSort module. The mergeSort will merge and output one sorted stream for two input indegree and outdegree sorted stream. And the duplicate vertex in the single sorted output stream will be removed before entering the readRes module.
Profiling and Benchmarks¶
The connected component is validated on Alveo U250 board at 280MHz frequency. The hardware resource utilization and benchmark results are shown in the two table below.
| Name | LUT | BRAM | URAM | DSP |
| Platform | 104112 | 165 | 0 | 4 |
| wcc_kernel | 103923 | 387 | 112 | 3 |
| Total | 208035 (12%) | 552 (21%) | 112 (9%) | 7 (0%) |
| Datasets | Vertex | Edges | FPGA Time | Spark (4 threads) | Spark (8 threads) | Spark (16 threads) | Spark (32 threads) | ||||
| Spark Time | Speed up | Spark Time | Speed up | Spark Time | Speed up | Spark Time | Speed up | ||||
| as-Skitter | 1696415 | 11095298 | 3401 | 27063 | 7.96 | 18195 | 5.35 | 16382 | 4.82 | 20490 | 6.02 |
| coPapersDBLP | 540486 | 15245729 | 1958 | 24109 | 12.31 | 17997 | 9.19 | 13723 | 7.01 | 17136 | 8.75 |
| coPapersCiteseer | 434102 | 16036720 | 1811 | 24020 | 13.26 | 20516 | 11.33 | 14546 | 8.03 | 18863 | 10.42 |
| cit-Patents | 3774768 | 16518948 | 16365 | 58366 | 3.57 | 42697 | 2.61 | 34405 | 2.10 | 34862 | 2.13 |
| hollywood | 1139905 | 57515616 | 7887 | 60888 | 7.72 | 41505 | 5.26 | 34689 | 4.40 | 31272 | 3.97 |
| soc-LiveJournal1 | 4847571 | 68993773 | 30519 | 116193 | 3.81 | 91749 | 3.01 | 59977 | 1.97 | 67258 | 2.20 |
| ljournal-2008 | 5363260 | 79023142 | 24334 | 144183 | 5.93 | 102186 | 4.20 | 74971 | 3.08 | 87338 | 3.59 |
| GEOMEAN | 7347.43 | 51284.68 | 6.98X | 37865.87 | 5.15X | 29071.30 | 3.96X | 32977.43 | 4.49X | ||
Note