xclbin timing closure tips¶
Overview¶
The two main timing issues you may encounter would be in the power and GT_MAC CUs. To solve them, some pblock are needed and potentially an update of Vivado default strategy.
These can be done by adding some configurations into your Vitis options file: vpp.ini:
pblock: Use a TCL file.
strategy: Vivado property.
Here is an example:
[vivado]
prop=run.impl_1.STEPS.PLACE_DESIGN.TCL.PRE=../../vpp_cfg/place_design_pre.tcl
prop=run.impl_1.strategy=Performance_EarlyBlockPlacement
prop=run.impl_1.STEPS.POST_ROUTE_PHYS_OPT_DESIGN.IS_ENABLED=true
prop=run.impl_1.STEPS.ROUTE_DESIGN.ARGS.DIRECTIVE=Explore
prop=run.impl_1.STEPS.POST_ROUTE_PHYS_OPT_DESIGN.ARGS.DIRECTIVE=Explore
prop=run.impl_1.STEPS.PHYS_OPT_DESIGN.ARGS.DIRECTIVE=Explore
prop=run.impl_1.STEPS.PHYS_OPT_DESIGN.IS_ENABLED=true
Run multi-strategy on LSF¶
If the above options are not enough to close timing, you can also try to run multiple strategies over a cluster:
Use
__ALL_IMPL__macro to apply some settings to all runs.Use
multiStrategiesWaitOnAllRunsto see the result of all strategies.
Seeing all results will give you an indication on how hard it is to close timing for the tool.
[advanced]
#param=compiler.multiStrategiesWaitOnAllRuns=1
## only for vivado >=2022.1
#param=compiler.errorOnPulseWidthViolation=false
[vivado]
impl.lsf={bsub -R "select[(type==X86_64) && (osdistro=rhel || osdistro=centos) && (osver == ws7) && (ossp > 3)] rusage[mem=48000]" -N -q long -W 48:00}
impl.strategies=ALL
prop=run.__ALL_IMPL__.STEPS.PLACE_DESIGN.TCL.PRE=../../vpp_cfg/place_design_pre.tcl
prop=run.__ALL_IMPL__.STEPS.ROUTE_DESIGN.TCL.PRE=../../vpp_cfg/route_design_pre.tcl
prop=run.__ALL_IMPL__.STEPS.POST_ROUTE_PHYS_OPT_DESIGN.IS_ENABLED=true
prop=run.__ALL_IMPL__.STEPS.ROUTE_DESIGN.ARGS.DIRECTIVE=Explore
prop=run.__ALL_IMPL__.STEPS.POST_ROUTE_PHYS_OPT_DESIGN.ARGS.DIRECTIVE=Explore
prop=run.__ALL_IMPL__.STEPS.PHYS_OPT_DESIGN.ARGS.DIRECTIVE=Explore
prop=run.__ALL_IMPL__.STEPS.PHYS_OPT_DESIGN.IS_ENABLED=true
Note
With vivado 2022.1 (or more recent) and only in multi-strategy, pulse violation timing violation are not ignored. This is a different behaviour compared to a single strategy build. Pulse timing violations in the power CU can be safely ignored.
Power CU¶
Although the power CU constraints all FF, DSP, BRAM and URAM, timing closure is not always achieved.
This could happen if CLOCK_LOW_FANOUT constraint set for the clk_throttling block of the power CU is ignored.
You may have a setup violation between the FF
Gate_Fast_d1and theCEpin ofFCLK(BUFGCE_DIV).
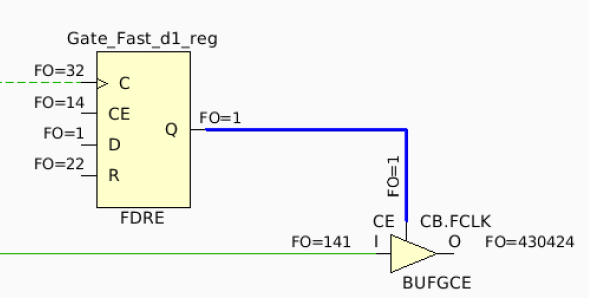
Clock throttling BUFGCE_DIV¶
In this case, we can emulate the effect of CLOCK_LOW_FANOUT constraint by creating a pblock and assigning the power CU clock throttle block.
In place_design_pre.tcl, you can add the following constraints (update pblock according to your design).
Use the same pblock in which you can find GC.FCLK clock buffer of the UCS IP.
create_pblock pwr_SLR0_clk_throttle
resize_pblock pwr_SLR0_clk_throttle -add CLOCKREGION_X4Y0:CLOCKREGION_X4Y0
add_cells_to_pblock -quiet pwr_SLR0_clk_throttle [get_cells -hierarchical -filter {NAME =~ level0_i/ulp/krnl_powertest_slr0_1/*/pwr_ctrl.clk_throttle/*}]
Here is how to locate the clock buffer:

Clock throttling BUFGCE_DIV¶
Tip
It is also recommended to cascade the power CU if you’ve got multiple of them. So only 1 power CU will contain the throttling logic.
GT_MAC CU¶
The GT_MAC CU is mainly composed by the xxv_ethernet, which is a huge IP (without the RS-FEC it’s still 75k FF and 63k LUT, and a limited quantity of RAMB36).
There are numerous paths with more than 8 levels of logic/routing.
Although most of the DRP logic is running at relatively low frequency 75MHz, giving too much room for the xxv_ethernet, design could not meet timing.
E.g.
system clock: rxoutclk_out[0]_9; slack: -0.118 ns
Pblock usage¶
Do not let Vivado use the entire SLR and freely place the xxv_ethernet IP.
Use pblock to squeeze instances of xxv_ethernet.
Here are 2 examples of how to pblock 1 or 2 instances of xxv_ethernet
When creating the pblock, don’t be afraid to increase the CLBL/CLBM utilization to 80-85%.
Example: u50 GT_MAC CU: 1 xxv_ethernet pblock
# Create pblock for krnl_gt_mac_test0_1
create_pblock gt_krnl0
resize_pblock [get_pblocks gt_krnl0] -add {CLOCKREGION_X0Y6:CLOCKREGION_X5Y7}
add_cells_to_pblock -quiet [get_pblocks gt_krnl0] [get_cells -hierarchical -filter {NAME =~ level0_i/ulp/krnl_gt_mac_test0_1/*/mac_wrapper/gty_4lanes.xxv_ip.mac/*}]
Example: u55c GT_MAC CU: 2 xxv_ethernet pblocks
# Create pblock for krnl_gt_mac_test0_1
create_pblock gt_krnl0
resize_pblock [get_pblocks gt_krnl0] -add {CLOCKREGION_X0Y4:CLOCKREGION_X6Y6}
add_cells_to_pblock -quiet [get_pblocks gt_krnl0] [get_cells -hierarchical -filter {NAME =~ level0_i/ulp/krnl_gt_mac_test0_1/*/mac_wrapper/gty_4lanes.xxv_ip.mac/*}]
# Create pblock for krnl_gt_mac_test1_1
create_pblock gt_krnl1
resize_pblock [get_pblocks gt_krnl1] -add {CLOCKREGION_X0Y5:CLOCKREGION_X6Y7}
add_cells_to_pblock -quiet [get_pblocks gt_krnl1] [get_cells -hierarchical -filter {NAME =~ level0_i/ulp/krnl_gt_mac_test1_1/*/mac_wrapper/gty_4lanes.xxv_ip.mac/*}]
Note
The two pblocks overlap as the GT transceivers are located close to each other on the die and the CLBL/CLBM utilization is at ~ 75%

GT pblock overlap¶
Force LOC of BRAM¶
Unless you use incremental compilation with Vitis™, you can try the following to extract some guidelines from a passing timing project and feeding them into the failing on. You don’t need to extract the location of each FF, the BRAM forces already a decent repetition of the P&R.
Only GT BRAMs¶
Try first to close timing with only the GT (and maybe with the other CU present in the SLR, e.g. DDR). From the timing closed project:
Step |
Example |
|---|---|
Open the DCP. |
|
Find current BRAM locations.
Only search for |
show_objects -name find_1 [get_cells -hierarchical -filter { PRIMITIVE_TYPE =~ BLOCKRAM.*.* && NAME =~ "*inst_krnl_core/inst_gt_test_top/*mac*" } ]
|
In the search result window
|
|
In TCL console: |
write_xdc -exclude_timing mac_bram.xdc
|
Extract BRAM locations from |
|
Add these locations in |
All ULP BRAMs¶
If only fixing location of GT BRAMs is still not working you need to use a more complex approach to reach timing closure:
Step |
Description |
|---|---|
Try to insert ALL CUs but reduce the utilization of the power CU to 1% DSP per SLR. |
The idea is to have the infrastructure in place (mem-SS, hbm-SS, AXI ….) without the putting any extra pressure on the tool with a power CU. |
Build with multi-strategy. |
Maybe use |
From a successful strategy (frequently |
|
Build the power CU around all these LOC BRAM/DSP. |
|
Build in multi strategy again. |
This time, comment |
Frequency override¶
To help timing closure, the frequency of the CU clocks can be overwritten setting the following parameters in wizard_config.json.
Parameter |
Range |
Default |
Description |
|---|---|---|---|
|
[200;500] |
300 MHz |
This parameter defines the frequency (in MHz) of
|
|
[200;500] |
500 MHz |
This parameter defines the frequency (in MHz) of
|
Enable clock scaling¶
If the frequency override is not enough, clock scaling may be enabled.
Vitis™ linker run as part of xclbin_generate workflow is set to disable auto scaling by default. This way the xclbin generation will fail when timing is not met.
This is done by setting the following Vitis command line option to false:
compiler.enableAutoFrequencyScaling
If timing is not met, the xclbin_generate workflow will fail.
If you then decide that you are happy with a timing failure, you can add the following option to your run (not recommended).
compiler.skipTimingCheckAndFrequencyScaling
Warning
If actual frequency of ap_clk and configured frequency (cu_configuration.clock.0.freq) are different, BW and latency measurements reported by xbtest are not accurate.